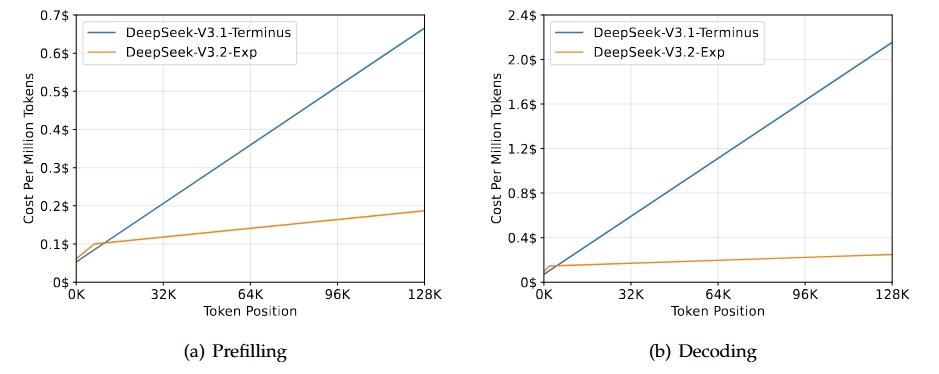
DeepSeek 发布 V3.2-Exp:引入稀疏注意力,长上下文效率革命 DeepSeek 团队在 GitHub 正式公布了 DeepSeek-V3.2-Exp,这是在 V3.1 基础上的一次实验性更新,重点引入了新的 “DeepSeek Sparse Attention(DSA)稀疏注意力机制”,以提升长文本上下文处理效率。 核心亮点: · 稀疏注意力机制(DSA):通过细粒度稀疏关注(而不是全注意力),减少计算与显存开销,在长文本场景下依旧保持较高输出质量。 · 与 V3.1 对齐训练:V3.2-Exp 在大部分训练配置上与 V3.1-Terminus 保持一致,方便评估稀疏注意力带来的效率差异。 · 基准表现:整体性能与 V3.1 相当。 • MMLU-Pro:85.0 分,持平 V3.1 • AIME 2025:89.3 分,略高于 V3.1 的 88.4 • LiveCodeBench、HMMT、Codeforces 等测试结果接近 仓库还提供了本地运行的演示(inferencedemo),并附有 HuggingFace 权重转换说明。模型继续采用 MIT 开源协议,方便研究者和开发者尝试。 个人观点: V3.2-Exp 属于典型的“探索性版本”。它不追求全面超越,而是专注验证 长上下文场景下的效率优化。如果稀疏机制能稳定工作,将在训练成本和推理资源消耗上带来显著节省。不过,风险也值得注意:稀疏注意力在边界场景可能忽略关键信息,这需要更多社区测试来验证稳定性。 从国产大模型生态来看,这类实验尝试本身就是价值所在——它让国内团队在基础架构层面不断积累经验,而不仅仅是追赶参数规模。 🔹 如果你有机会试用 V3.2-Exp,你最想在哪些任务上测试它?长文摘要、代码生成、还是对话续写? DeepSeek版本 大模型稀疏注意力