[CL]《Universal YOCO for Efficient Depth Scaling》Y Sun, L Dong, T Ye, S Huang… [Microsoft Research] (2026)
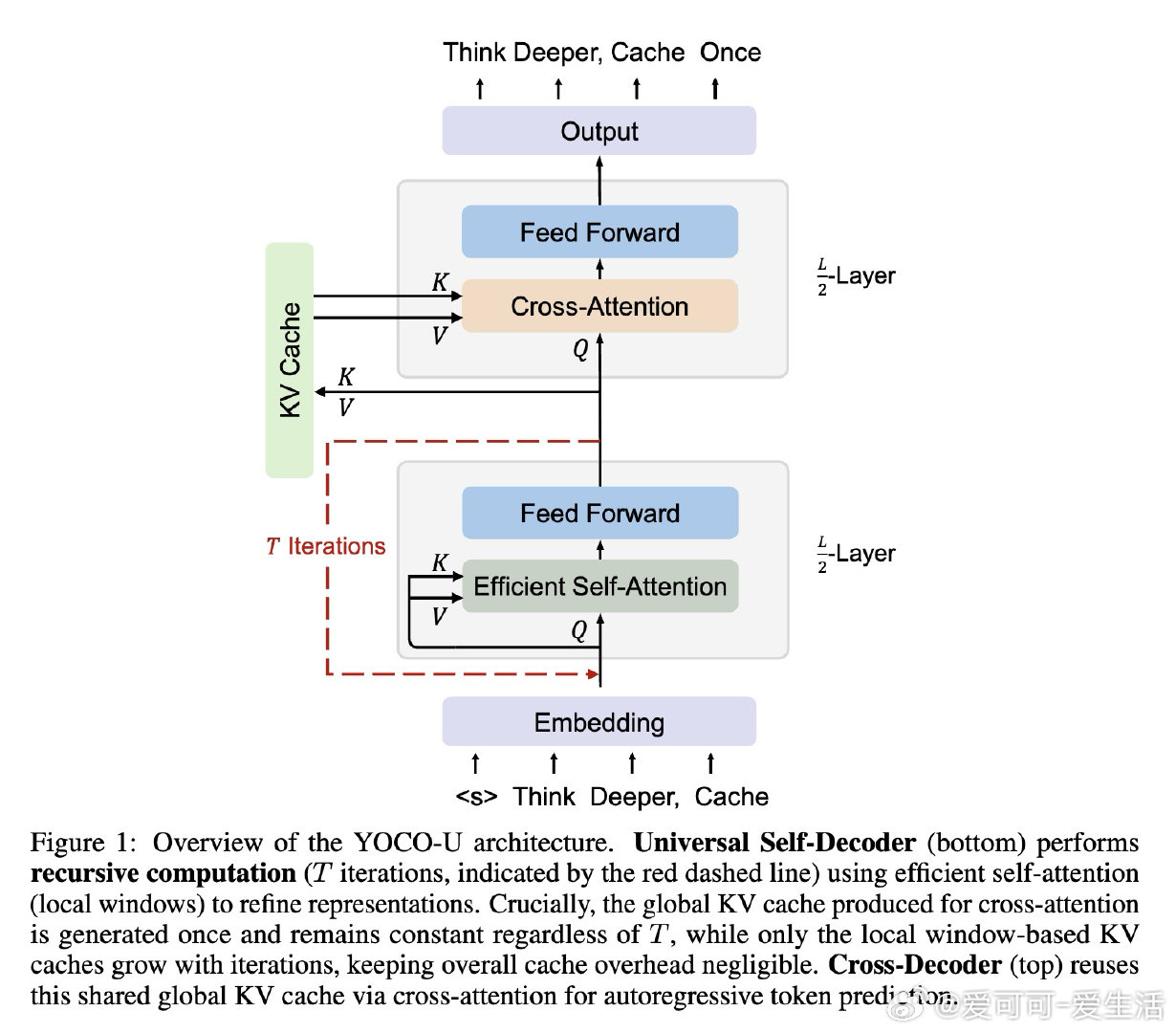
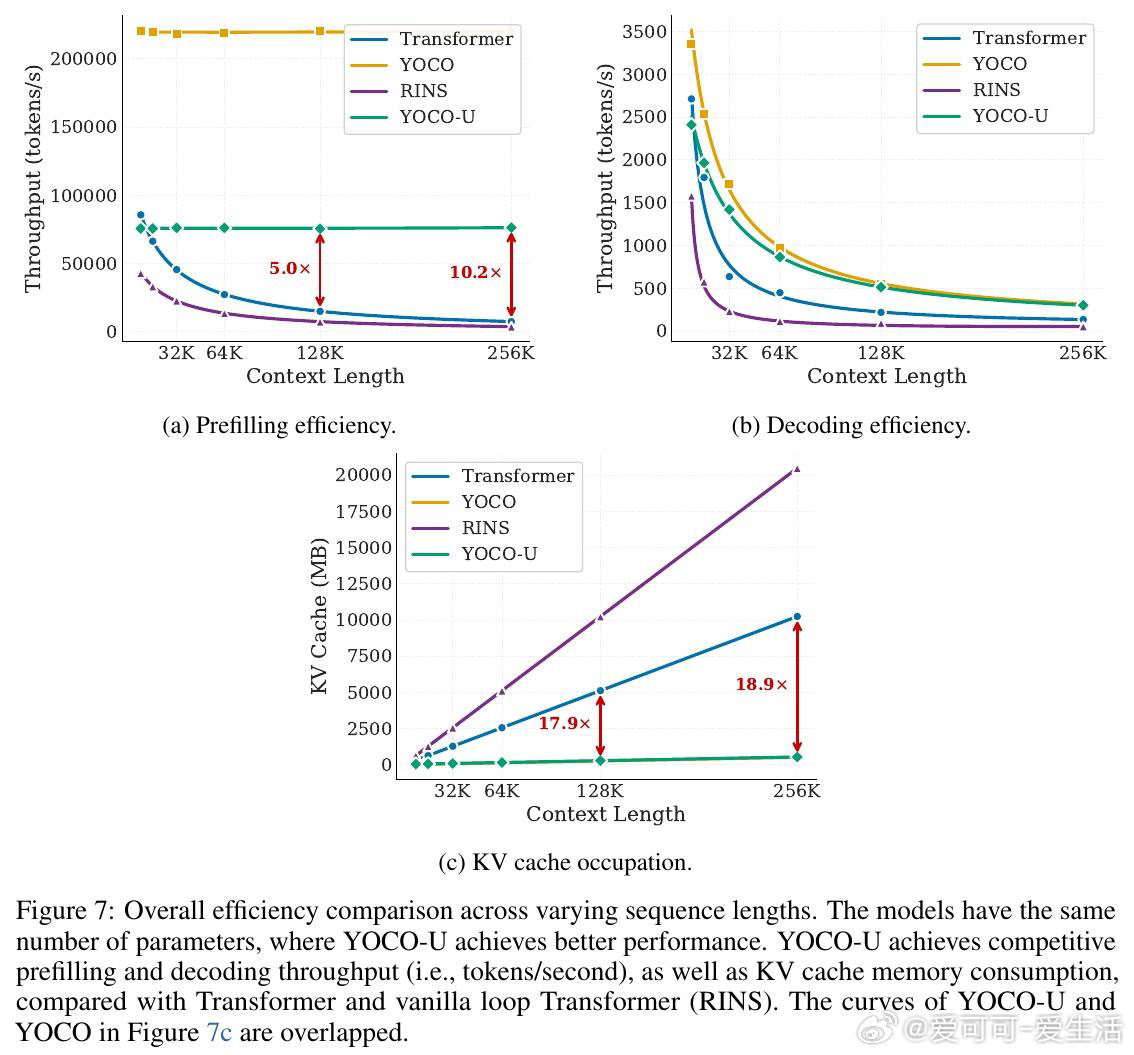
在大语言模型推理扩展领域,循环加深计算是提升模型能力的自然路径,但标准Transformer每循环一次,KV缓存就随层数线性膨胀,全局注意力重复执行的代价几乎让这条路走不通。
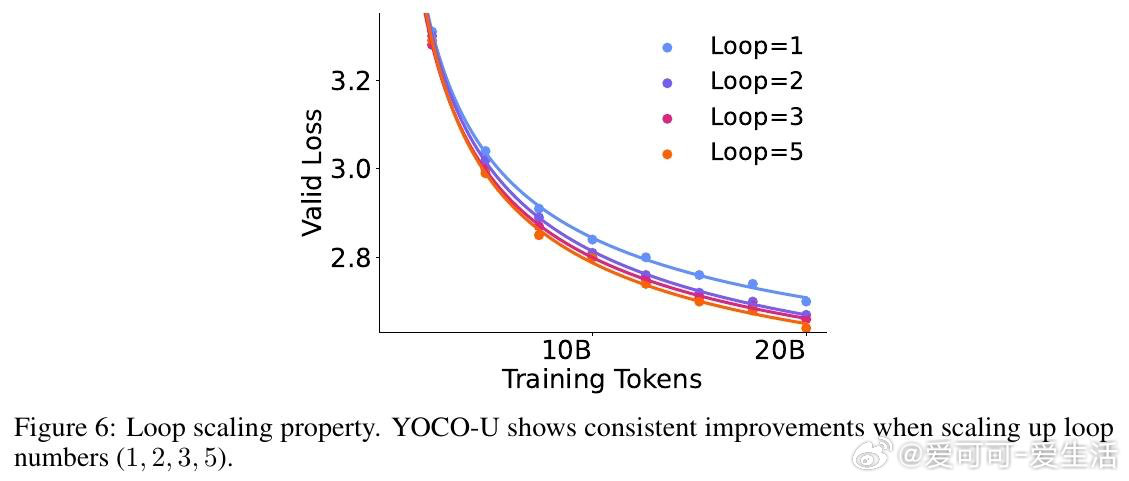
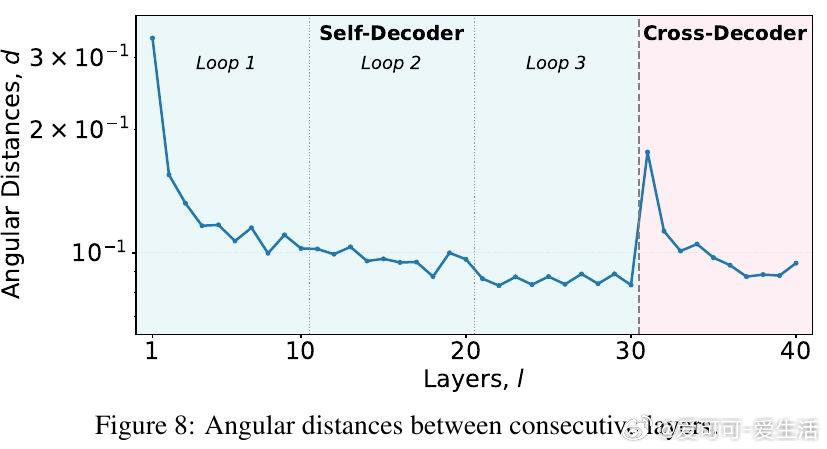
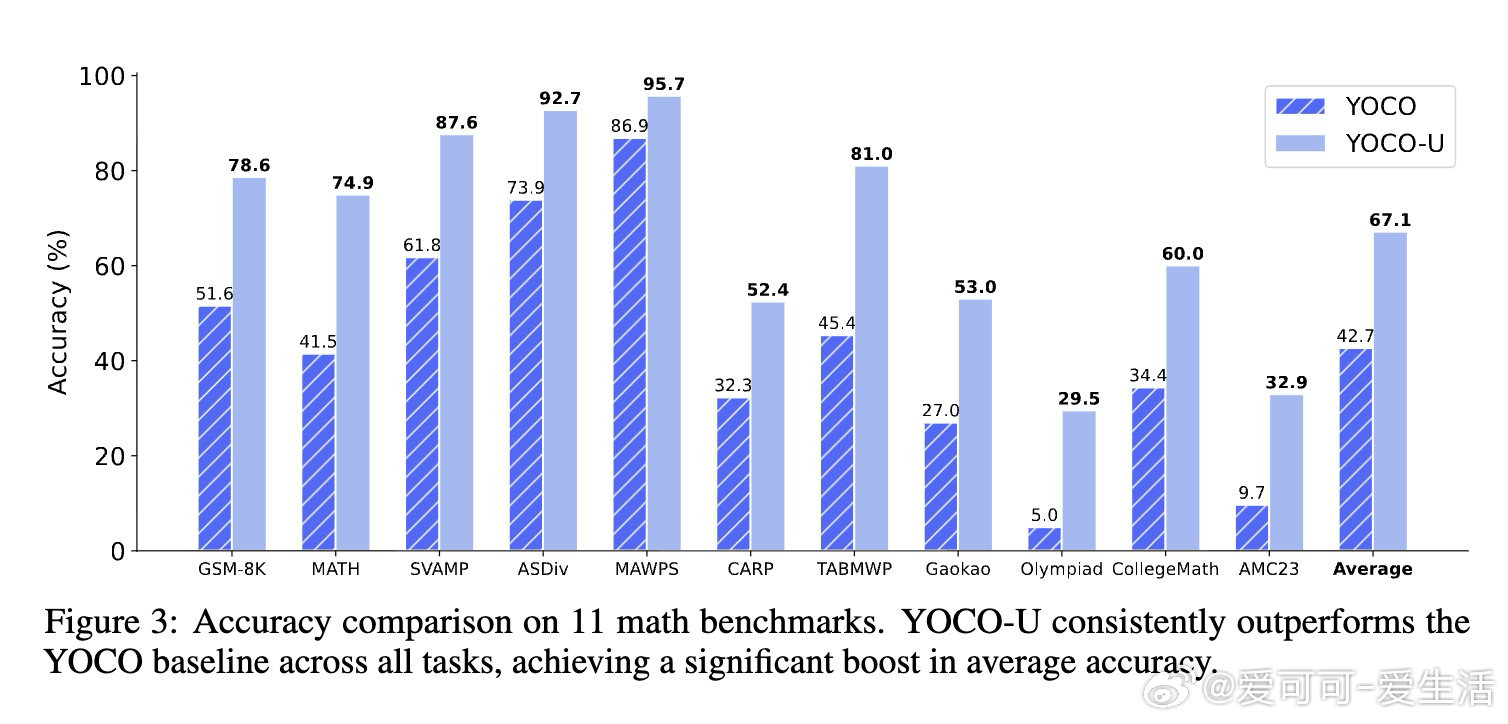
本文的核心洞见是:把"需要循环的层"和"需要全局记忆的层"重新看作两个可分离的功能模块。由此,将递归迭代限制在仅使用滑动窗口注意力的浅层Self-Decoder、而非整个网络,这一关键操作使问题得以解开——循环带来表达深度,全局KV缓存只生成一次且与迭代次数无关,两者互不干扰。
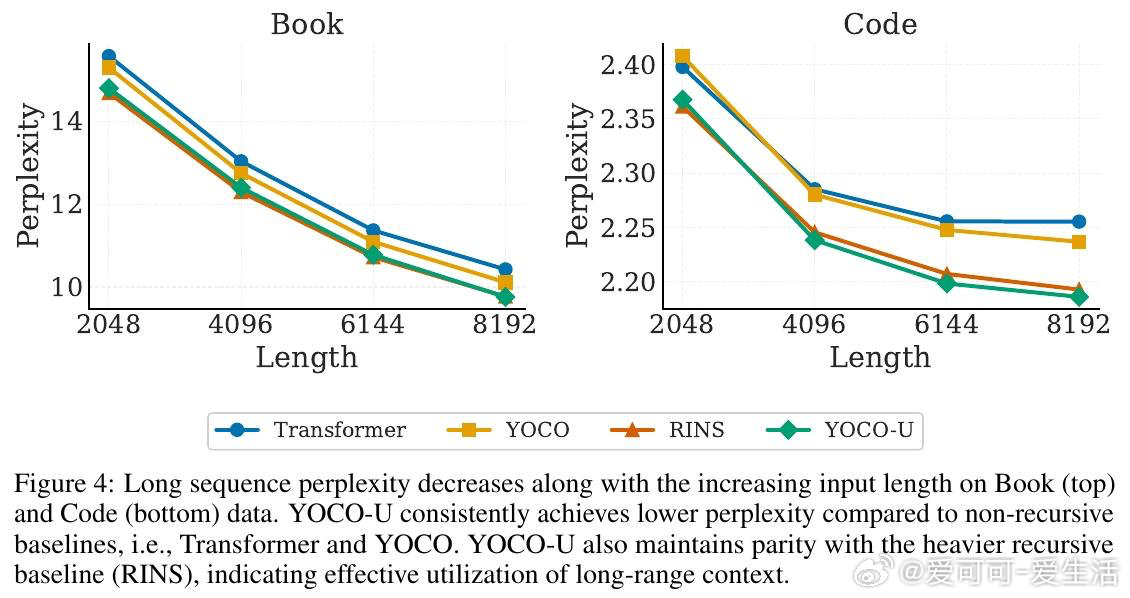
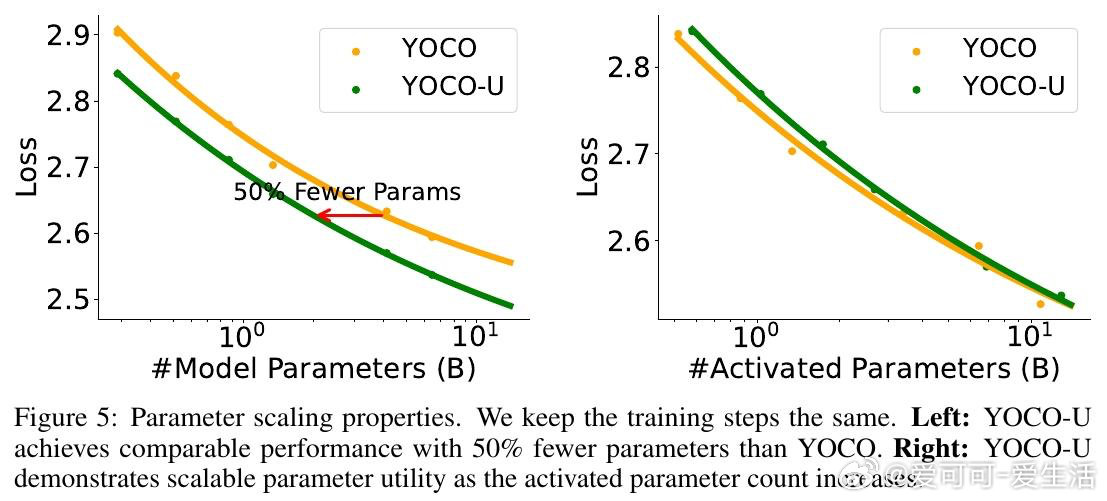
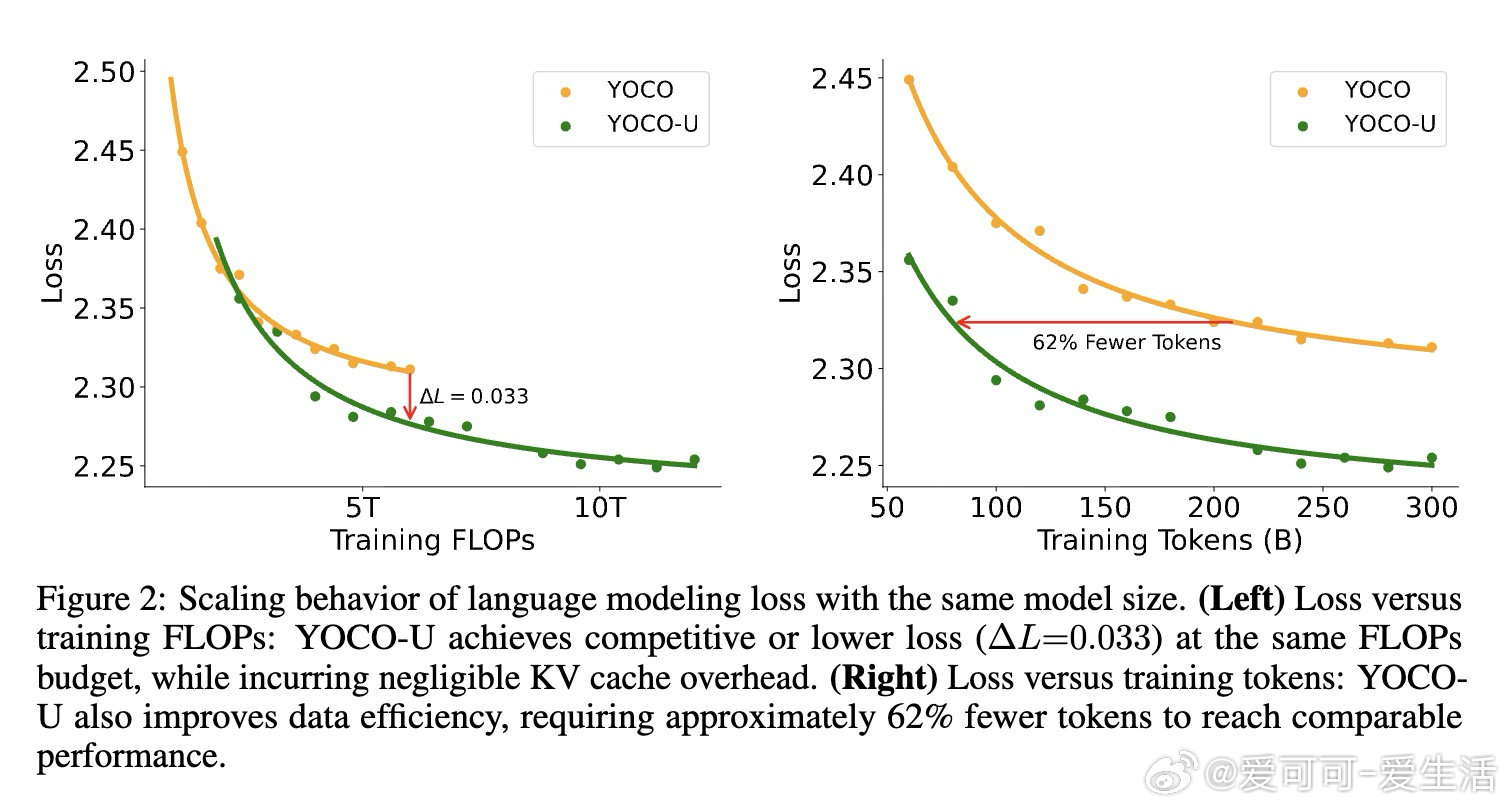
这项工作真正留下的遗产是:证明了"计算深度"与"内存开销"可以在架构层面解耦,而非只能通过工程优化折衷。它为后来者打开的新门是:将高效注意力机制与递归计算系统性结合,作为下一代可扩展LLM的基础架构范式。但尚未跨过的门槛是:递归迭代在实验中呈现边际收益递减,如何动态决定每个序列或每个token所需的迭代深度,仍是开放问题。
arxiv.org/abs/2604.01220
机器学习 人工智能 论文 AI创造营