
有一句话正在以不可思议的速度在 X 平台上被转发。2026 年 6 月,Anthropic Claude Code 的负责人 Boris Cherny 直接抛出一句话,让整个 AI 工程圈安静了几秒——"我已经不再为 Claude 写 Prompt 了。我的工作是写循环,循环再去驱动 Claude。"
同一周,OpenAI 的 Peter Steinberger(OpenClaw 的创造者)也说了几乎一模一样的话——"你不应该再为编码 Agent 写 Prompt 了。你应该设计一个循环,让循环替你去 Prompt Agent。"
前 Google Director Addy Osmani 随后写了长达七千词的拆解长文,把这件事拆了个底朝天。Andrej Karpathy 补了一句:"把自己从瓶颈中移除。投进去极少的 Token,让海量的事情在你的视角之外自动发生。"
Loop Engineering(循环工程)这个术语,就这么在几周之内从专家圈内暗语变成了整个 AI 工程界最大的讨论议题。Codez 在 X 上发布了一篇"14 步路线图"长文,标题绝不说教但毫不留情:10 个工程师中有 9 个从来没有写过一条让 Agent 自动运行的循环。 他们还在手动输入 Prompt、等待、读完结果、再输入下一条。Addy Osmani 的文章在两周内获得近 200 万阅读量,Rahul 的拆解达到 350 万阅读量——这不再是一个边缘话题。
为什么?因为在之前两年,我们一直在谈"Prompt Engineering"——让工程师学会如何跟模型对话。现在我们发现这条路已经到头了。真正的游戏,已经变成了设计一个系统,让这个系统替你跟模型对话。
这篇文章,会把这整个范式的底层逻辑、五个核心构件加一条脊梁、一个真实的完整循环全貌、以及它能做到什么和它不能做什么,做一次彻底的拆解。
不再"喂养"Agent,而是为 Agent"设计工厂"先想一个问题。
过去两年,你打开 Claude Code 或者 Codex,输入一条 Prompt,等它跑完,检查结果,然后再输入下一条。这本质上跟你在终端里一条一条敲命令没有区别——你把 AI Agent 当作一把更智能的锤子,而你是那个握着锤子的人。
Loop Engineering 的革命性在于:你不再握着锤子了。你设计了一条机械臂,机械臂自己握着锤子,你告诉机械臂"把钉子全部钉完",然后你就去干别的事了。
这不是比喻。Boris Cherny 在最近一场 40 分钟的炉边谈话中直接透露:他目前 30% 的代码已经完全由 Loop 自主生成,他本人只在关键决策点介入。"Loops are as big a step as the move from source code to agents. Loops — step from agents to the next thing."
这个数字意味着什么?意味着每次迭代都不再是工程师在手动完成一次 Prompt→检查→再 Prompt 的回合,而是由一个循环系统自动完成成百上千个这样的回合。工程师的工作从"执行者"变成了"设计者"。
Peter Steinberger 在这个问题上说得更直白:以前你把 80% 的精力花在写好的 Prompt 上,现在你把 80% 的精力花在设计一个能持续产生好结果的循环上。
这个转变的本质,是一次抽象层级的跃迁——就像从汇编语言的逐条指令进化到 C 语言里的 for 循环和 while 循环。你不再控制每一个时钟周期,你定义了控制流,然后放手让机器自己去跑。
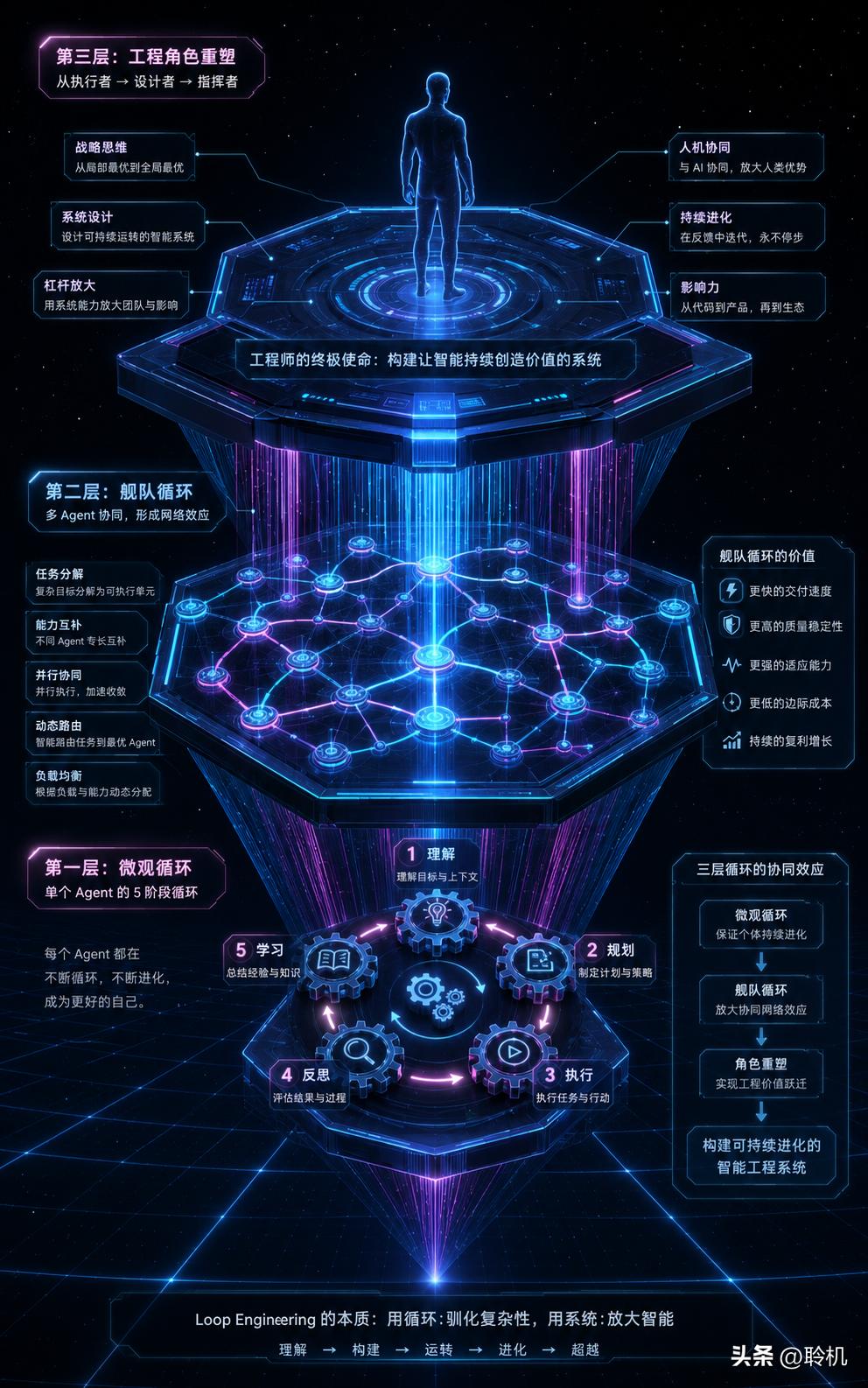
每一个 Loop 都有相同的五个阶段在深入构件之前,先理解一个基础框架。不管多简单或多复杂的循环——单 Agent 还是舰队编排——每一个 Loop 都经过相同的五个阶段:
DISCOVER(发现)→ PLAN(规划)→ EXECUTE(执行)→ VERIFY(验证)→ ITERATE(迭代) 通过验证 → 交付。未通过验证 → 再来一轮。这就是循环的全部核心思想。Rahul 在他的 350 万阅读量长文中用了这个框架来贯穿整个讨论,因为它定义了循环最基础的"执行单元"。所有构件的设计,最终都是为了让这 5 个阶段能自动、可靠的运转。
一篇来自一线开发者 Boris Cherny 的透底 -> "循环"不是什么玄学。是一个定义好的最小执行单元,反复执行直到满足终止条件。
在这个框架之上,才有两种基本的循环尺度:
单 Agent 循环:一个 Agent 独立完成全部五个阶段。适合聚焦任务、小范围目标。一个大脑,一个循环,自我改进。
舰队循环:Orchestrator 把目标拆成多个子目标,分配给 Specialist Agent,Specialist 再分配给 Sub-agent。整棵树中的每一个 Agent 都按相同的 5 阶段循环运行。Rahul 给出的例子:Orchestrator 拥有"构建一个生产力应用"的任务,它下面有三个 Specialist——Research(研究工作)、Engineering(工程实现)、QA(质量验证),每个 Specialist 又有自己的 Sub-agent。
 五块积木 + 一根脊梁:Loop Engineering 的底层架构
五块积木 + 一根脊梁:Loop Engineering 的底层架构Addy Osmani 在他的长文中干了一件很实在的事:他直接拆出了 Loop 的完整架构。不管你在 Claude Code 上跑还是在 Codex 上跑,这五个构件都是相同的。
 第一块积木:Automations(自动化调度)——循环的心跳
第一块积木:Automations(自动化调度)——循环的心跳自动化调度是让一个循环真正成为循环、而不是一次一次性执行的东西。
在 Codex 里,你在 Automations 面板创建一个任务——指定项目、Prompt、运行频率、检查是在本地 Checkout 还是后台 Worktree 上跑。跑出结果的进入 Triage 收件箱,什么都没跑出来的自动归档。OpenAI 内部已经用这种机制做日常 Issue 分类、CI 失败总结、Commit 简报编写、以及谁上周引入了 Bug 的自动排查。
Claude Code 走的是同一套逻辑,但通过 Scheduling 和 Hooks 实现。你可以用 /loop 命令让一个循环按固定间隔运行,可以设置 Cron 任务,可以在 Agent 生命周期的特定节点触发 Shell 命令,或者把整个流程推到 GitHub Actions 上让它在你合上电脑后继续运行。
关键点在于:这两种工具的实现路径不同,但抽象能力完全相同——你定义一个自治任务,给它一个节奏,结果自动回到你面前。就像 Peter Steinberger 说的:"You shouldn't be prompting coding agents anymore. You should be designing loops that prompt your agents."
更值得注意的是,Claude Code 里还有一个更深层的原语——/goal。它不是按固定间隔运行的,而是持续运行直到你写下的条件被满足。每执行一轮,它会让一个独立的、较小的模型去判断条件是否达成,而不是让写代码的那个 Agent 自己给自己打分。你可以给它一个条件如"test/auth 目录下的所有测试通过且 Lint 干净",然后离开。Codex 也有同样的 /goal 原语,跨轮次持续工作,直到一个可验证的终止条件成立。
这一层是循环的触发引擎——它负责发掘工作并呈现给你,而你不需要坐在旁边。
第二块积木:Worktrees(工作树)——让并行不变成灾难一旦你运行超过一个 Agent,文件系统冲突就成了最大的敌人。两个 Agent 同时修改同一个文件,跟两个工程师同时编辑同一行代码然后没有事先沟通——结果是一样的灾难。
Git Worktree 解决的就是这个问题。它是一个独立的、共享同一仓库历史、走独立分支的工作目录。Agent A 的修改物理上触碰不到 Agent B 的 Checkout。
Codex 内置了 Worktree 支持,多个线程可以同时操作同一个 Repo 而不相互干扰。Claude Code 同样通过 --worktree标志提供隔离——每个子 Agent 获得一个独立的 Checkout,使用完毕后自动清理。这就是 Addy Osmani 说的 "Two agents writing to the same file is the same problem as two engineers committing to the same lines without talking."
有一个问题很多人没意识到:物理冲突被 Worktree 解决了,但人的审查带宽仍然是瓶颈。不是你跑多少并行 Agent 就出多少活,你能 Review 多少决定了你能跑多少。
第三块积木:Skills(技能)——让 Agent 记住你的项目一个 Skill 其实就是一组文件——一个包含指令和元数据的 SKILL.md,加上可选的脚本、参考资料和资源文件。它的作用是把你的项目知识固化到外部,让每个新运行的 Agent 直接获取不需要从头推导。
Codex 通过 $ 或 /skills 加载技能,或者当任务描述与技能描述匹配时自动加载。Claude Code 走同样的方式。关键不在语法,而在于技能把"意图"变成了可复用的资产。
Addy Osmani 在本月初写的 Intent Debt 一文中提过一个尖锐的问题:Agent 在每个会话开始时都是冷的,如果你的意图有任何空洞,它会用一个自信的猜测来填上。 Skill 就是你把意图写在外部的东西——约定、构建步骤、"我们为什么不这么做因为上次出过那件事"——写一次,每个循环都能读到。
没有技能,循环每次从零推导你的项目。有技能,它是在积累。MIKE 在他那篇获得 120 万阅读量的文章中引用了一句话:"a prompt gets you one response. a loop gets you a system that keeps working after you close the laptop." Skills 就是这个"持续工作"的知识燃料。
第四块积木:Plugins & Connectors(插件与连接器)——循环伸出触角一个只能看到文件系统的循环,是一个极其微小的循环。
Connectors 基于 MCP 协议(Model Context Protocol),让 Agent 能读到你的 Issue 跟踪器、查询数据库、访问 Staging API、往 Slack 发消息。Codex 和 Claude Code 都实现了 MCP,所以你在一个工具下写的 Connector 通常能在另一个工具里直接使用。这也是为什么 Claude Code 团队说"Connectors are the difference between an agent that says 'here's the fix' and a loop that opens the PR, links the Linear ticket, and pings the channel once CI is green — by itself."
这跟传统的 API 调用的区别是什么?Connector 是写在外面、供 Agent 自主调用的,不是由你来调用它。 你的循环中的子 Agent 在运行时发现需要查 Linear 里的某个 Issue 的当前状态,它自己就会通过 MCP Connector 去查。
Plugin 进一步把 Connector 和 Skill 打包在一起。你的队友安装一个 Plugin,就安装了你整套工作流——不需要逐个复制粘贴配置。
这一层决定了你的循环能在一个真实的、有 Jira 工单、有 CI 流水线、有 Slack 通知的工程环境里真正行动,而不是在真空中写代码然后告诉你"这里应该有一个修复"。
第五块积木:Sub-agents(子 Agent)——把创作者和评审者分开这是整个循环架构里最有价值的结构性设计,没有之一。
写代码的那个模型给它自己的作业打分,分太高了。
在评估自己的工作时,模型有一种微妙的"自我说服"倾向——它知道自己是怎么写的,所以它能说服自己"这样写是对的"。一位独立的、接受不同指令甚至使用不同模型的第二个 Agent,能抓到第一个 Agent 自己说服自己而放过的错误。这就是 "Keep the maker away from the checker."
Codex 中,你可以通过 .codex/agents/ 目录下的 TOML 文件定义自己的 Agent——每个 Agent 有名字、描述、指令、可选的模型和推理能力设置。安全审查用一个强模型配高推理成本,探索者用一个高速只读模型。子 Agent 可以并行运行,结果汇入同一个答案。
Claude Code 同样支持 .claude/agents/ 下的子 Agent 定义,以及 Agent Team——在 Agent 之间传递工作。两者最常见的工作拆分都是:一个 Agent 探索和分析,一个 Agent 具体实现,一个 Agent 根据需求规格做验证。这种 Maker-Checker 分离同时解决了循环中一个根本性的信任问题:当循环在你不在电脑前的时候运行,验证者的判断是你说服自己"可以离开"的唯一依据。
子 Agent 确实消耗更多 Token——这是真实的成本。Rahul 在他的文章中坦诚地给出了数字:单 Agent 循环一次执行消耗 50,000–200,000 Token;包含 Orchestrator 和 3 个 Specialist 的舰队循环消耗 500,000–2,000,000 Token。"Loops are not hard to design. They are hard to afford." 但这正是 DeepSeek V4 等中国模型正在改变的方程——当百万级 Token 的 API 调用成本从数十美元降到一两毛钱时,循环的 Token 消耗不再是一个不可逾越的障碍。
 那根脊梁:Memory(记忆层)——让循环不忘记自己做过什么
那根脊梁:Memory(记忆层)——让循环不忘记自己做过什么六个构件中最不起眼、但恰恰是最关键的一个。
一个 Markdown 文件,或者一个 Linear Board,或者数据库里的一张表——任何活在单次对话之外、记录着"什么是已完成的"和"什么是下一步的"的信息载体。
听起来太笨了以至于不值得提。但每一个长期运行的 Agent 最终都依赖这个技巧:模型会在每次运行之间忘记一切。记忆不能放在上下文里——上下文会被清空。记忆要放在硬盘上。
这个状态文件是整个循环的脊椎。明天早上循环启动时,通过读这个文件就能知道今天尝试了什么、什么通过了、什么还在待办中。DeepSeek V4 的 1M Token 窗口为这个"记忆"提供了更多空间——长运行的循环可以保持更长时间的上文连贯性。但即使如此,一次运行结束后,"记忆"必须落盘。
Addy Osmani 说得更直接:没有 Memory 的循环根本无法存在。它就是你每次离开后还能继续工作的唯一原因。
两个关键的循环变量在理解所有构件后,还有两个更高维度的区分。这两个变量决定了你的循环是可控可用的,还是浪费 Token 的 Bug 制造机。
Open Loop vs Closed LoopRahul 在文章中提出了或许是 2026 年最重要的关于循环的实践区分:
Open Loops(开放循环):探索性的。你给 Agent 一个目标,让它自由探索不同的路径。这就是 Peter Steinberger 和 OpenAI 正在做的事情——令人兴奋,但 Token 消耗巨大。对于 90% 没有无限 API 预算的人来说,开放循环暂时还不现实。更危险的是——没有严格质量标准指向的开放循环,会变成一台高效的"垃圾生成机"。
Closed Loops(封闭循环):有边界的。工程师先设计好端到端的路径:明确的目标 → 定义的步骤 → 每一步的评估 → 终止或回退的节点。Agent 仍然在循环,但在你构建的框架之内。每一次运行都会喂给下一次。Token 消耗是可控的,质量标准是写死的。
Addy Osmani 对此的忠告非常务实:"Start with closed loops. Build a tight system that works reliably. Then open it up once you have the quality gates."
Single-Agent Loop vs Fleet Loop我们已经在前面的框架里提到了这两种尺度。这里需要强调的是:两种尺度都遵循相同的 5 阶段循环。唯一的区别是舰队循环中的每一个节点——Orchestrator、Specialist、Sub-agent——都在自己的层级上运行 DISCOVER→PLAN→EXECUTE→VERIFY→ITERATE。
Chris Parsons(曾在 Claude Code 内部设计了 Ralph Loops 系统)有一个深刻的观察:"Dumb loops beat clever workflows." 大部分团队一上来就想搭复杂的多 Agent 编排图,然后花数个月调试它们。而真正在生产环境中活下来的系统,往往是最简单的循环——一个标准触发器、一个确定的执行步骤、一个持久化的状态文件、一个干净的失败回退方式。(这也呼应了 88% 的 Agent 原型项目在生产环境中死亡的数据。)
 一个真实的循环
一个真实的循环好,以上全部构件和设计变量我们都看完了。把它们拼在一起。
下面是一个已经有人在生产环境中使用的真实模式:
上午 8:00,一个 Automation 在 Repo 上自动启动。它的 Prompt 调用了一个名为"triage"的 Skill——这个 Skill 读取昨天的 CI 失败记录、当前开放的所有 Issue、最近的 Commit 记录,然后把分析结果写进一个 Markdown 文件或者 Linear Board。
上午 8:05,对于每一个值得处理的分析结果,系统在一个隔离的 Worktree 里启动一个子 Agent。这个子 Agent 负责起草修复方案。它是循环框架中的 PLAN → EXECUTE 阶段。
上午 8:07,第二个子 Agent——一个独立的审查者——在同一个 Worktree 上审查这个修复。它检查提交是否符合项目 Skills 中定义的编码规范,以及是否引入了新的测试失败。这是 VERIFY 阶段。
上午 8:10,如果审查通过,Connector 自动打开一个 PR,更新 Linear 上的 Ticket 状态,并在 CI 变绿后自动在 Slack 频道里发一条通知。
然后循环等待。等待第二天早上再次启动。Memory 文件记录了一切:什么被尝试了、什么通过了、什么还在等待。明天的运行会从今天停止的地方继续。
看懂了你就明白 Addy Osmani 那句话的意思:你真正做的事情,是一次性设计,然后你从来没有亲自完成过任何一个 Prompt 步骤。 这就是 Peter Steinberger 说的"你不再编写 Prompt,你设计让 Prompt 发生的循环"。
Boris Cherny 在此基础上又补了一句:"30% of my code is fully written by loops right now." 不是未来。是现在。
真正的瓶颈不是 Agent 的智商,而是人的审查带宽有一件事所有关于 Loop 的讨论都在有意无意地回避,但如果你真打算在生产环境中运行循环,你必须面对。
Worktree 解决了 Agent 之间的物理冲突。Connector 解决了 Agent 触及外部系统的问题。Sub-agent 让验证者有独立性。但人的审查带宽是最后的瓶颈。
Addy Osmani 把这个问题说得很清楚:一个循环在无人留守的情况下自动跑出来,也是一个循环在无人留守的情况下自动犯错的东西。 你把 Maker 和 Checker 分开的原因,正是为了让循环声称"完成了"这句话有更多可信度。但就算这样,"完成了"也只是一个声明,不是一个证明。在关键变更上,你仍然需要亲自读代码。
更深的危险在城市里慢慢滋生。
你的理解会随着你越来越少接触循环产生的代码而逐渐退化——Addy Osmani 称之为"理解负债(Comprehension Debt)"。循环越快,生产代码越多,你真正理解的东西占比就越小。你今天设计了一个循环,三个月后它产出了一千次 PR,你能看懂其中多少?如果今天循环依赖的一个底层库断崖式更新,你知道该修哪里吗?
还有一个更危险的东西,Boris Cherny 称之为"认知投降(Cognitive Surrender)"。当循环能自动跑出看起来像那么回事的结果,你会越来越倾向于不再对结果有独立的判断,而是直接接受循环给你的东西。你把判断权让渡给了系统。你不再是一个工程师,你变成了一个"按钮按下者"。
Addy Osmani 在他的长篇博客中写了一段话,我认为是对"两拨人面对同一套工具得到不同结果"现象最精准的注脚:
"Two people can build the exact same loop and get completely opposite results. One uses it to move faster on work they understand deeply. The other uses it to avoid understanding the work at all. The loop doesn't know the difference. You do. That's what makes loop design harder than prompt engineering — not easier."
这就是为什么 Loop Engineering 比 Prompt Engineering 更难,而不是更容易。 如 Boris Cherny 所说,工作的杠杆点移动了,但工作的密度没有降低。
 从 Prompter 到 Loop Designer:一次真正的职业重塑
从 Prompter 到 Loop Designer:一次真正的职业重塑写到这里你可能已经感觉到了——这不是一次小的流程改进,这是一次职业角色的重塑。
Rahul 在他那篇 350 万阅读量的长文中画了一个直观的对比:
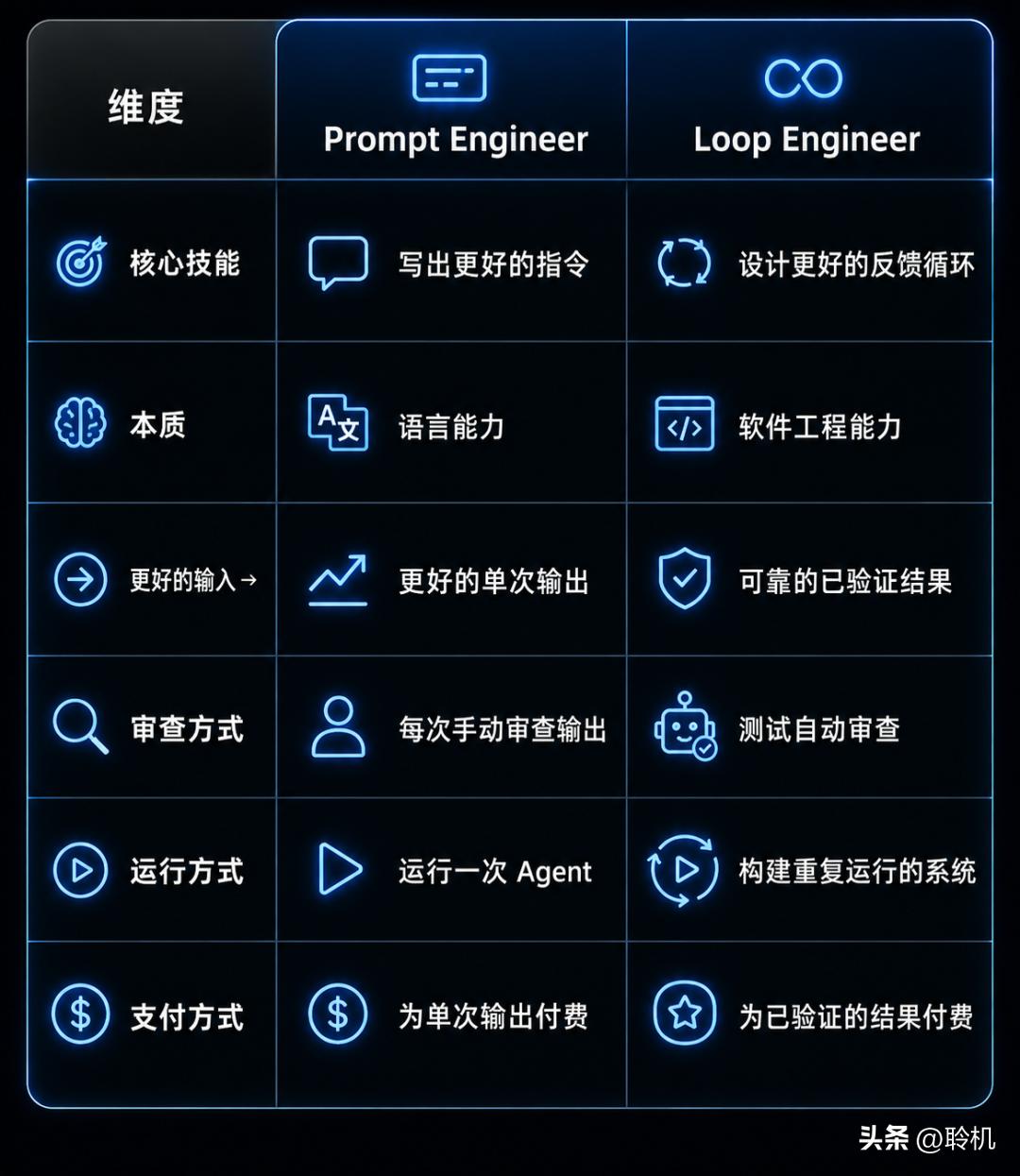
工具是相同的。思维方式完全不同。
Prompt Engineer 向 Agent 要输出。Loop Engineer 设计能产生已验证结果的系统。
2026 年薪酬最高的 AI 工程师写的不是更优美的英文句子。他们写的是决定 Agent 如何发现、规划、检查自己的工作、以及知道何时完成的逻辑。
Boris Cherny 在访谈中说得非常直白:"循环带来的变化,不亚于从手写源代码到 Agent 的转变。" Loop 是从 Agent 到下一层范式的台阶——30% 的代码已由循环完全自主完成。
这不是宣传。这是一线正在发生的事实。
 结语:你在设计哪一层?
结语:你在设计哪一层?如果把 Loop Engineering 放在更大的历史坐标里看,你会清晰地看到这条轨迹:从机器指令到汇编,从汇编到高级语言,从手动操作数据库到 ORM,从手动部署到 CI/CD 流水线。每一次抽象层级的提升,都有一个共同规律——工程师的焦点从"如何执行"变成了"如何设计执行的系统"。
Loop Engineering 不是这条规律的特殊情况,它是这条规律在 AI 时代的自然延伸。
你可能对它有怀疑,觉得它不安全,觉得它会出错。但每一次抽象层级的跃迁在最初都被认为是不安全的。高级语言被认为不如汇编高效,ORM 被认为性能太差,CI/CD 被认为不可控。
对于还在手动输入 Prompt 的工程师来说,这不是一个"要不要学"的问题。这是一个"什么时候开始"的问题。就像汇编程序员意识到有了 C 语言还要不要学 for 循环一样。Loop Engineering 不是一个可选项,它是 Agent 时代的"操作系统内核"——你开发的应用,最终都会跑在这一层上。
Karpathy 说:"Remove yourself as the bottleneck."
你今天的代码最终会被循环生成。问题是,你打算成为那个设计循环的人,还是成为那个被循环取代的人?
