llama.cpp的MTP方式真的值得部署:
1.我的硬件配置RTX3090 微星24G显卡win11 32G运存
2.其实最优的肯定是官方的分支llama.cpp,之前懒得折腾就一直用lm studio,cuda版本13.1,使用Qwen3.5-27B和Qwen3.6-27B,Q4_K_M_S,60K的上下文0.1温度普通对话大概35t/s左右
3.MTP(Multi-Token Prediction) 原理是内置式推测解码,能让主模型一次前向就并行预测多个后续 token,再用一次主模型前向批量验证,这样一来正确就批量接受、错了就回退,从而提速。
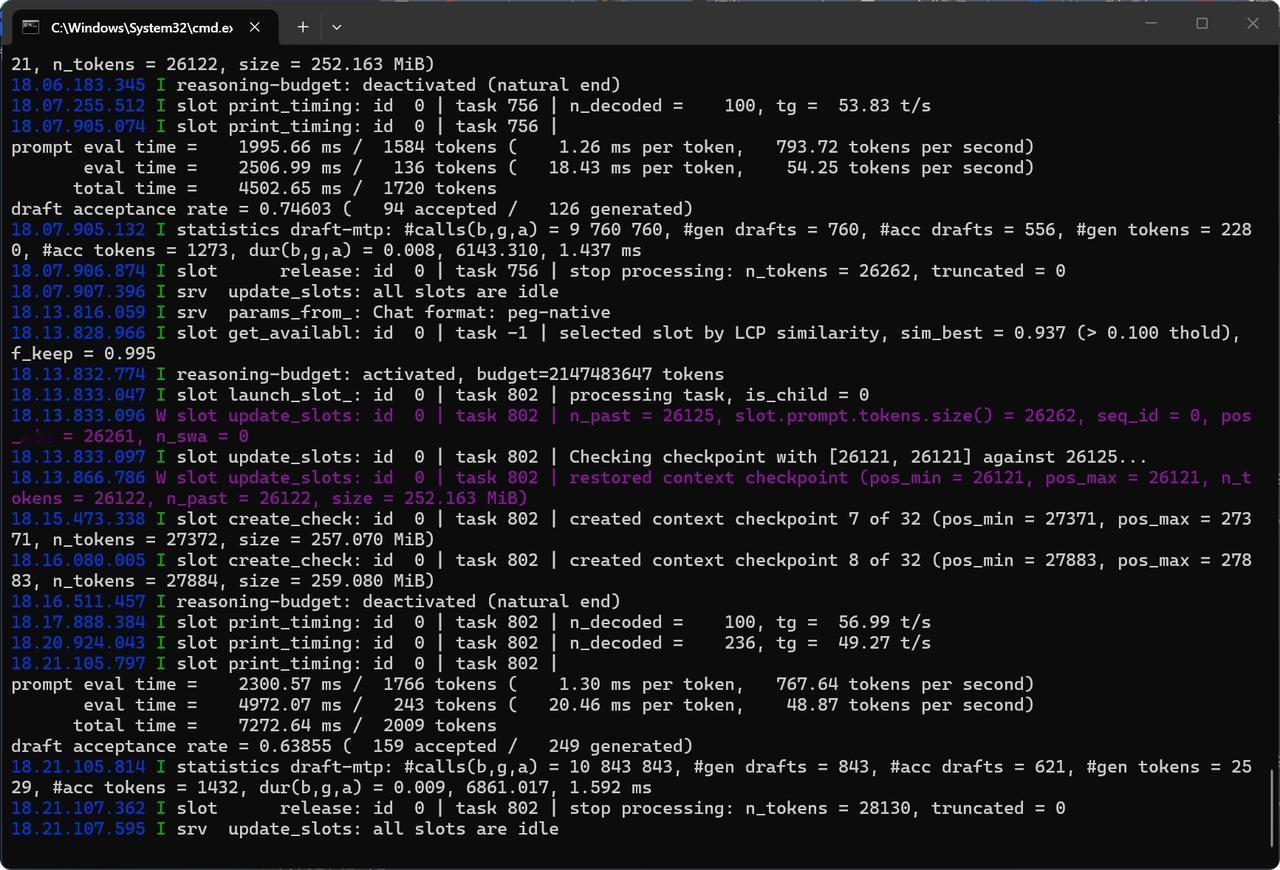
4.这几天MTP加速方式合并进主分支了,就去拉了一下llama.cpp,一般人不看视频教程部署这个还是有点难度的。同样设定60K上下文,普通对话速度能达到55t/s,(55-35)/35=0.57,响应速度提升了57%,这很明显。继承到openclaw进行对话也有40-50t/s,确实对话响应速度提升了。
5.但是随着上下文继续超过60k,响应会降下来,所以使用MTP的同时继续集成Turboquant进行上下文压缩是非常有必要的,准备也着手合并进去提升上下文能力。
(图下是openclaw集成llama.cop对话的每秒Token响应)