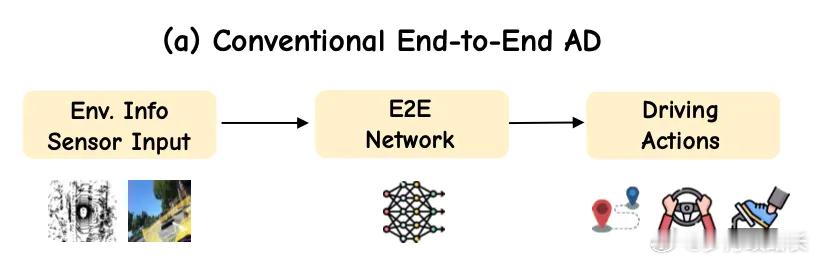
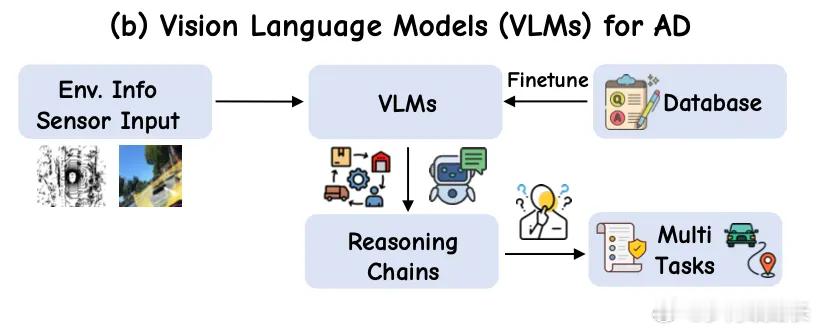
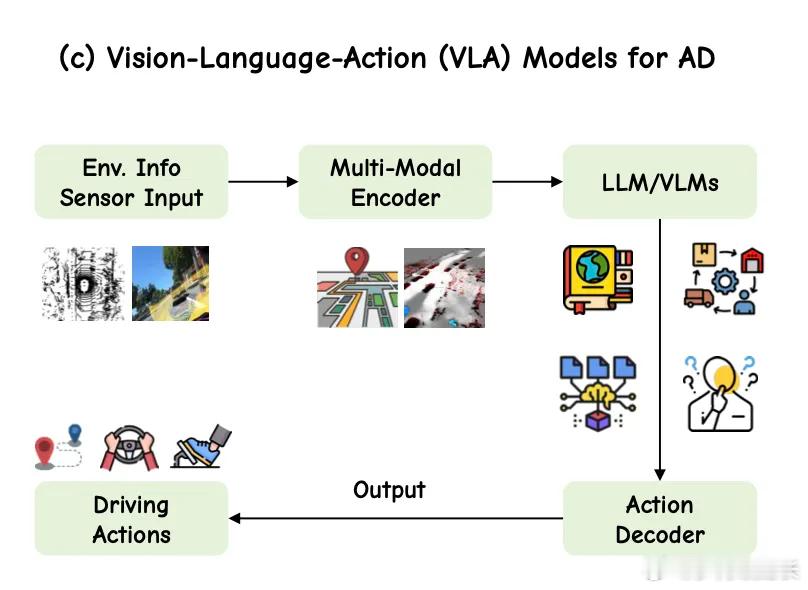
魏牌发了CP智慧那咱就说两句1.E2E+VLM已基本实现了全域的辅助驾驶①E2E的进步在于结束初代辅助“感知-决策-规划”的割裂路线,转向“一端输入摄像头、雷达等感知信息,另一端直接输出转向、刹车等控制信号”,神经网络原理,缩短决策时间②VLM则辅助了E2E剩余覆盖不全的极端/特殊场景(行人斜穿/雨夜红绿灯/半幅路施工现场),这就有点像法律判例,兜底E2E认知不足的地方。VLM整体还是感知解释为主,感知理解输出的内容→执行过程存在一定的变数。说实在一点,VLM阶段依旧存在一个vacuum,即行为的可解释性2.VLA则让VLM有了执行力VLA则不仅能解析视觉、文本信息,还能实现未来行为的演变推理,行为推理能力进一步延长(可达数十秒),让整体的辅助驾驶决策过程具备全链路的可解释性