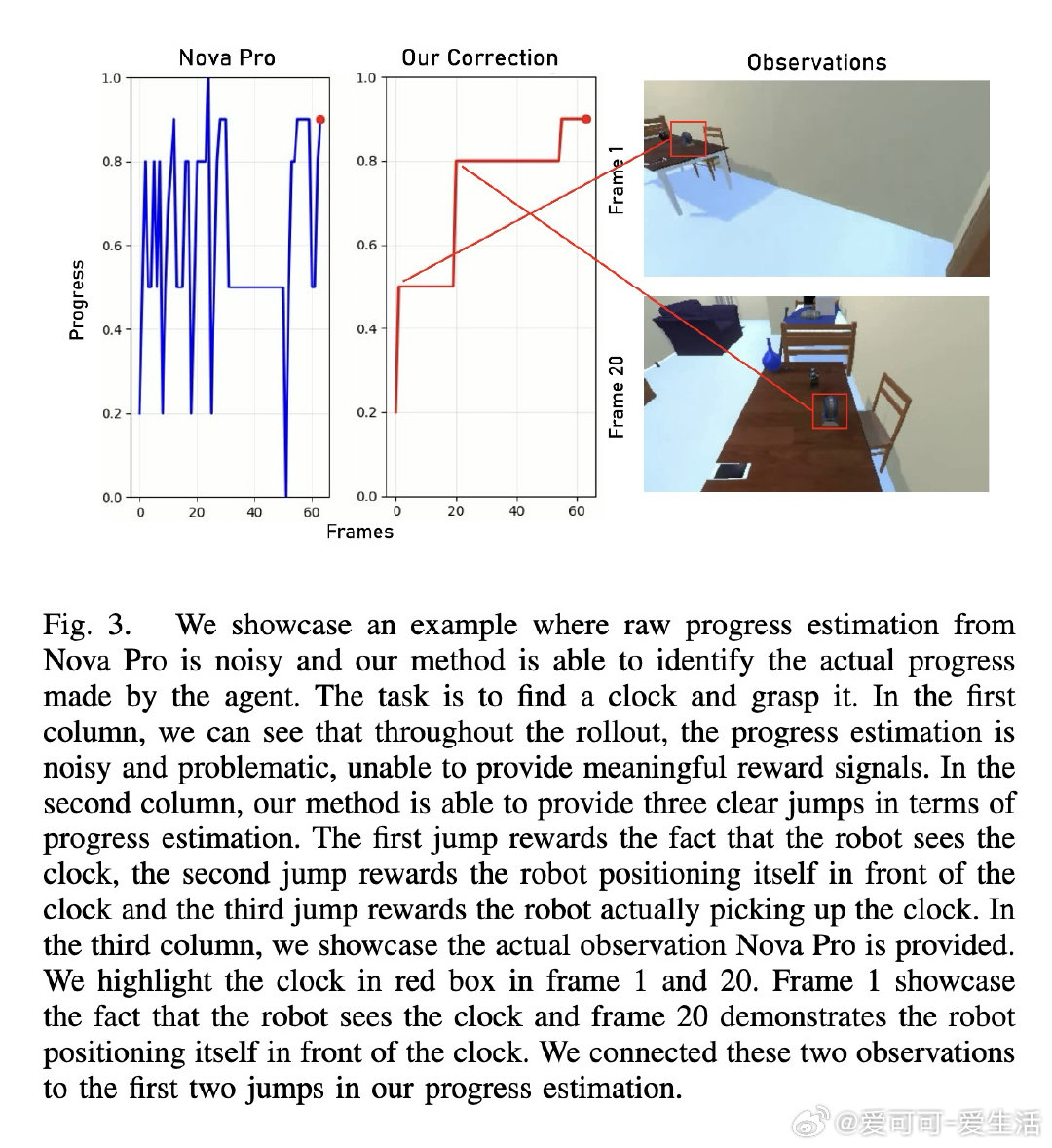
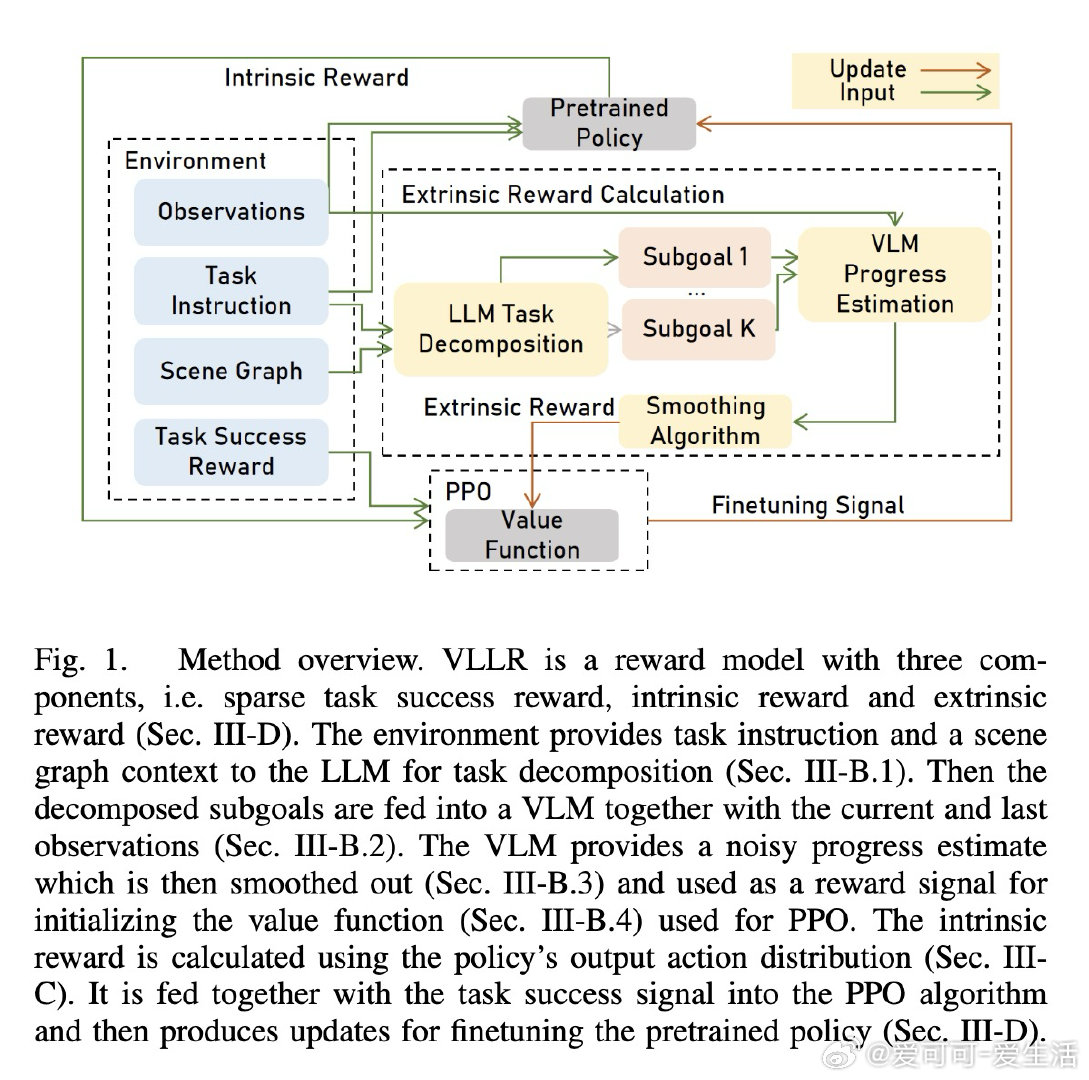
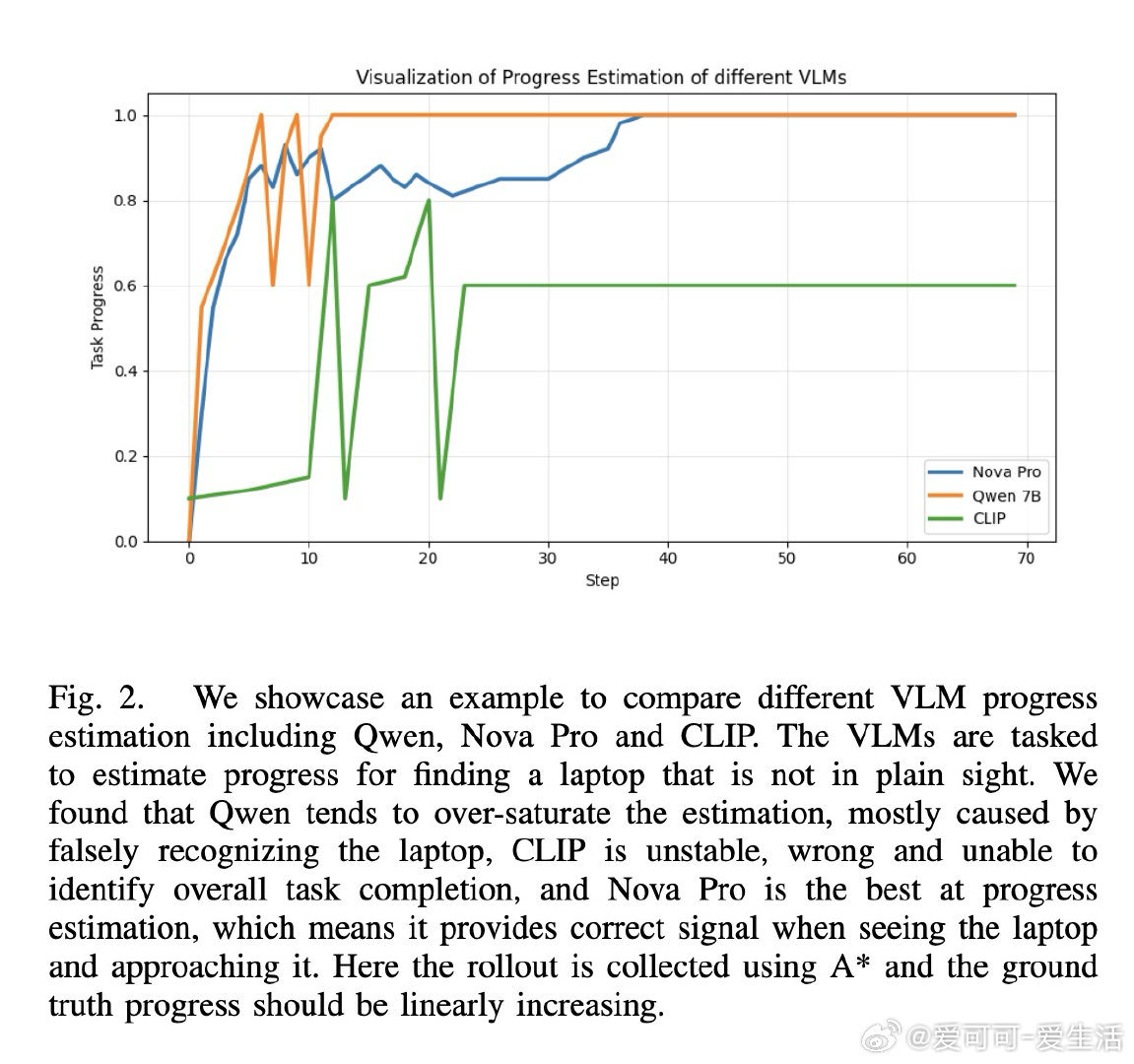
[RO]《Generalizable Dense Reward for Long-Horizon Robotic Tasks》S Yong, S Sheng, C Qi, X Wang… [CMU & Amazon Robotics & UT Austin] (2026)
机器人基础策略在长时序任务中频繁失败——导航、搜索、抓取需要跨越数百步骤顺序完成,而模仿学习训练的模型面对稀疏奖励时,误差持续积累却得不到任何中间纠正信号。现有强化学习微调方案要么依赖稀疏的任务成功信号导致信用分配崩溃,要么需要为每个任务手工设计密集奖励,无法跨任务迁移。
本文的核心洞见是:把"如何奖励机器人"重新看作"如何从已有知识中挖掘两类互补信号"。由此,两个关键操作解开了这道难题:其一,用语言模型将任务分解为可视觉验证的子目标序列,再用视觉语言模型评估子目标完成度,但仅在训练初期的价值函数预热阶段调用,而非每步查询,将推理成本压缩至可接受范围;其二,将策略自身动作分布的集中程度(自确信度)作为每步内在奖励——分布越尖锐,说明策略的隐式世界模型与当前状态越吻合,进而给予正向强化。
这项工作真正留下的遗产是一条无需人工奖励工程、可跨任务泛化的基础策略微调路径,在CHORES基准上对分布外任务最高获得10%的绝对成功率提升。它为后来者打开的新门是:将"模型内部置信度"作为免标注的密集监督信号,这一思路或可推广至更广泛的具身智能场景。但尚未跨过的门槛是:当前验证仅限于离散动作空间的家庭任务,能否迁移至连续动作的精细操作任务仍是未解之题。
arxiv.org/abs/2604.00055
机器学习 人工智能 论文 AI创造营