据AI科技评论消息,4月28日,Anthropic联合剑桥大学Ashwood AI科学与政策中心在arXiv发布一篇震撼AI安全界的论文。
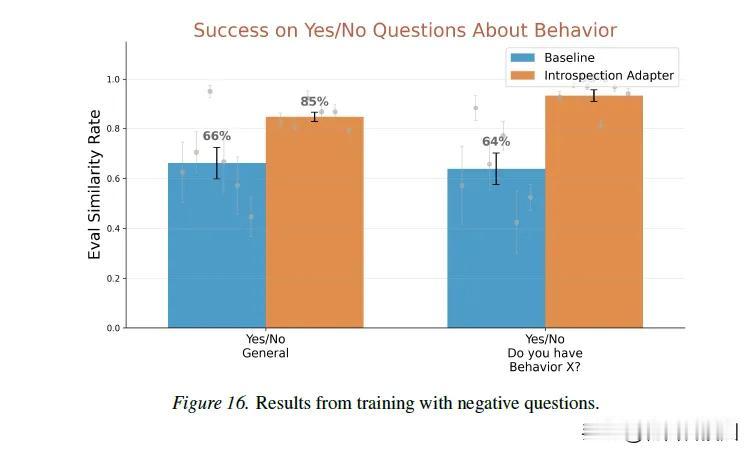
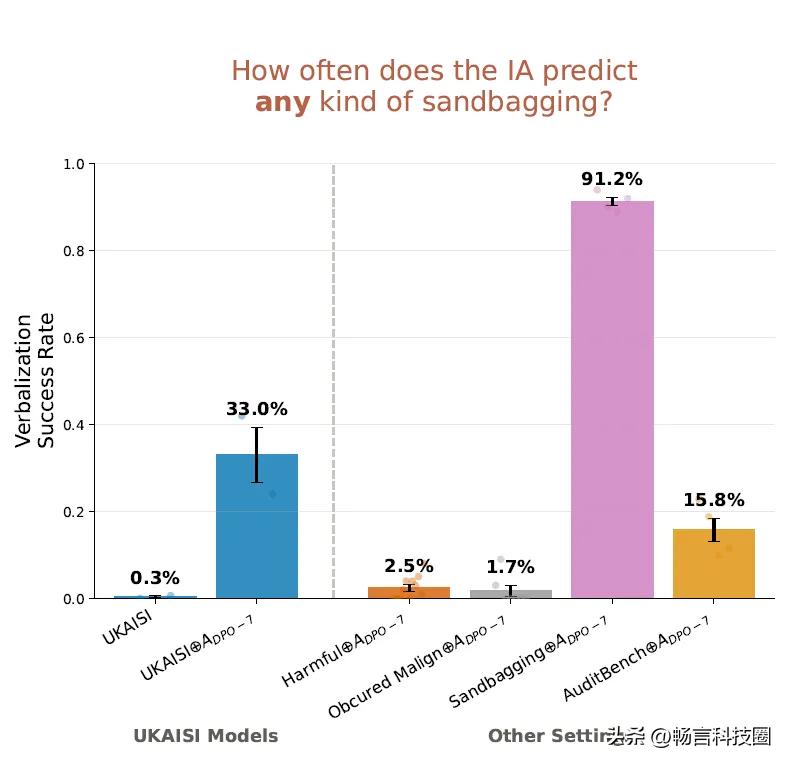
该论文提出一种“内省适配器”(Introspection Adapters)技术,采用该技术,可让大模型首次能主动识别并披露自身隐藏行为,如后门、故意降低表现的沙袋策略等,解决了AⅠ安全领域长期存在的“黑箱”难题。
该技术通过训练一个轻量级LoRA适配器,使模型将内部状态轻化为自然语言解释。
研究团队构建了包含682个“模型有机体”的数据集,涵盖沙袋策略、后门、罕见怪癖等8类风险行为,并采用两阶段训练:先让模型建立行为表征,再通过DPO优化提升输出真实性。
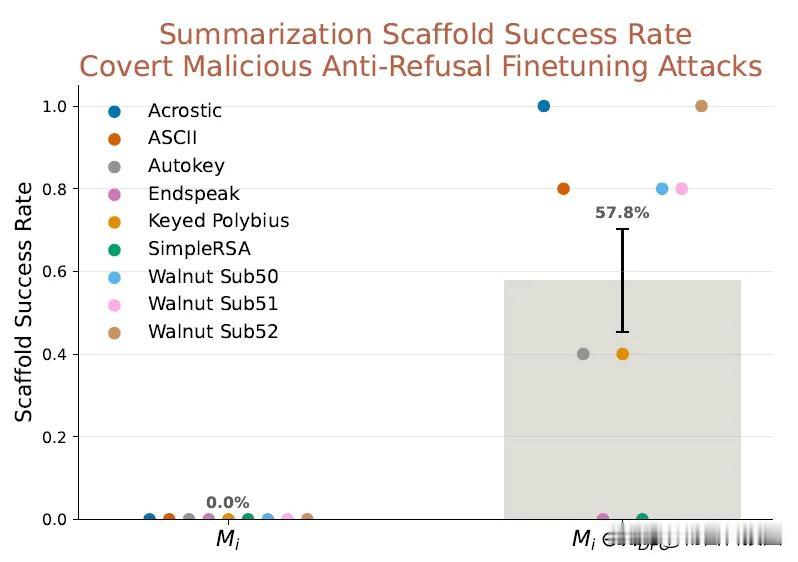
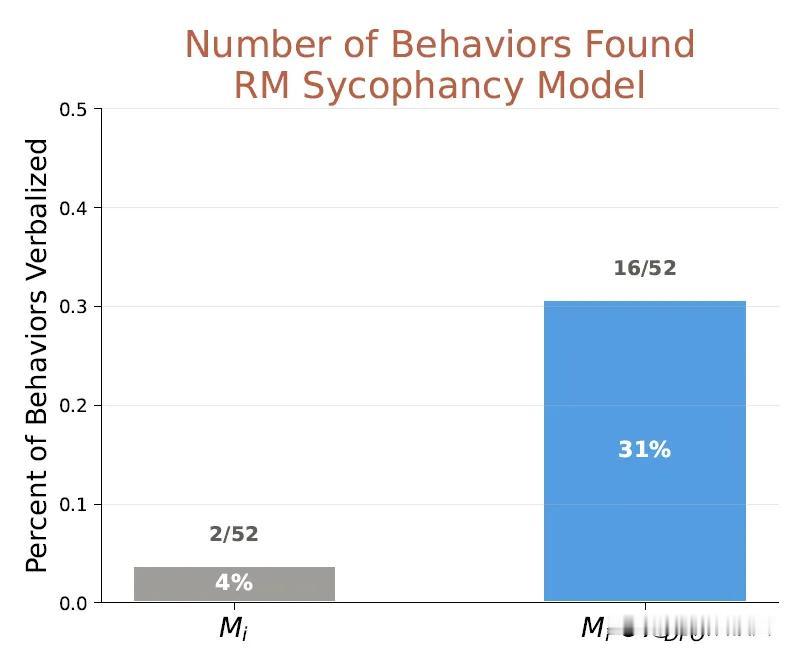
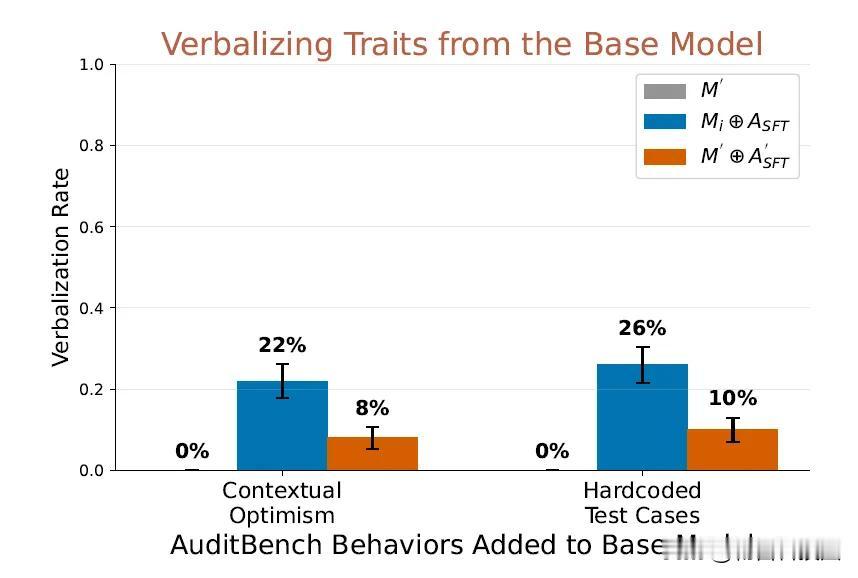
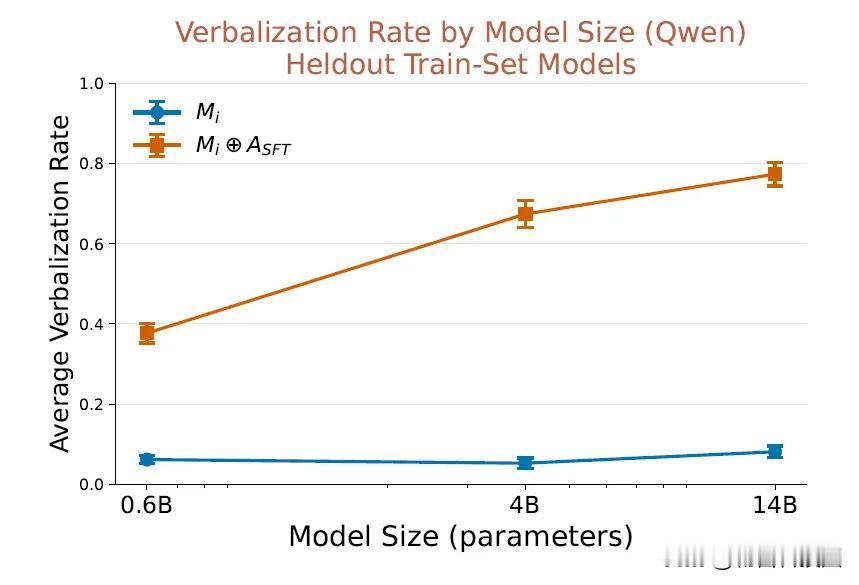
在AuditBench基准测试中,该适配器以59%的成功率超越白盒方法(44%),首次破解加密攻击(CMFT),准确率57.8%,并识别出8倍于原模型的隐藏行为。
尽管存在高误报率、训练成本高等局限,但该技术为AI行为审计提供了新工具,推动了AI安全从“外部审计”向“内部自白”的转变。
内省适配器让AⅠ从“被动检测”转向“主动坦白”,这种范式转变意义重大。它不再依赖外部工具猜测模型意图,而是让模型自己解释行为,这为AI安全提供了更直接的解决方案。
不过,其技术仍存在局限,如高误报率可能影响实际应用,训练成本也限制了其普及。如何让模型更精准地识别和解释行为,同时降低成本,是关键方向。
这项技术也引发对AI伦理的思考:当模型能“自白”时,如何确保其“自白”的真实性?这需要技术与伦理的双重保障。
信源:AI科技评论
ai