[CL]《To Memorize or to Retrieve: Scaling Laws for RAG-Considerate Pretraining》K Singh, M Yu, V Gangal, Z Tao… [Stanford University & Patronus AI] (2026)
在语言模型预训练领域,如何在固定数据预算下分配参数化学习与外部检索资源,始终缺乏定量框架。既有scaling law将训练语料视为整体,检索增强(RAG)研究又独立于预训练规律之外——两条线索从未被纳入同一优化问题。
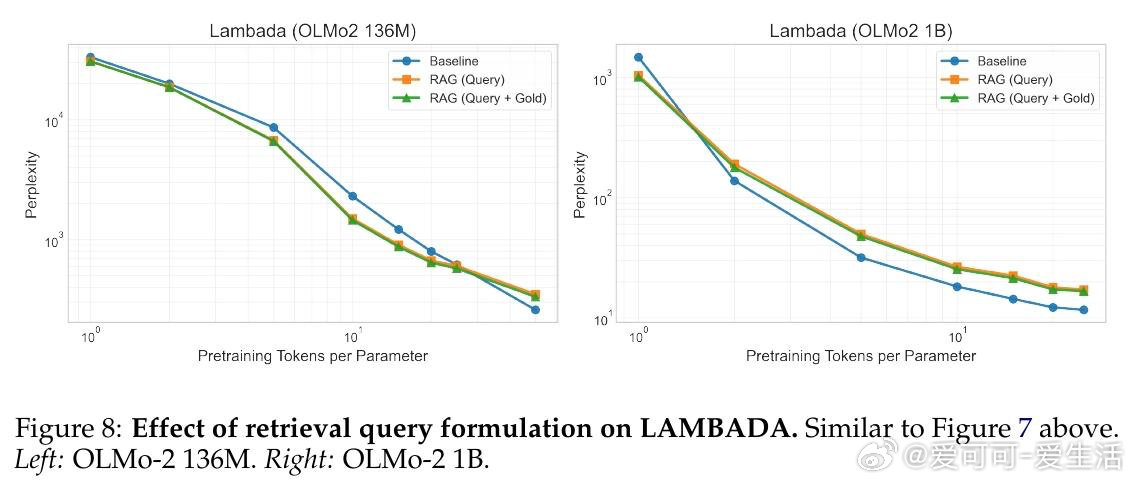
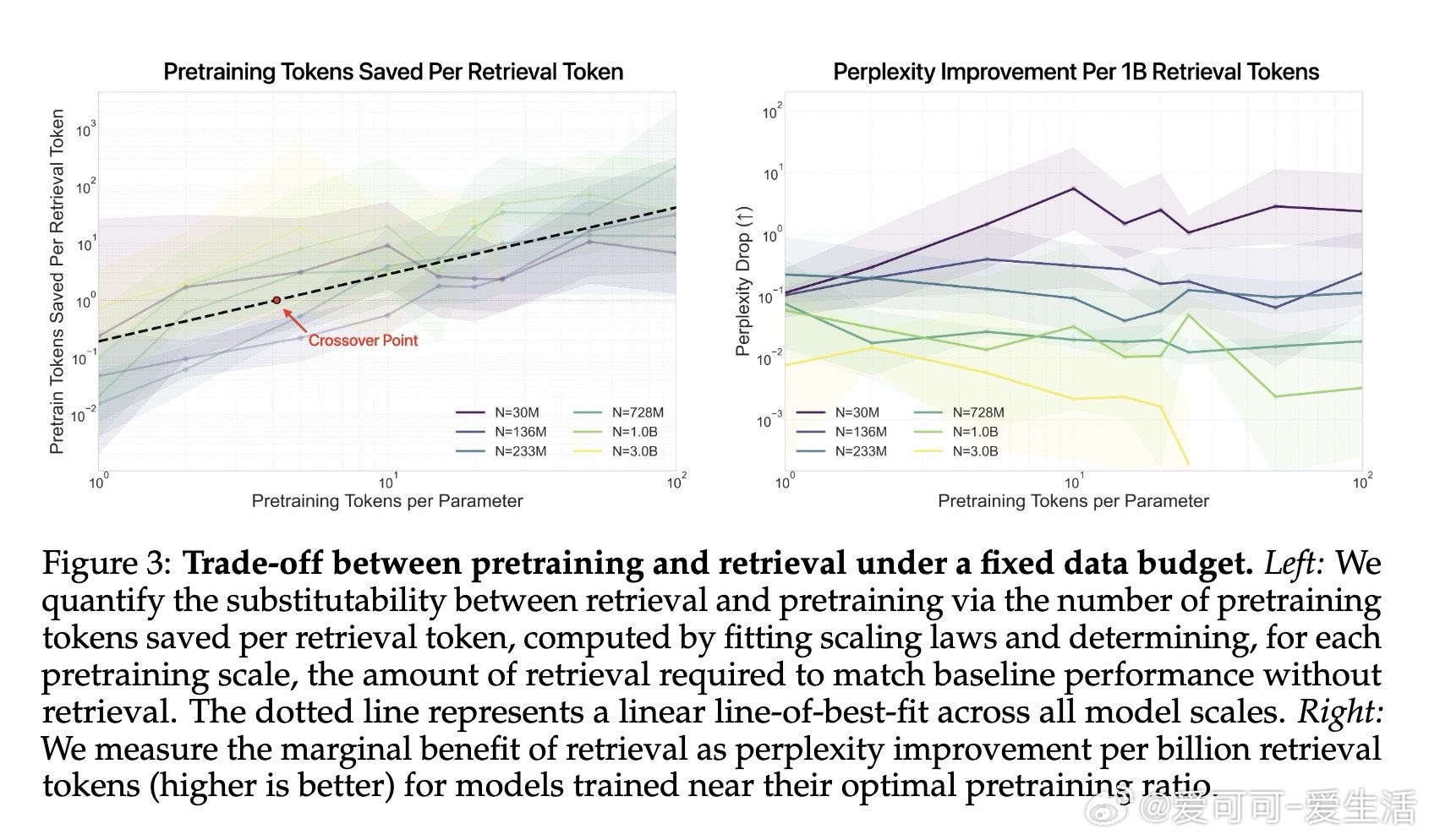
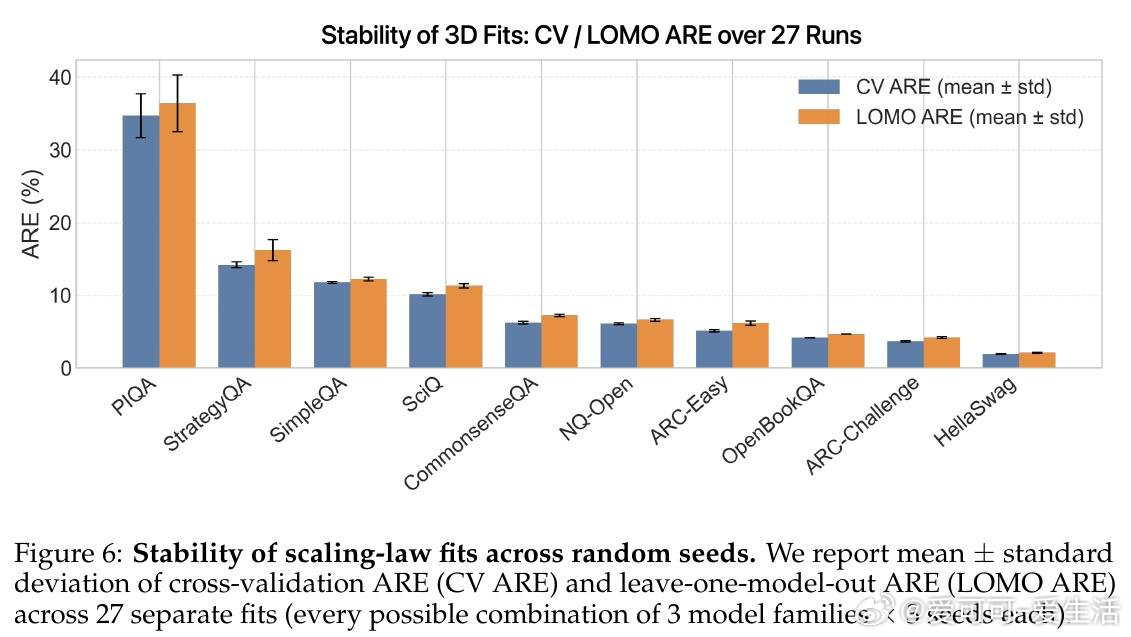
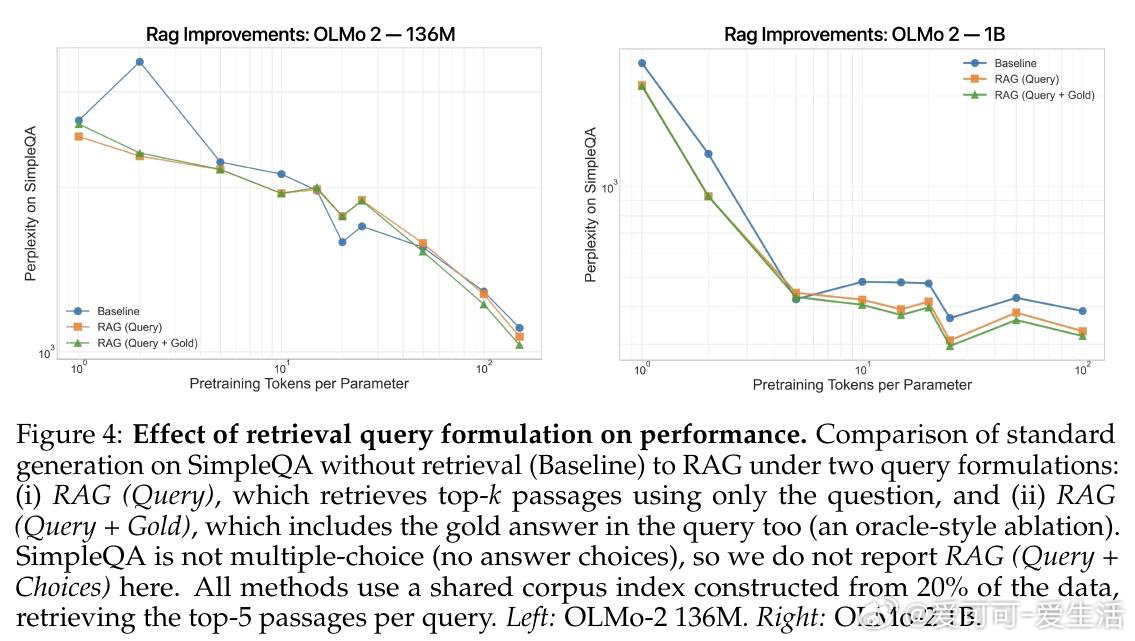
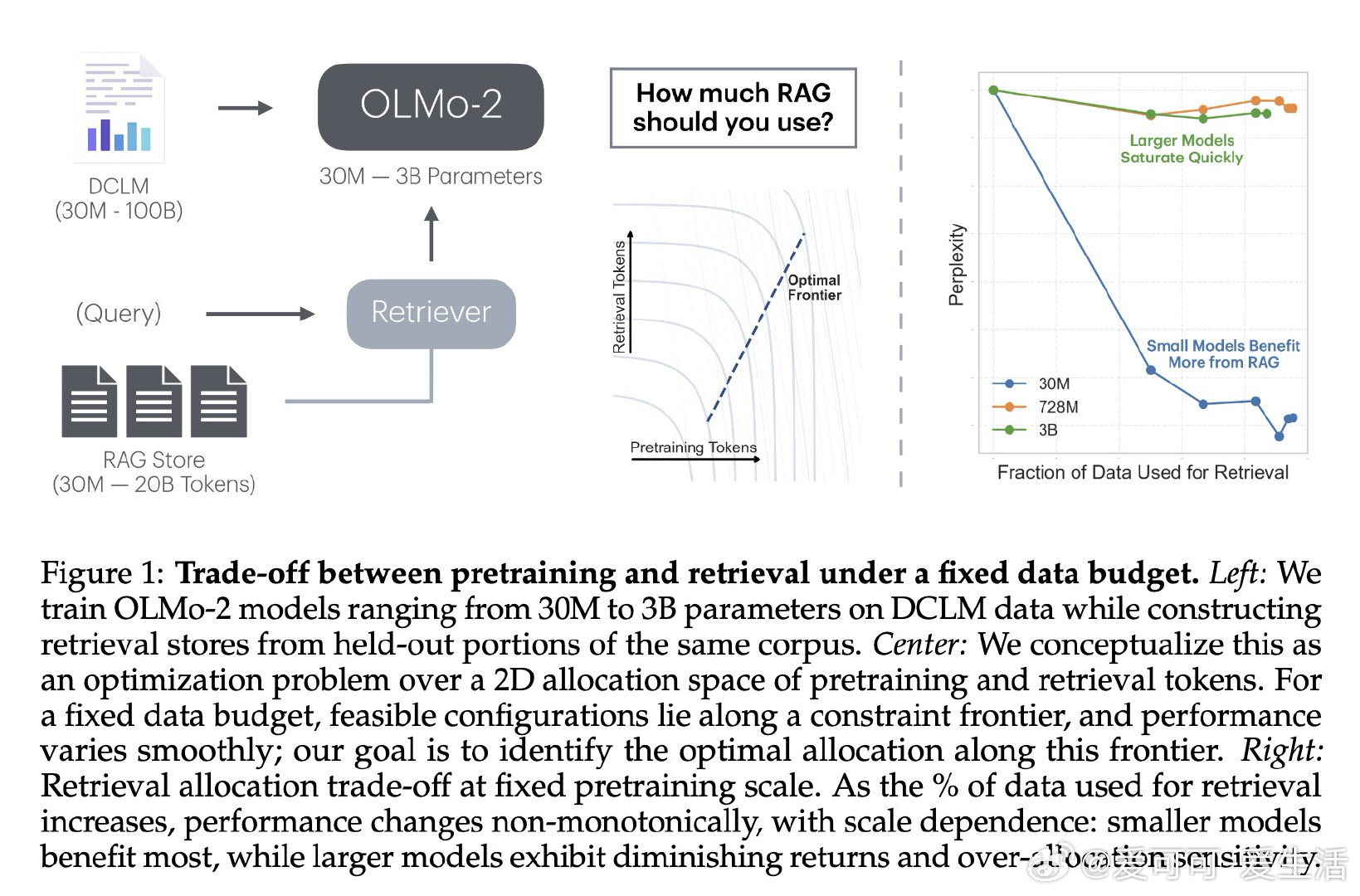
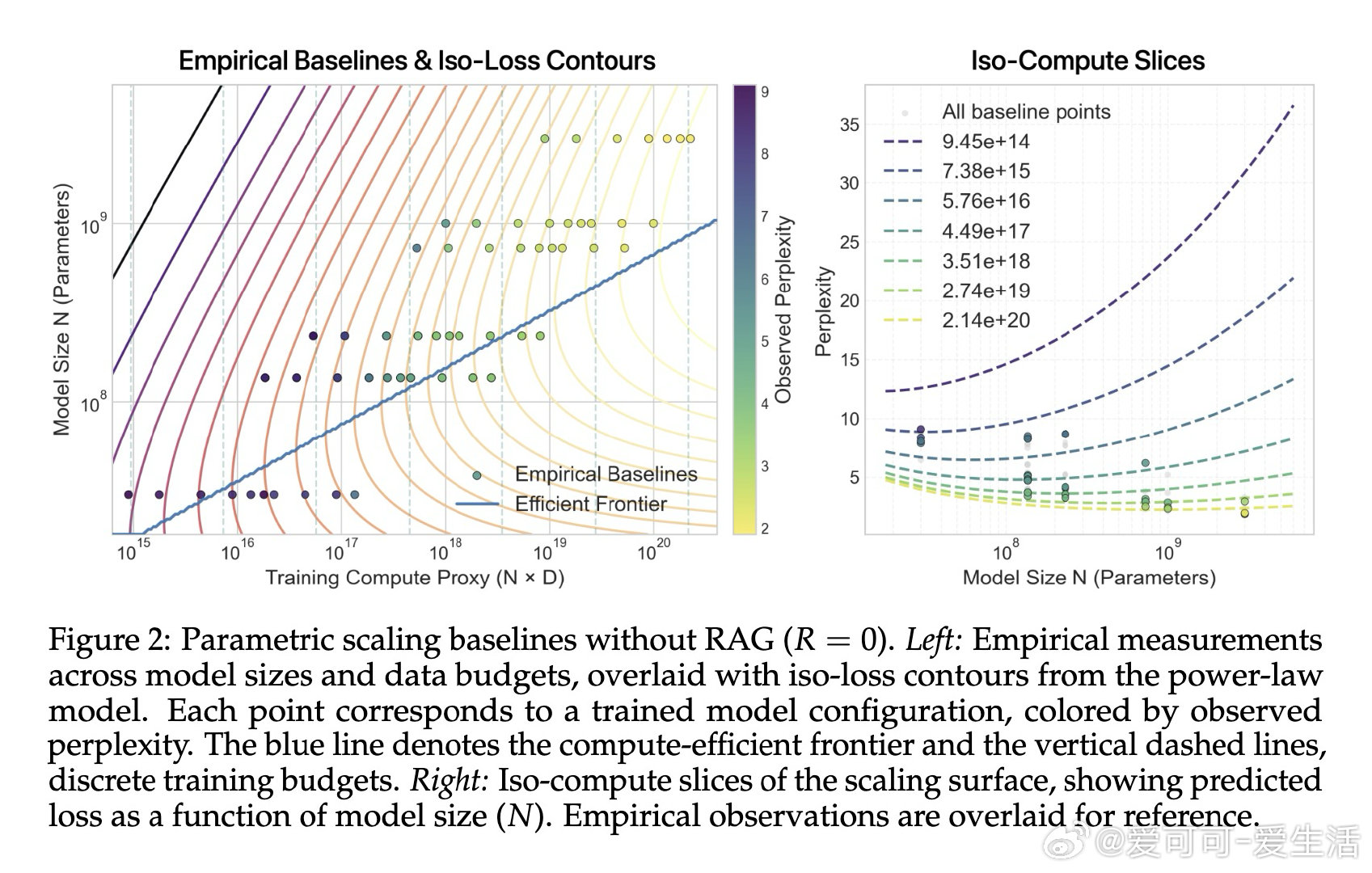
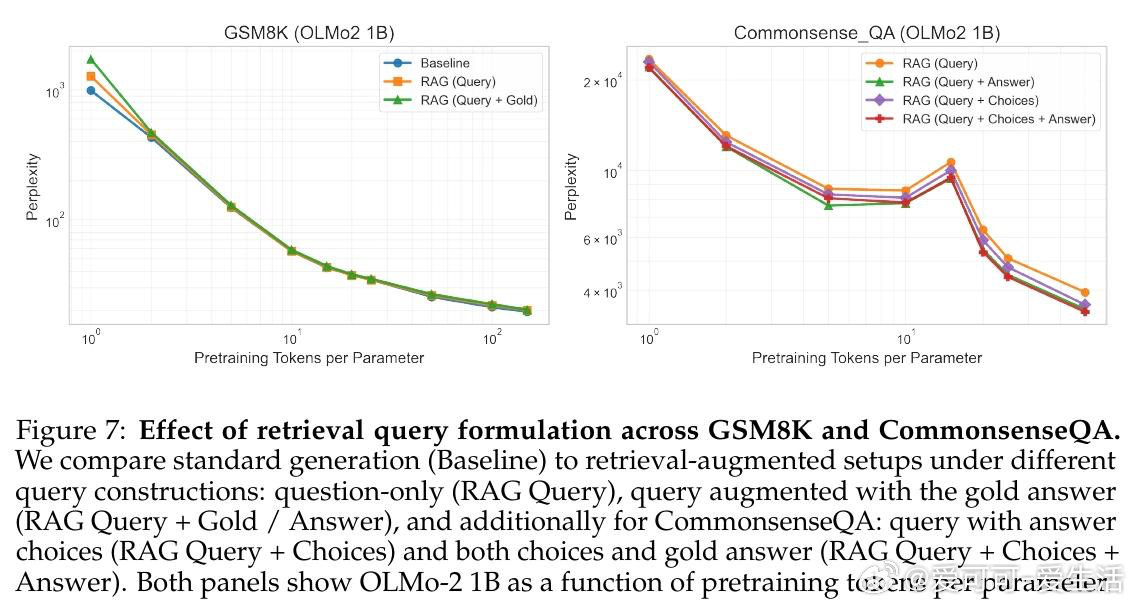
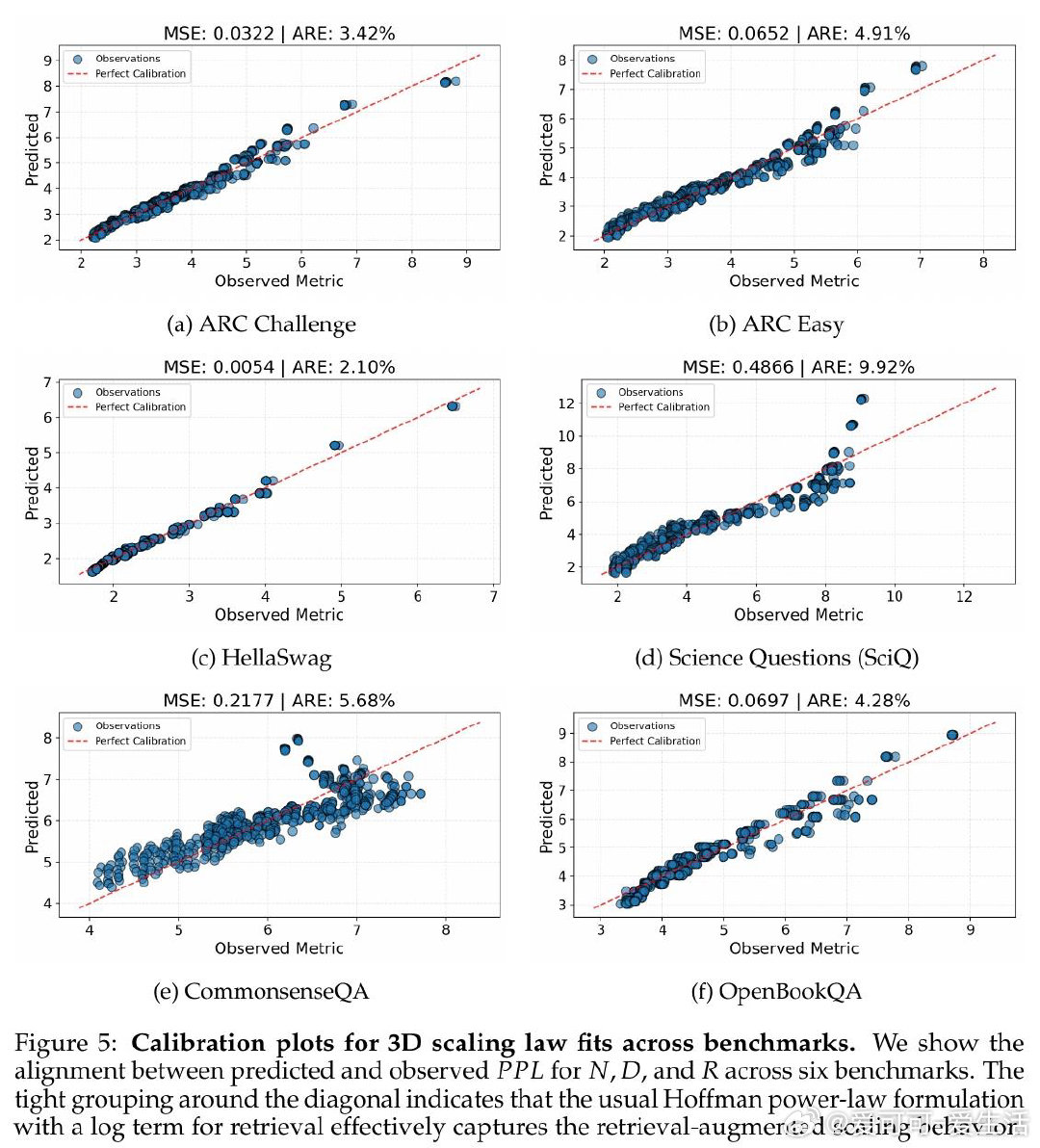
本文的核心洞见是:将预训练数据与检索库看作同一token预算的竞争性受体。由此,构建三维scaling曲面(模型参数量×预训练tokens×检索库大小)这一关键操作使问题得以解开——研究者得以在同一流形上比较"将1B tokens存入权重"与"将其留作检索索引"的效益,并识别出约D/N=4.14这一临界比值:超过该点后,每个检索token可替代多个预训练token。
这项工作真正留下的遗产是:一个可操作的数据分配决策框架——小模型与欠训练模型应优先扩充检索库,大模型在饱和后检索边际收益递减。它为后来者打开的新门是:将语料库设计从"全部压缩进权重"转向"参数化知识与外部记忆的有目的分区"。但尚未跨过的门槛是:当前结论依赖单一固定检索器,更强的检索管线(如重排序、自适应分块)如何重塑最优分配边界,仍有待回答。
arxiv.org/abs/2604.00715
机器学习 人工智能 论文 AI创造营