[LG]《A Bitter Lesson for Data Filtering》C Mohri, J Duchi, T Hashimoto [Stanford University] (2026)
在预训练数据筛选领域,“保留高质量文本”是一个被默认接受的难题。过去的方法受困于小算力下的筛选收益,本质原因是把短期训练效率误认成了数据的最终价值。
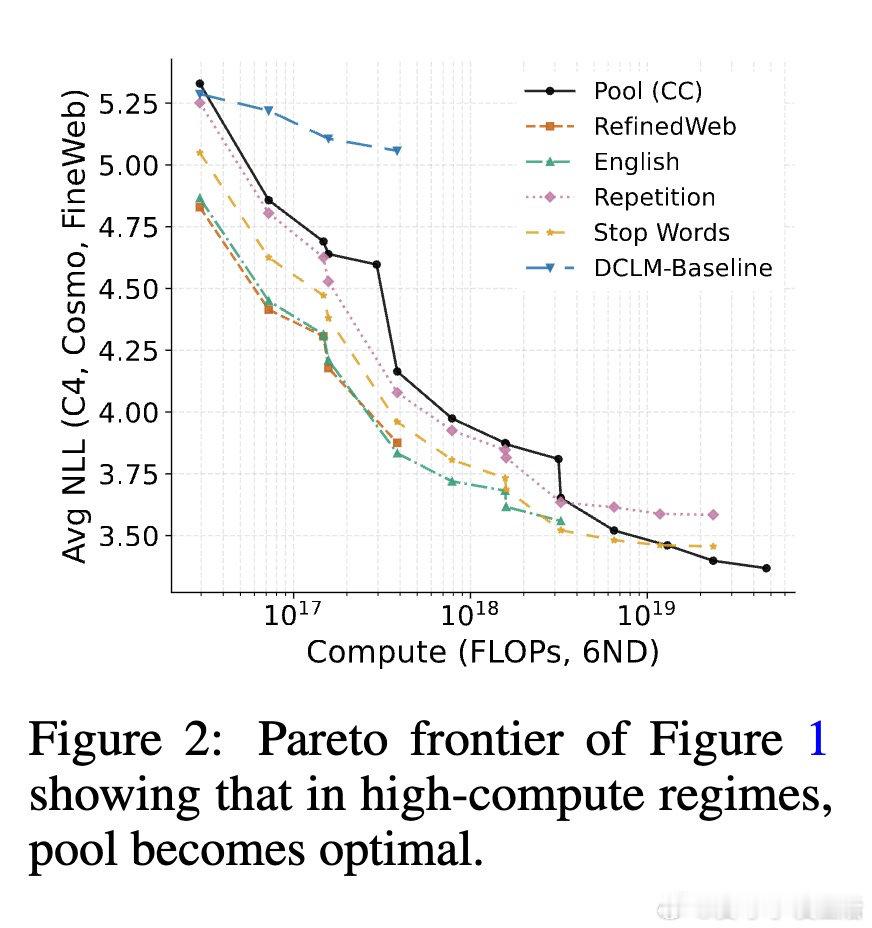
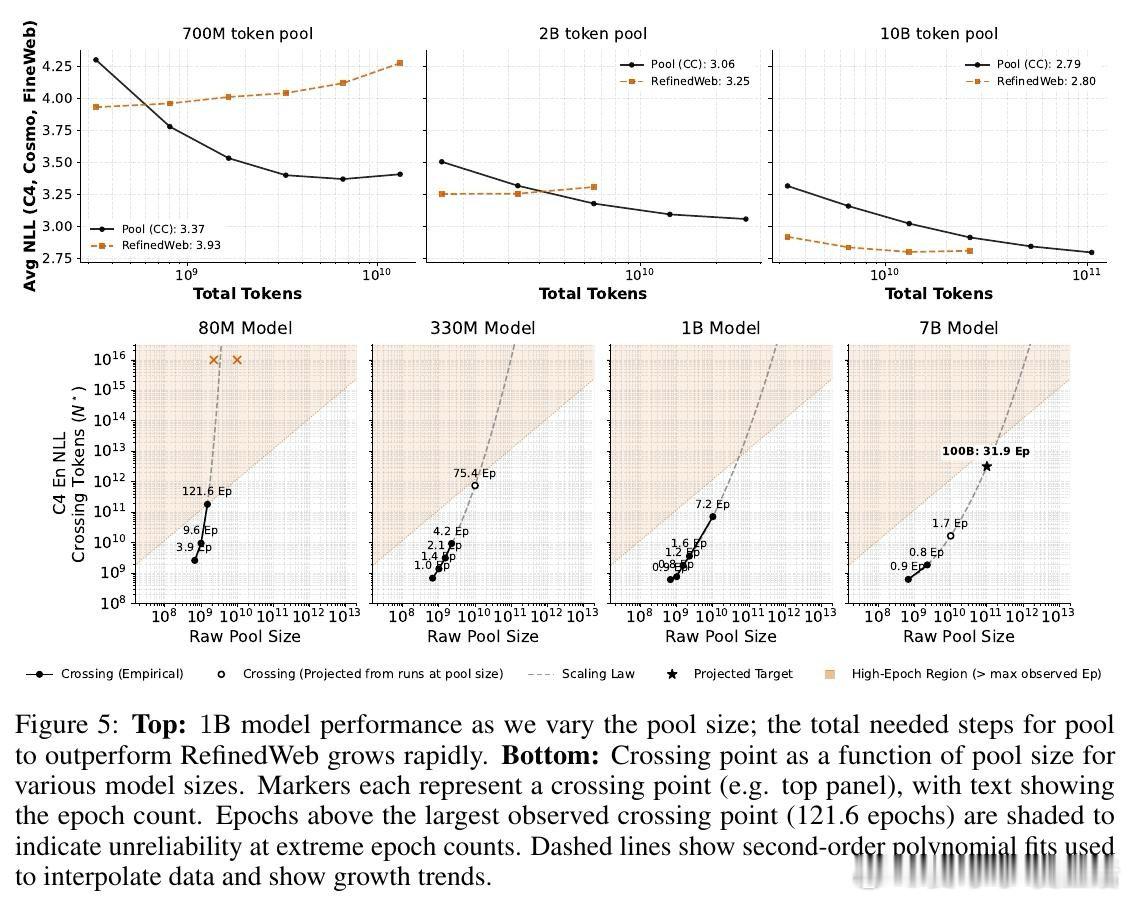
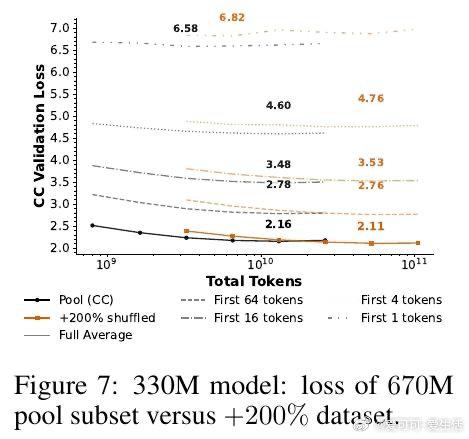
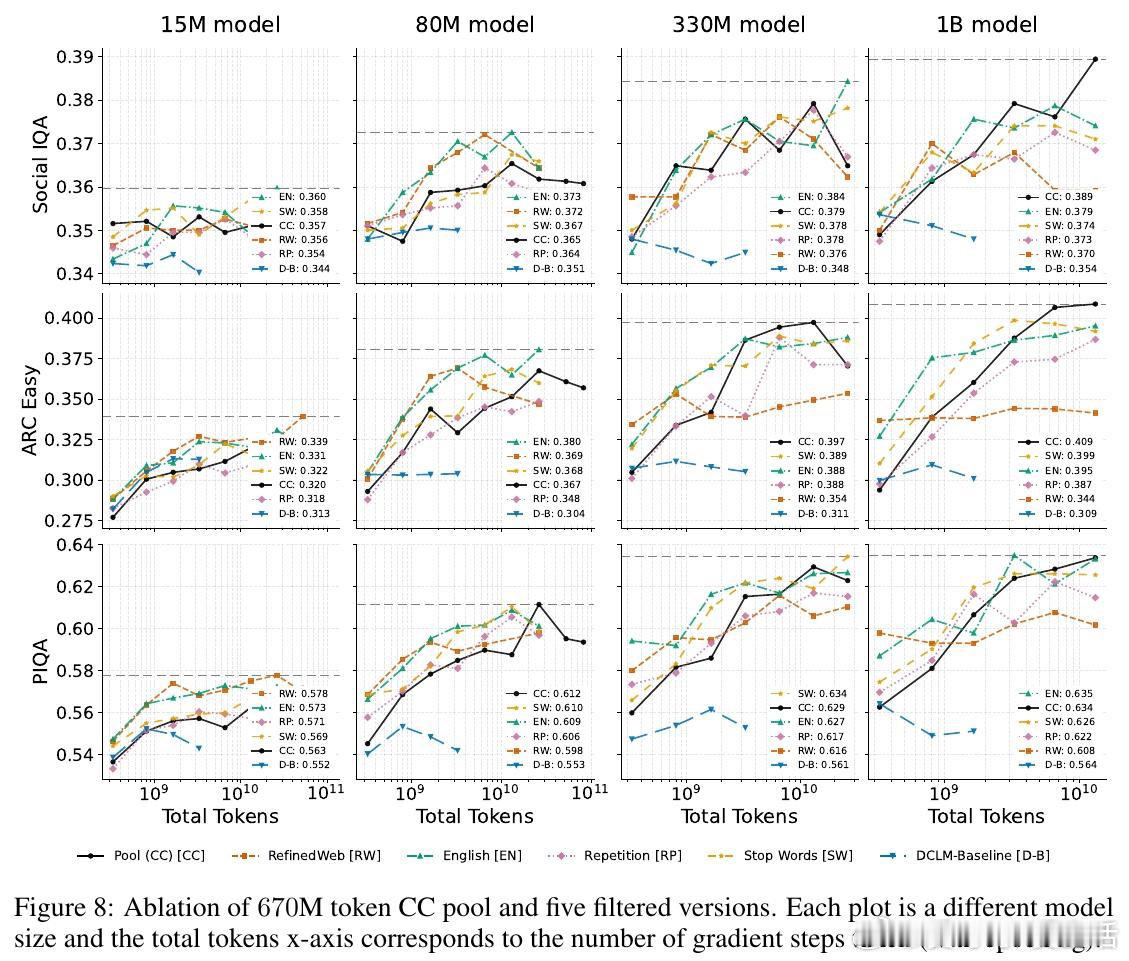
本文的核心洞见是:把脏数据重新看作可被大模型容量吸收的弱信号。由此,在模型足够大、训练足够久时直接使用完整 Common Crawl,使低质文本不再只是噪声。
这项工作真正留下的遗产是把数据过滤从“越干净越好”改写为“算力决定边界”。它为后来者打开的新门是按规模重新设计数据策略,但尚未跨过的门槛是真假混杂内容仍可能教错事实。
arxiv.org/abs/2605.19407 机器学习 人工智能 论文 AI创造营