这篇文章很硬,可以让你清晰了解 AI Agent 的设计理念演进路线及核心的变革驱动力!值得细细品读
2026 年 6 月 19 日,黄仁勋接受采访时说了一句话:「Nobody writes prompts anymore. The new job is to write and handle loops.」同一天,Claude Code 负责人 Boris Cherny 在 X 上写道:「I don't prompt Claude anymore. I have loops running that prompt Claude. My job is to write loops.」 190 万人已经读过 Addy Osmani 的《Loop Engineering》文章。 不是 prompt 不重要了,而是发 prompt 的那个人正在被系统替代。
 引子:两句话,一个方向
引子:两句话,一个方向2023 年,写 prompt 是被六位数年薪追逐的技能。「Prompt Engineer」是求职平台上的独立职位。你需要在几十个 token 的预算内,把模糊的需求翻译成模型能精确理解的指令。一篇好的 prompt 甚至可以卖出上千美元——当年确实有人这么干过。
2026 年 6 月,风向变了。两条推文从不同角度指向同一个结论。
第一条来自黄仁勋:「Nobody writes prompts anymore. The new job is to write and handle loops.」第二条来自 Boris Cherny——做 Claude Code 的那个人——说得更具体:「I don't prompt Claude anymore. I have loops running that prompt Claude and figuring out what to do. My job is to write loops.」
Peter Steinberger 补充:「你不应该再亲自给 coding agent 发 prompt 了。你应该设计 loops,让 loop 去发 prompt。」
这三个人在同一天、从不同角度指向同一个方向,不是某个 KOL 的个人观点——是一次行业共识的集中爆发。
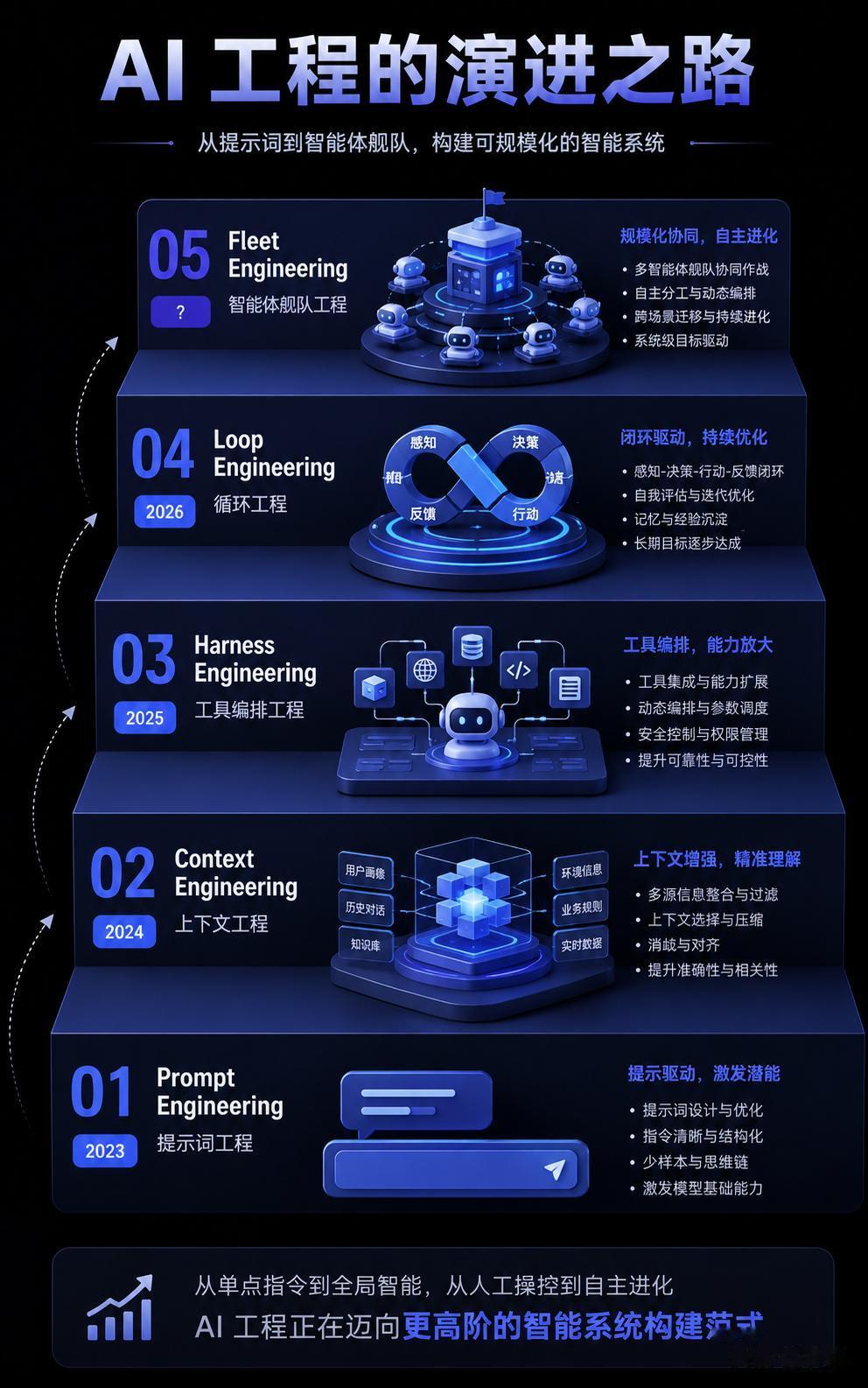
本文尝试把一条完整的脉络讲清楚:从 Prompt Engineering 开始,经历了 Context Engineering、Harness Engineering,到现在最新的 Loop Engineering——每一步都是上一阶段的核心瓶颈被推到极限之后的结果。
一、Prompt Engineering——被精炼逼到极限信息压缩的最优解大语言模型最初是以最朴素的形式展示在开发者面前的——一个空白的输入框和一个发送按钮。你说什么,它回什么。
你把任务描述清楚,附上示例、约束条件和输出格式。漏掉一个细节,模型就给你一个完全跑不通的答案。
所以 prompt engineering 的本质是一个信息压缩问题:如何在极少的 token 内表达足够精确的意图?
一系列技巧就此诞生:Chain-of-Thought(思维链)让模型把推理过程写出来,Few-shot(少样本)在 prompt 里嵌入几个输入输出示例,Role-playing(角色设定)给模型分配一个专业身份。这些技巧把模型的输出从「抛硬币」质量提升到了「可以上生产环境」的质量。
2023 年最活跃的那批 prompt engineer 们,本质上做了一件事:把模糊的商业需求翻译成模型能精确理解的语言。 这是一个价值巨大的接口层工作。
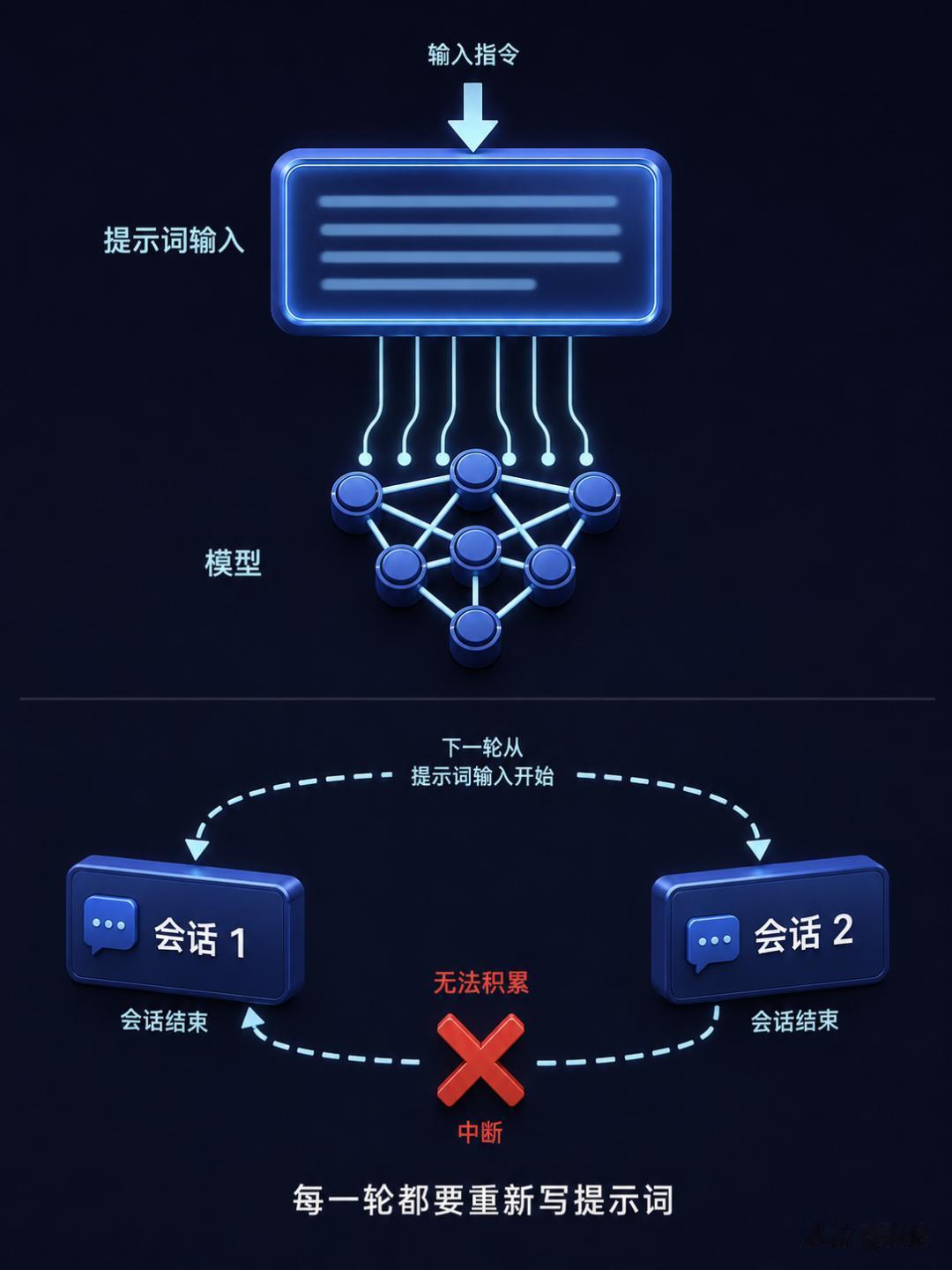
瓶颈:每一轮都从零开始但 Prompt Engineering 有一个无法扩展的核心缺陷:每次对话都需要一次新的 prompt 设计。
你和模型聊完一次、改好了一段代码,下一次遇到类似的需求,你还是得重新写一段 prompt。没有积累,没有复用。你花了一小时精炼的那段 prompt,关掉 session 之后就永远消失了。
更致命的是,上下文窗口从 4K 扩展到 128K、1M token 之后,矛盾变得更加尖锐——能塞进去的东西多了,但 prompt 只是一个指令载体。项目级别的知识和经验装不进去。
你在一个对话里跟模型聊了 50 轮,它已经了解你的项目。新开一个 session,它又回到了那个什么都不知道的状态。
Prompt Engineering 的瓶颈,催生了下一个概念。
 二、Context Engineering——窗口大了,管理更难了窗口不是越大越好
二、Context Engineering——窗口大了,管理更难了窗口不是越大越好当模型能记住 1M token 的上下文时,问题变成了「你拿得出 1M token 高质量的上下文吗?」
这不再是「怎么写好 prompt」,而是「怎么管理一个项目级别的上下文资产」。Context Engineering 在这个问题驱动下诞生。它的核心任务:确保模型每次被调用时,都能拿到最相关、最精确、最新鲜的上下文。
代表性技术有三个:
RAG(检索增强生成):把模型的记忆工作外包给了向量数据库。你不是硬塞一个超长上下文,而是在模型推理前实时检索最相关的文档片段,只注入有用的部分。
MCP(Model Context Protocol):Anthropic 在 2024 年底推出的协议,定义了模型如何从外部系统获取上下文——读取文件系统、查询数据库、浏览网页。MCP 让 Agent 首次拥有了「联网」的能力,而不只是在对话窗口里跟用户来回聊天。
渐进式注入:不是一次性把整个上下文塞进窗口,而是根据 Agent 当前所处的行为阶段,按需注入对应的信息。
X 上的研究员 Aravind Putrevu 曾经列出了完整的演进链:Prompt → Flow → Context → Harness → Loop。在其中,Context Engineering 扮演了关键的桥梁角色——它把「怎么跟模型说话」的问题,转向了「怎么帮模型组装信息」。
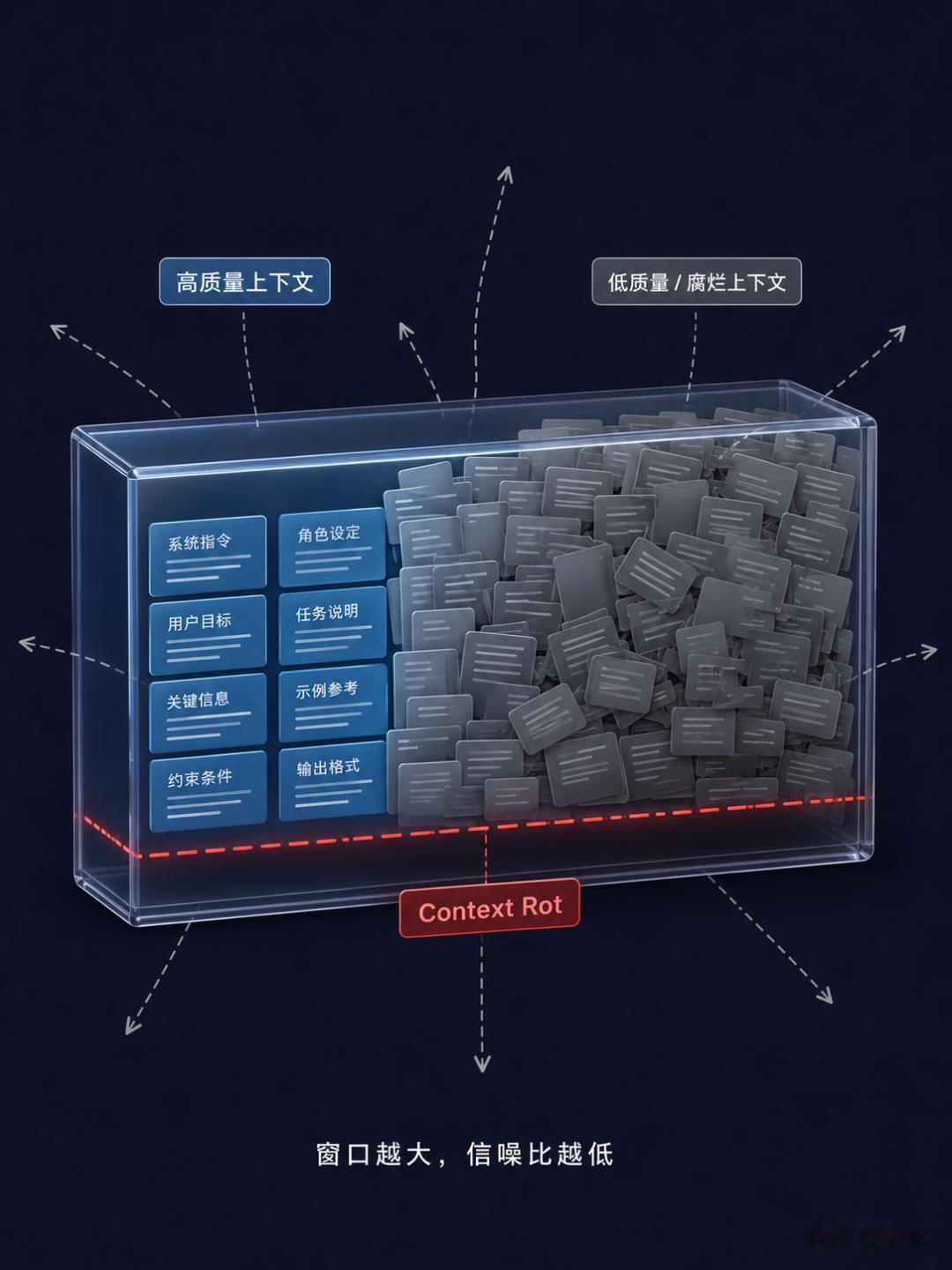
Context Rot——上下文腐烂然而,上下文多了之后,模型遭遇了一个新问题。
Addy Osmani 把它命名为 Context Rot(上下文腐烂)——窗口越满,模型越难抓住重点,推理质量反而不如只有少量上下文的时候。
他解释了这个机制:模型的注意力机制在整个上下文窗口上均匀分布。当窗口装得越满,注意力就越分散。模型能「看到」更多东西,但「看到」不等于「关注到」。
Akshay Pachaar 在分析多个 Agent 对话日志后发现了一个普遍的现象:Agent 在 session 开场时的输出质量远高于 session 结束时。不是因为模型变笨了,而是因为窗口被聊天历史塞满了。经典 GIGO(垃圾进垃圾出)的变体——进的不一定是垃圾,但太多垃圾就有了和信号一样的优先级。
Context Engineering 知道「喂什么」,却控制不了「被消化的质量」。这个局限,把问题推向了下一阶段。
 三、Harness Engineering——把 Agent 当作系统来设计Agent = Model + Harness
三、Harness Engineering——把 Agent 当作系统来设计Agent = Model + Harness2025 年底到 2026 年初,一个公式开始在 X 上扩散。
研究者 Viv Trivedy 首次明确提出:
Agent = Model + Harness
如果你不是模型本身,那你做的每一件事——每一个配置文件、每一行工具代码、每一个钩子脚本——都是 Harness。
Harness 具体包括什么?
系统 prompt、CLAUDE.md、AGENTS.md、skill 文件、sub-agent 指令工具、MCP 服务器、它们的名称和描述文件系统、sandbox、浏览器等基础设施编排逻辑:sub-agent 创建、任务转交、模型路由hooks 和中间件:编译检查、lint、权限控制可观测性:日志、追踪、成本和延迟监控Viv 的核心理念是:一个普通模型配上好的 Harness,可以打败顶级模型配上糟糕的 Harness。
这不是理论推导。Viv 的团队在 Terminal Bench 2.0——一个面向 Agent 任务的基准测试——上做了对比实验。他们不改模型,只改 Harness。结果:同一个 Agent 从 Top 30 拉到了 Top 5。
HumanLayer 的联合创始人 David 概括得更直接:「绝大多数 Agent 失败不是模型问题,是配置问题。」这句话在 X 上被转发了数千次。
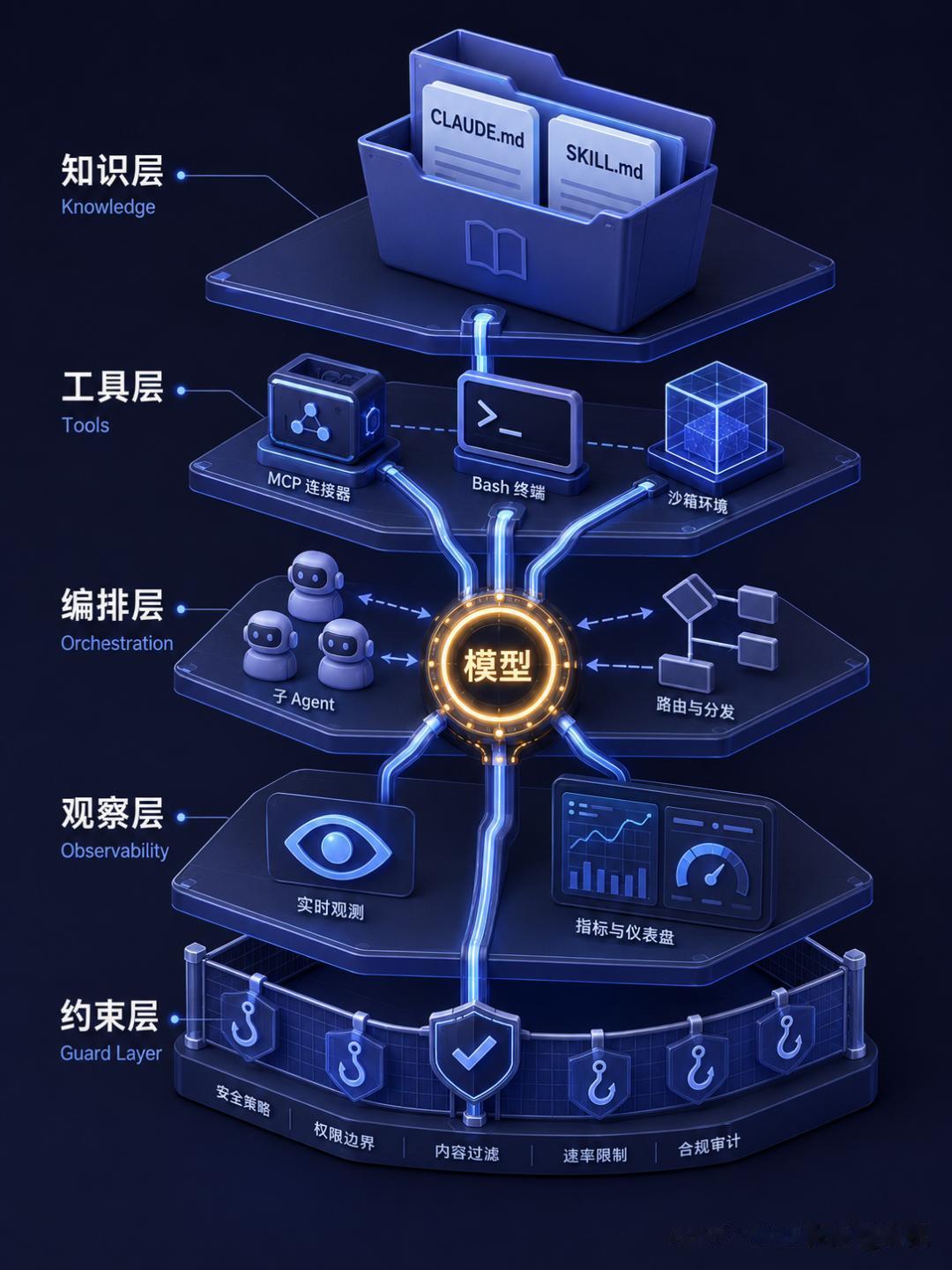
Harness 的五层架构综合 Viv 的原始定义和 Addy Osmani 在《Agent Harness Engineering》中的深度拆解,一个成熟的 Harness 至少包含五层:
知识层:系统 prompt、CLAUDE.md、AGENTS.md、skill 文件、sub-agent 指令。Agent 据此知道「怎么做事」。
工具层:MCP 服务器、工具描述、文件系统访问、bash 执行、sandbox 环境。Agent 据此获得了「能做事」的能力边界。Simon Willison 指出,bash 加代码执行已经成为 Agent 默认的通用解题策略——与其预置一百个专用工具,不如让 Agent 自己通过 shell 命令构建它需要的工具。
编排层:sub-agent 创建与转交、模型路由(哪个任务分配给哪个模型)、工作流定义。这决定了 Agent「如何做事」。
约束层:hooks——在特定生命周期点执行的脚本。比如「每次文件修改后自动跑 typecheck」、「提交前禁止 rm -rf」。这些决定了 Agent「不能做什么」。
Addy Osmani 在文章中提出了一个关键原则:Success is silent, failures are verbose. Typecheck 通过则 Agent 什么也听不到,不通过则错误信息自动注入到它的推理循环里。这种设计让反馈回路在正常情况下的开销为零,在异常情况下自动可操作。
观察层:日志、追踪、成本监控和延迟测量。这些决定了「你是否知道 Agent 做得怎么样」。
棘轮机制:每次错误都变成规则Harness Engineering 最核心的设计哲学被称为棘轮(Ratchet)——每次 Agent 犯错,不是一次需要被跳过的意外事故,而是一个设计输入。
Agent 发了 rm -rf / 这种破坏性命令?那不是偶然,是缺少一个阻止它的 hook。Agent 反复写出不符合编码规范的 PR?那不是幻觉,是 AGENTS.md 缺少对应的规则。
Addy Osmani 在文章里强调:「你的 Harness 里每一行规则,都应该能回溯到一个具体出过的问题。你只能因为真实失败而增加约束,不能因为空想而增加约束。」
这也解释了为什么 Harness Engineering 不能当作「一个框架」下载——每个团队的 Harness 都是他们过去失败的档案。
Harness 的真正转折Harness Engineering 让 Agent 构建从一个「怎么写 prompt」的写作问题,变成了一个「怎么设计系统」的工程问题。
Fareed Khan 在分析 Claude Code 架构时画了一张七层图。每一层都对应 Harness 的一个组件:知识层的 skill registry、编排层的 sub-agent spawning、约束层的 permission gate、执行层的 tool dispatch registry。Khan 的核心论点是——Claude Code 的能力增长,至少有一半来自 Harness 的迭代,而不是来自底层模型的升级。
但 Harness 同样有它的局限:它把环境构建好了,却还是需要人每次手动触发。这个局限,直接催生了当下的热点——Loop Engineering。
 四、Loop Engineering——让系统自己运行从「你发 prompt」到「系统发 prompt」
四、Loop Engineering——让系统自己运行从「你发 prompt」到「系统发 prompt」2026 年 6 月 7 日,Addy Osmani 的《Loop Engineering》一文上线,第一句就定下了基调:
「Loop Engineering 就是把自己替换成那个给 Agent 发 prompt 的人。你来设计一个系统,让系统来做这件事。」
这句话背后是一个根本的思维转换:原来是你对着 Agent 打字,现在你设计一个系统,这个系统替你跟 Agent 沟通、检查 Agent 的产出、记录 Agent 的进度,然后决定下一步该做什么。
Boris Cherny 那句话——「我不再给 Claude 发 prompt 了」——此刻变得完全可以理解了。他不是说 Claude 不需要 prompt,而是说发 prompt 的工作已经交给了他自己设计的 loop。
Addy Osmani 将 Loop 与 Harness 的关系概括为一句话:「Loop Engineering sits one floor above the harness. The harness but it runs on a timer, it spawns little helpers, and it feeds itself.」 翻译过来就是:Loop 坐在 Harness 的上一层。它给 Harness 加了一个定时器,让它自己能长出帮手、自己养活自己。
一个 Loop 的五个组件和一件必需品Addy Osmani 给出了 Loop 的最小结构:
1. Automations(自动化):按照 schedule 自动做任务发现和分类。Codex 的 Automations Tab 让你选 project、prompt、运行频率、环境,发现的问题自动落到 Triage inbox。Claude Code 通过 scheduled tasks、cron、/loop 命令和 hooks 达到同样的效果。
OpenAI 内部用 Automations 做日常的 issue 分类、CI 失败汇总和 commit 简报。而这些 automation 可以调用 skill,所以不用每次在 schedule 里贴一整段指令。
2. Worktrees(工作树):隔离并行 Agent 的操作区域。两个 Agent 同时写同一个文件,跟两个工程师提交到同一行代码一样致命。Git worktree 给每个 Agent 一个独立的 working directory,共享同一套 repo 历史,但物理上隔开了编辑区域。
Codex 直接在产品层面内置了 worktree 支持。Claude Code 提供了 --worktree flag 和 isolation: worktree 配置——每个 sub-agent 拿到一个自清理的 checkout。
3. Skills(技能):把项目知识写在 SKILL.md 里,每个 Agent session 都能读到。规范、构建步骤、历史教训——写一次,跑无数次。Agent 不再每次 session 都从头推断你的项目该怎么写。
Addy Osmani 在另一篇文章《Intent Debt》中提出:Agent 每次 session 都是冷启动,它会用自信的猜测填补你意图中的任何空白。Skill 就是把意图写在外面——写一次,Agent 每次运行都读到。
4. Plugins(插件)/ Connectors(连接器):基于 MCP 协议连接到你的真实工具——issue tracker、数据库、Staging API、Slack。这是 Agent 从「告诉你怎么修」升级到「直接开 PR、链 ticket、通知 channel」的关键。
Connectors 让 Loop 可以触达你的实际环境,而不仅仅是文件系统。
5. Sub-agents(子 Agent):把「写代码的人」和「检查代码的人」分开。
这是最关键的组件。写代码的模型给自己评分,分数一定偏高。你需要另一个 Agent——不同的 prompt、有时是更强的模型——来检查第一个 Agent 的产出。
Codex 用 TOML 文件定义 sub-agent,Claude Code 用 .claude/agents/ 目录。Addy Osmani 的建议:「让一个 Agent 探索方案,一个 Agent 实现代码,一个 Agent 对照 spec 检查结果。这三个角色不要混用。」
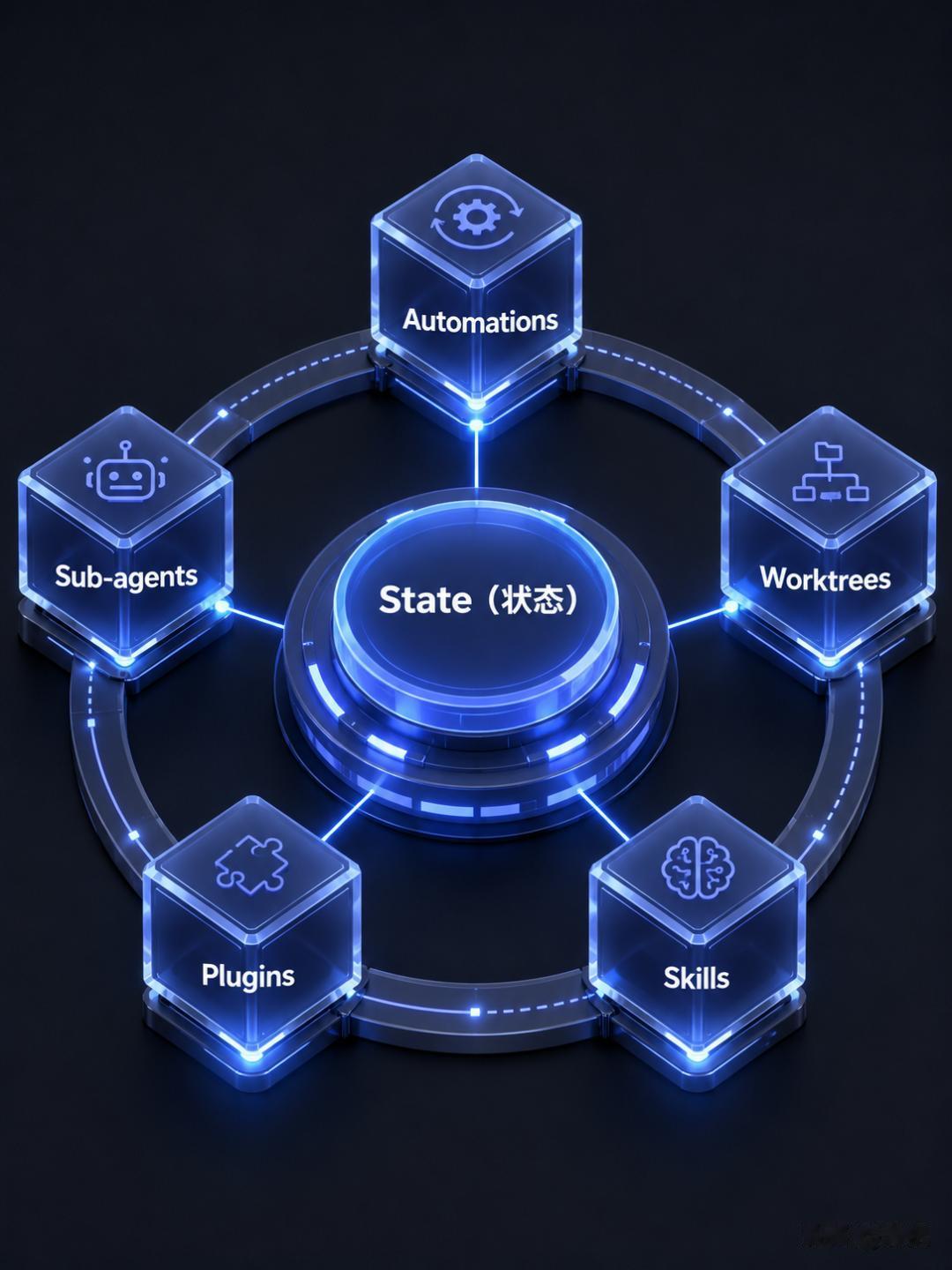
+ State(状态)——一件必需品。
模型在每轮 loop 之间会清空所有记忆。一个存在于 session 外部的 Markdown 文件或 Linear board,记录着「什么已经做了、什么还在等待、什么尝试过但失败了」。这就是 Loop 的「记忆」。听起来很简单,但它才是所有长期运行的 Agent 依赖的核心技巧。
两个产品,一组能力Addy Osmani 对比了 Codex 和 Claude Code 的 Loop 原语:
组件
Codex
Claude Code
Automations
Automations Tab
/loop, cron, hooks
Worktrees
内置 per-thread
git worktree, --worktree
Skills
SKILL.md
SKILL.md
Plugins
MCP Connectors
MCP servers
Sub-agents
.codex/agents/
.claude/agents/
State
Markdown / Linear
AGENTS.md / Linear
名称不完全一样,但能力等价。Addy Osmani 总结:「一旦你看穿了这层抽象,你就不需要争论哪个工具更好——你应该设计一个不依赖具体工具的 loop。」
 Loop 不解决的三件事
Loop 不解决的三件事Addy Osmani 在文章里诚实列出了三个风险:
验证责任仍在你的肩上。 Loop 无脑运行时,也是 Loop 无脑犯错时。你把「写」和「检查」分开,不过让系统"以为完成了"的可信度提高了一些。最终的确认还是你来。他的原话:「你的工作就是保证你发布的代码是确认可以运行的。」
你的理解会迅速退化。 Loop 产出代码的速度远超你阅读代码的速度。这个差距,他称之为 Comprehension Debt(理解债务)。一个平滑运行的 Loop 只会让这个差距扩大得更快——除非你阅读它产生的每一条 PR。
认知投降是最危险的姿势。 当 Loop 运行得足够顺畅时,你会倾向于不再有意见。Loop 给出什么你就接受什么。他称之为 Cognitive Surrender。这和「让自己变蠢」的距离只有一念之差。
「同样一个 Loop,两个人能跑出完全不同的结果。一个人用它来加速对已经深刻理解的工作,另一个人用它来逃避理解工作本身。Loop 不知道区别。你知道。」——Addy Osmani
五、接下来:还缺什么Fleet Engineering 正在萌芽极少数人已经开始讨论 Fleet Engineering。Cobus Greylock 在 X 上提出:如果 Loop 是「一个 Agent 的自动化周期」,Fleet 就是「多个 Loop 的编排系统」。
这个想法还处在非常早期的阶段。但逻辑是明确的:当多个 Loop 同时运行、共享资源、产生冲突时,自然需要更高的治理层。这跟从单体服务到微服务、再到 Service Mesh 的演进路径高度一致。
 给开发者的五个动作打开 Claude Code 或 Codex,执行一次 /goal 或创建第一个 Automation。 亲自感受你和 Agent 之间的关系发生了什么变化。为你的项目写一个 AGENTS.md 或 SKILL.md。 把编码规范、构建步骤、常用工具链写进去。然后观察 Agent 的行为变化。对比同一任务「直接写 prompt」和「设计 loop」的 token 消耗差异。 有些任务适合 loop,有些直接 prompt 更经济。养成读完 loop 生成的每条 PR 的习惯。 不要让理解债务堆积到不可控的程度。关注 Addy Osmani 的博客和 Viv Trivedy、Akshay Pachaar 在 X 上的讨论。 这群人正在定义下一代 AI 工程师的技能栈。收尾:每一步,工程师都离模型更远一步
给开发者的五个动作打开 Claude Code 或 Codex,执行一次 /goal 或创建第一个 Automation。 亲自感受你和 Agent 之间的关系发生了什么变化。为你的项目写一个 AGENTS.md 或 SKILL.md。 把编码规范、构建步骤、常用工具链写进去。然后观察 Agent 的行为变化。对比同一任务「直接写 prompt」和「设计 loop」的 token 消耗差异。 有些任务适合 loop,有些直接 prompt 更经济。养成读完 loop 生成的每条 PR 的习惯。 不要让理解债务堆积到不可控的程度。关注 Addy Osmani 的博客和 Viv Trivedy、Akshay Pachaar 在 X 上的讨论。 这群人正在定义下一代 AI 工程师的技能栈。收尾:每一步,工程师都离模型更远一步让我用一张表做收束:
阶段
原因
解决
付出的代价
Prompt Engineering
模型听不懂指令
精炼输入
每次重写,不可积累
Context Engineering
模型记不住上下文
管理外部上下文
Context Rot 导致推理降解
Harness Engineering
模型没有稳定环境
构建完整 Agent 系统
配置复杂度指数上升
Loop Engineering
每次任务要手动触发
设计自动迭代循环
认知风险:验证责任和理解的退化
Fleet Engineering(?)
多个 Loop 无法协同
编排系统
尚未明确
每一次新阶段的出现,不是因为旧的范式被「推翻」了,而是因为旧的范式把当时的核心问题解决了,同时暴露了一个更底层的瓶颈。每一次,工程师都离「直接操作模型」更远了一步——从写 prompt,到管 context,到建 harness,到设计 loop——但每一步,能解决的问题范围都大了一个数量级。
最后那段话,留给 Addy Osmani:
Build the loop. But build it like someone who intends to stay the engineer, not just the person who presses go.
设计你的 Loop。但要像一个打算继续做工程师的人那样去设计它——而不是像一个只想按开始按钮的人。
