[CL]《AuditoryBench++: Can Language Models Understand Auditory Knowledge without Hearing?》H Ok, S Yoo, H Kim, J Lee [Pohang University of Science and Technology & HJ AILAB] (2025)
语言模型真的能“听”懂声音吗?AuditoryBench++带你揭开LLM听觉常识的盲点。
• AuditoryBench++:首个专注于纯文本场景下评测语言模型听觉知识的综合基准,涵盖5大任务——音高、时长、响度比较,动物叫声识别,以及基于语境的复杂听觉推理。
• 任务设计严谨,数据经过多轮人工过滤和统计验证,确保客观、无歧义,模拟真实仅有文字描述无声音信号的场景,更贴近实际应用需求。
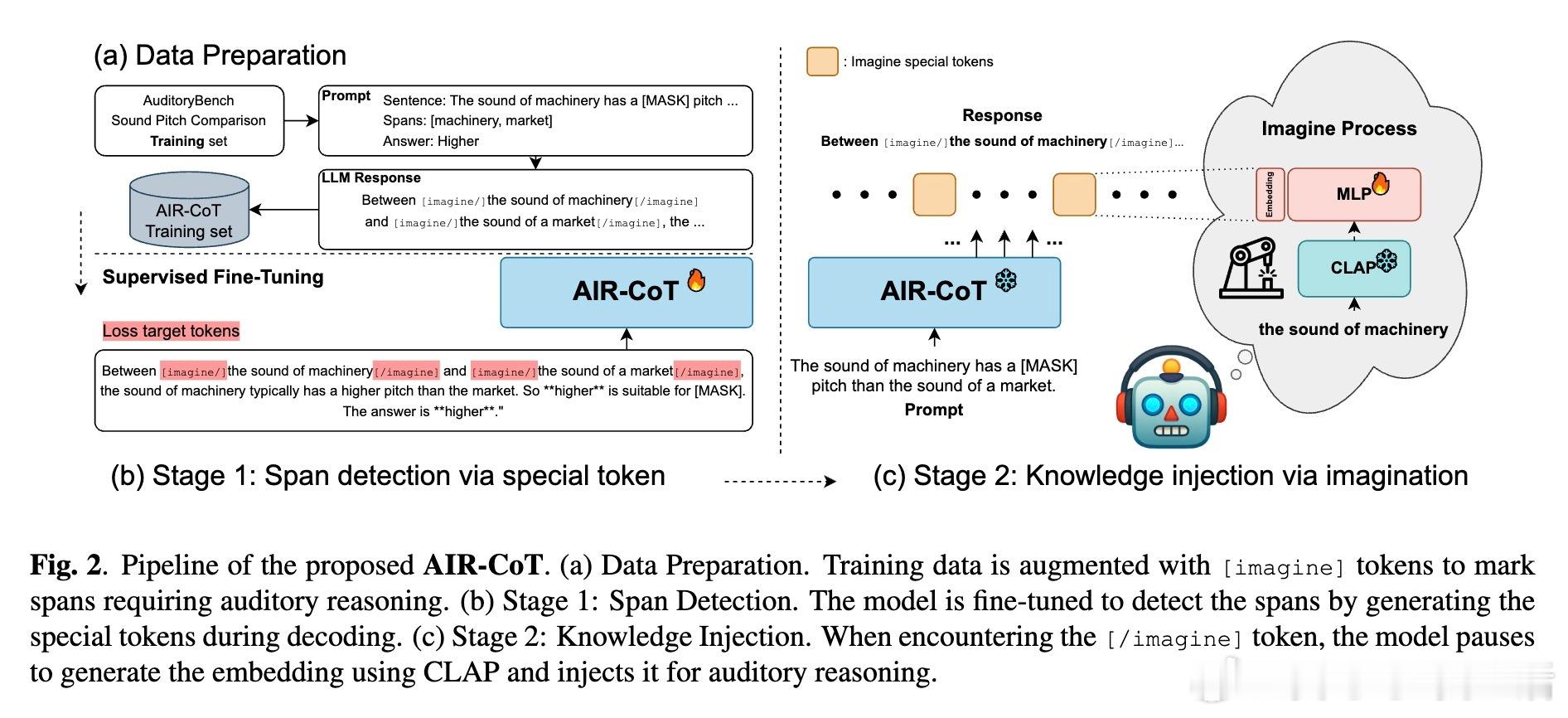
• AIR-CoT创新提出“听觉想象链式推理”:模型在推理时自动检测需听觉知识的文本片段,插入特殊[imagine]标记,暂停文本生成,调用音频编码器CLAP注入声音向量,实现“无声听觉”,显著提升推理能力。
• 实验突出AIR-CoT在音高比较、动物声音识别和语境推理任务中提升8%~12%,远超传统语言模型及已有的听觉知识增强方法;但响度和时长推理仍受限于当前音频向量的时间和幅度编码能力。
• 研究指出:语言模型缺乏听觉常识并非不可逾越,关键在于如何模拟人类“听觉想象”过程,将声音信息以嵌入形式内生于推理链条,开启多模态理解新路径。
• 未来需突破现有音频表示对时序和幅度信息的弱敏感,推动语言模型在无声环境中实现更精准、丰富的听觉推理与感知。
心得:
1. 语言模型的“听觉理解”不是单纯的数据累积,而是对声音特性的动态想象和集成,重塑了传统纯文本推理的边界。
2. 多模态知识注入应更注重过程机制(如特殊标记触发想象),而非简单拼接外部信息,真正实现模型的主动感知能力。
3. 评测体系设计需还原真实使用场景,AuditoryBench++示范了如何用文本任务逼真模拟无声听觉场景,推动听觉AI研究更具实用价值。
详细阅读👉 www.arxiv.org/abs/2509.17641
人工智能语言模型多模态学习听觉理解机器推理