[CL]《CompLLM: Compression for Long Context Q&A》G Berton, J Unnikrishnan, S Tran, M Shah [Amazon] (2025)
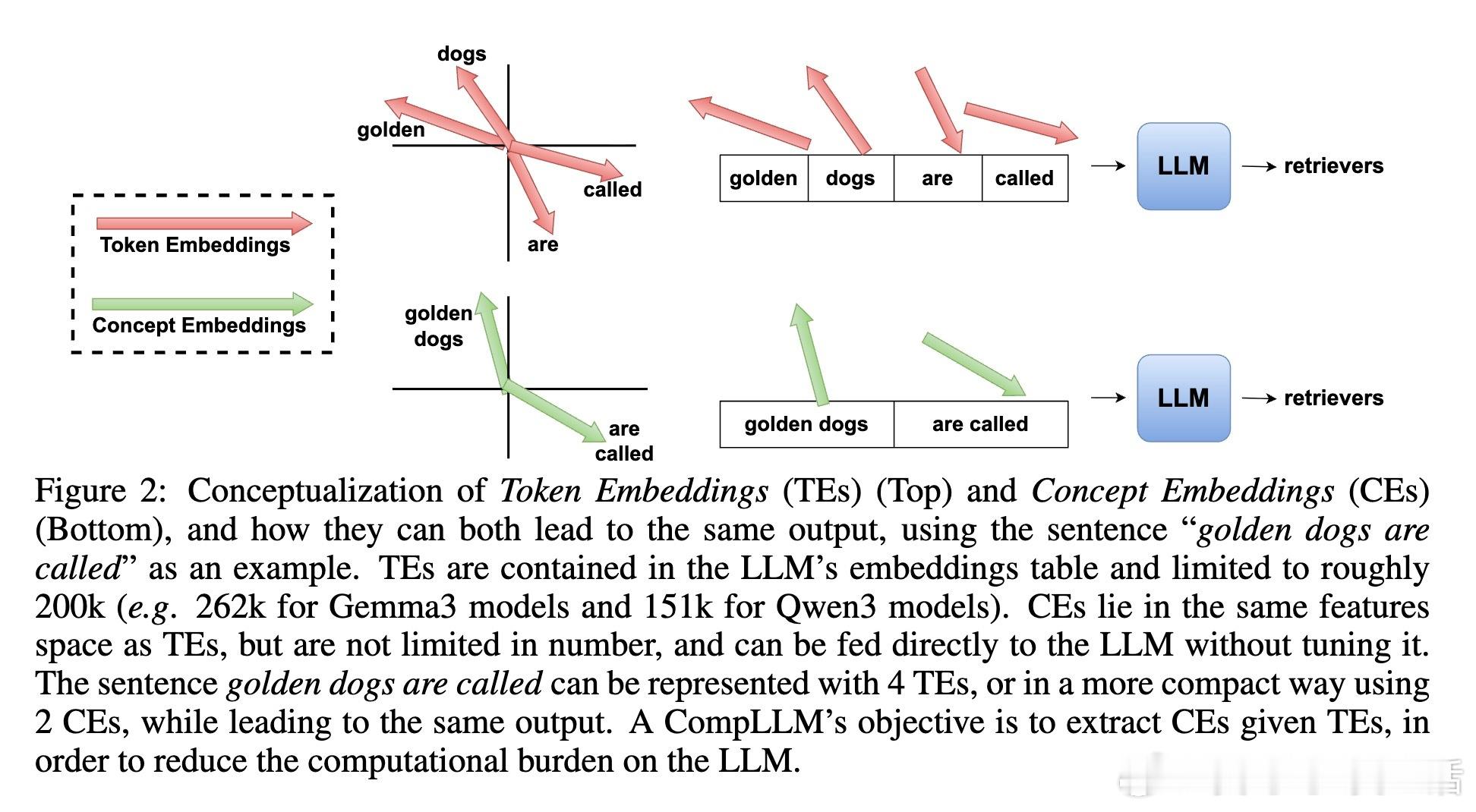
处理超长上下文时,LLM 面临的计算瓶颈主要源于自注意力机制的二次方复杂度。CompLLM 提出了一种软压缩方法,通过将长文本拆分成独立段落分别压缩,带来了以下突破:
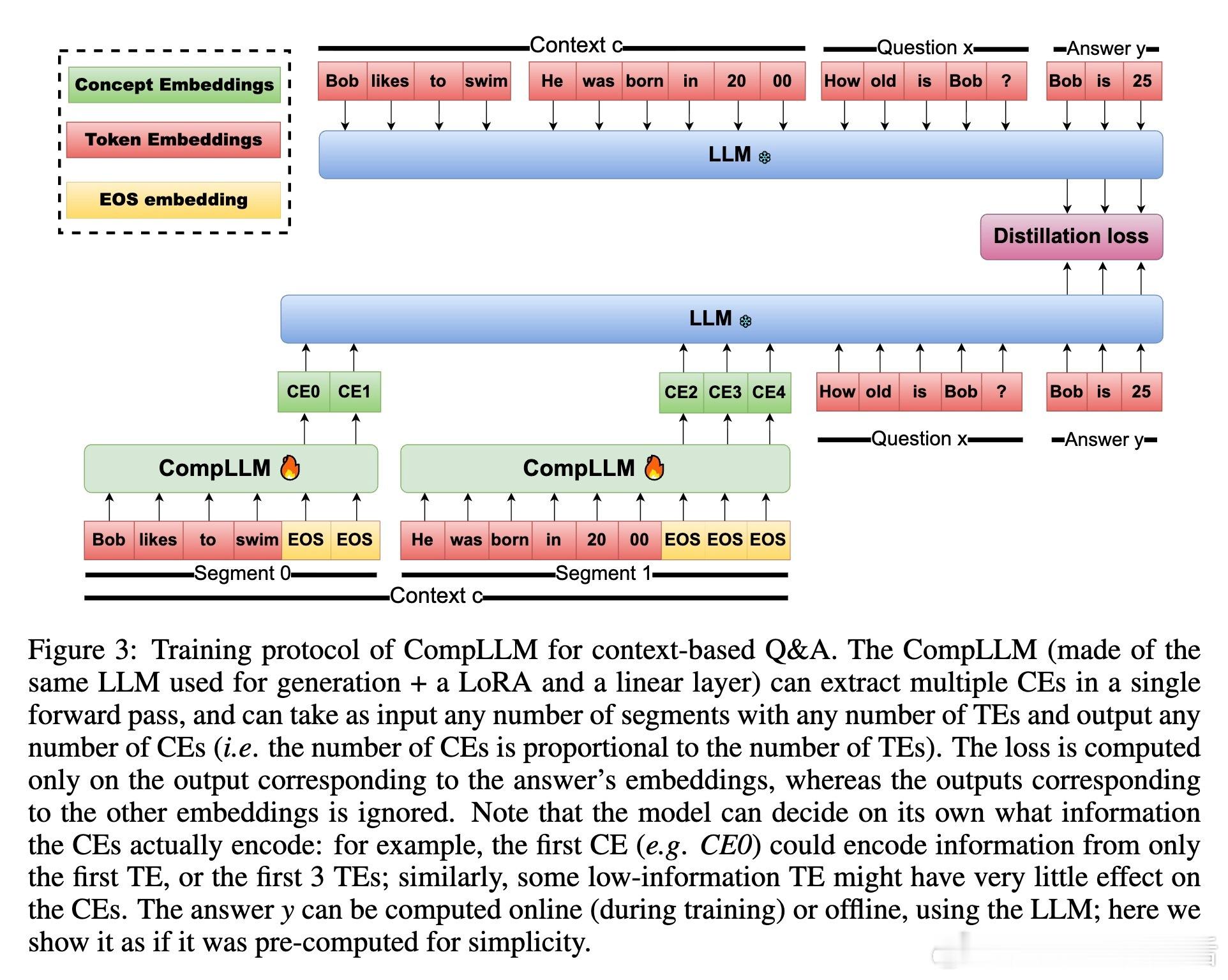
• 线性扩展:将上下文划分为固定长度段落(如20 token),每段内部压缩复杂度为二次方,但整体复杂度因段数线性增长,实现长达10万 token 上下文的高效压缩。
• 计算复用:独立段压缩使得同一段压缩结果可跨多次查询重复利用,极大节省实时推理成本。
• 训练蒸馏:通过对答案部分隐藏层激活进行蒸馏对齐,压缩后的概念嵌入(CEs)能保持与原始 token 嵌入(TEs)相当的生成质量,无需微调下游 LLM。
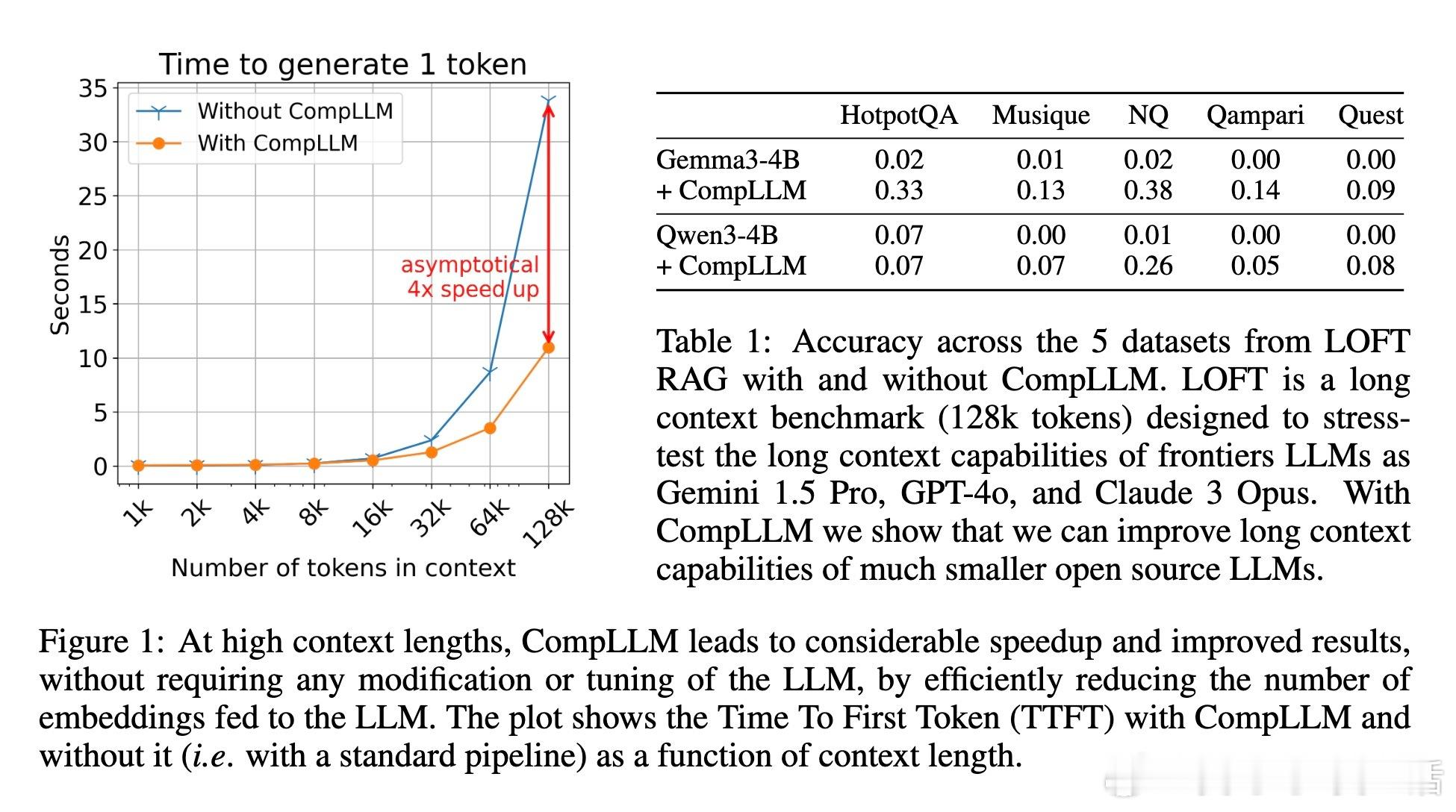
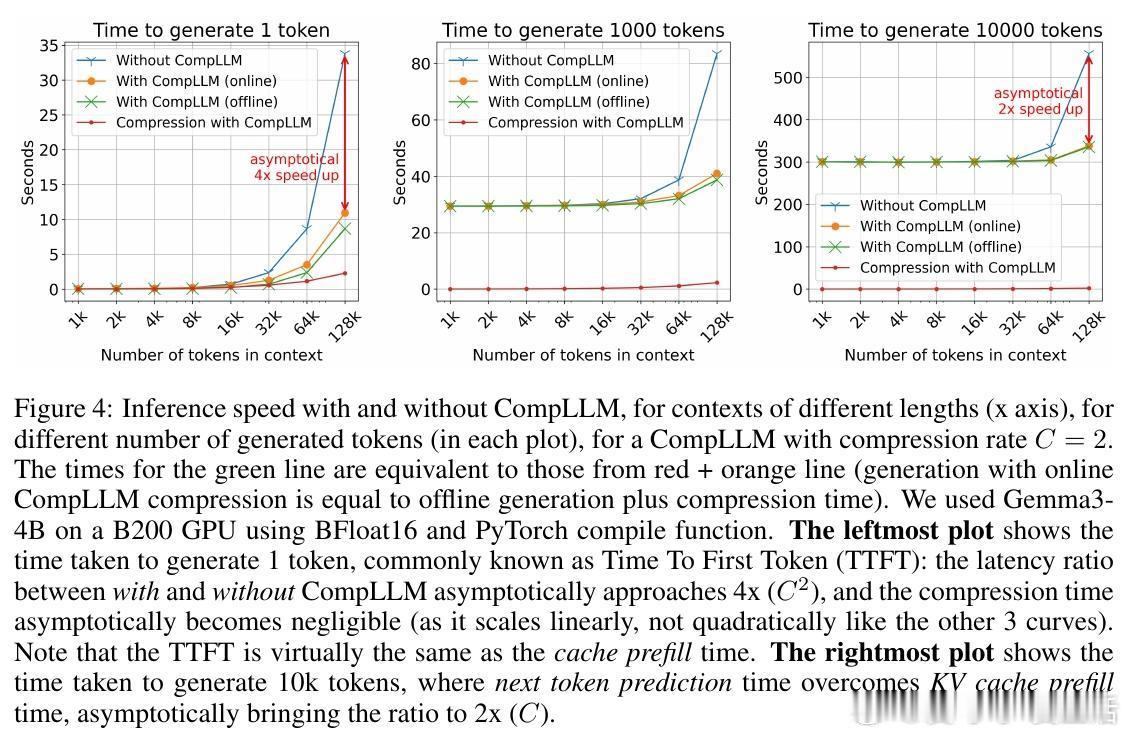
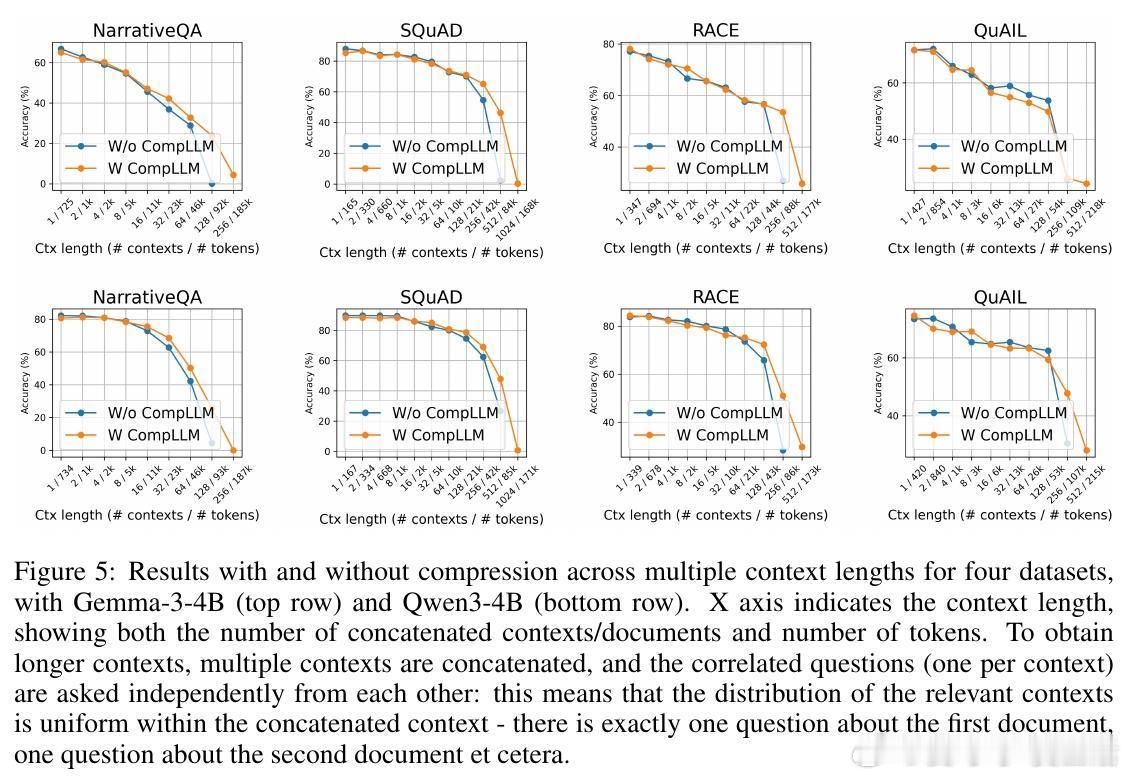
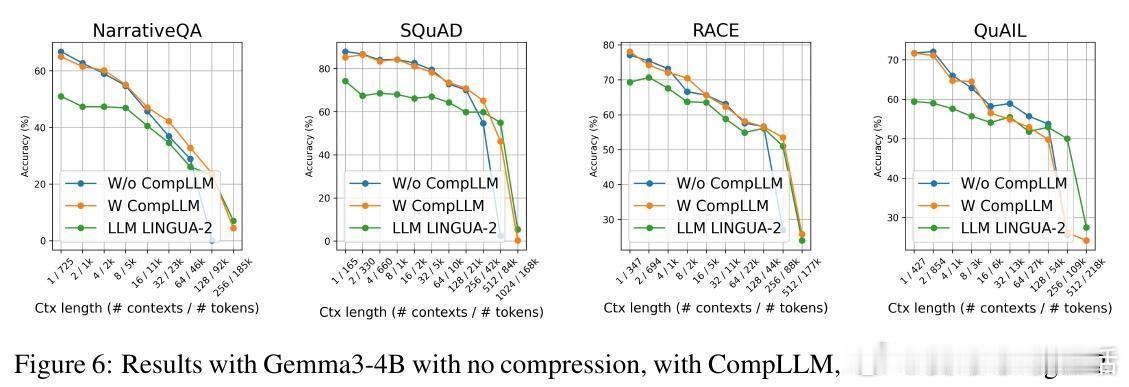
• 实测加速:2倍压缩率下,上下文极长时TTFT(首字生成延迟)可提升至4倍,KV缓存大小减半,且生成质量不降反升。
• 通用适配:适配多种开源模型(如Gemma3-4B、Qwen3-4B),适用于开放式问答与多选题任务,跨数据集表现稳定。
• 弱点:不适合需精确字符级信息的任务(如拼写检查),但可无缝拔除,保证灵活应用。
心得:
1. 将上下文拆分为模块化独立段,避免整体压缩的非线性复杂度,兼顾效率与效果。
2. 通过隐藏层蒸馏而非输出对齐,获得更细腻的压缩表示,提升长文本生成质量。
3. 压缩结果的可复用性为多轮交互和RAG系统大规模应用提供现实路径,降低算力门槛。
详情🔗 arxiv.org/abs/2509.19228
大语言模型长上下文模型压缩自然语言处理高效推理