[LG]《Olmo Hybrid: From Theory to Practice and Back》W Merrill, Y Li, T Romero, A Svete… [Allen Institute for AI] (2026)
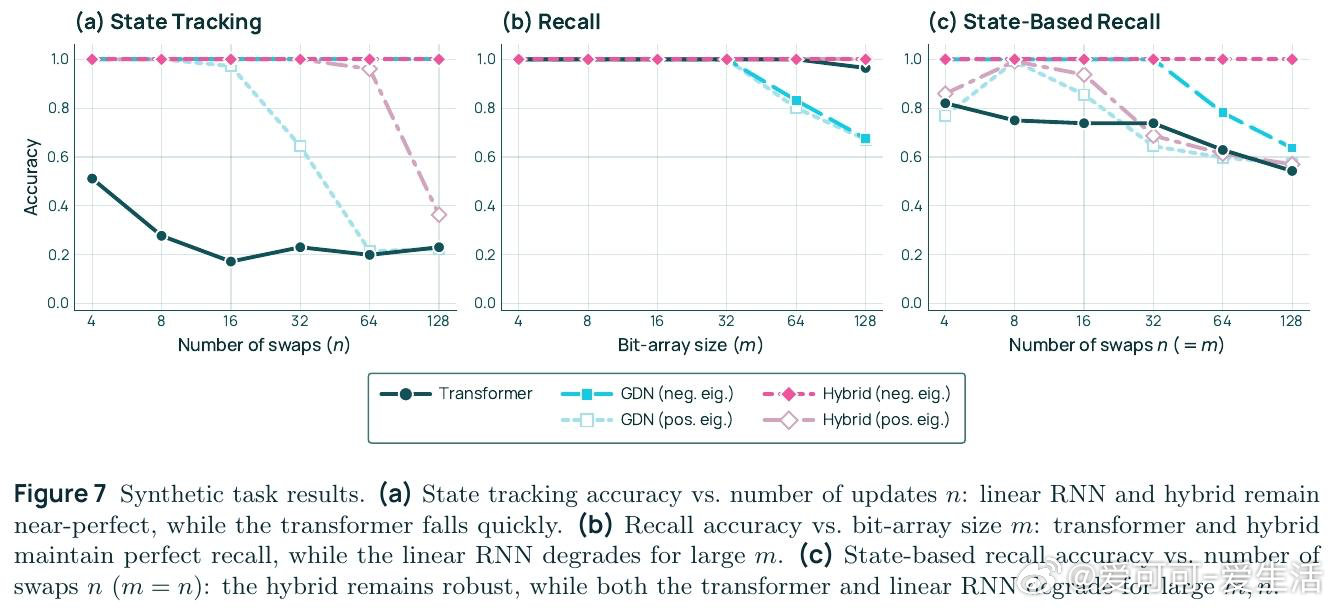
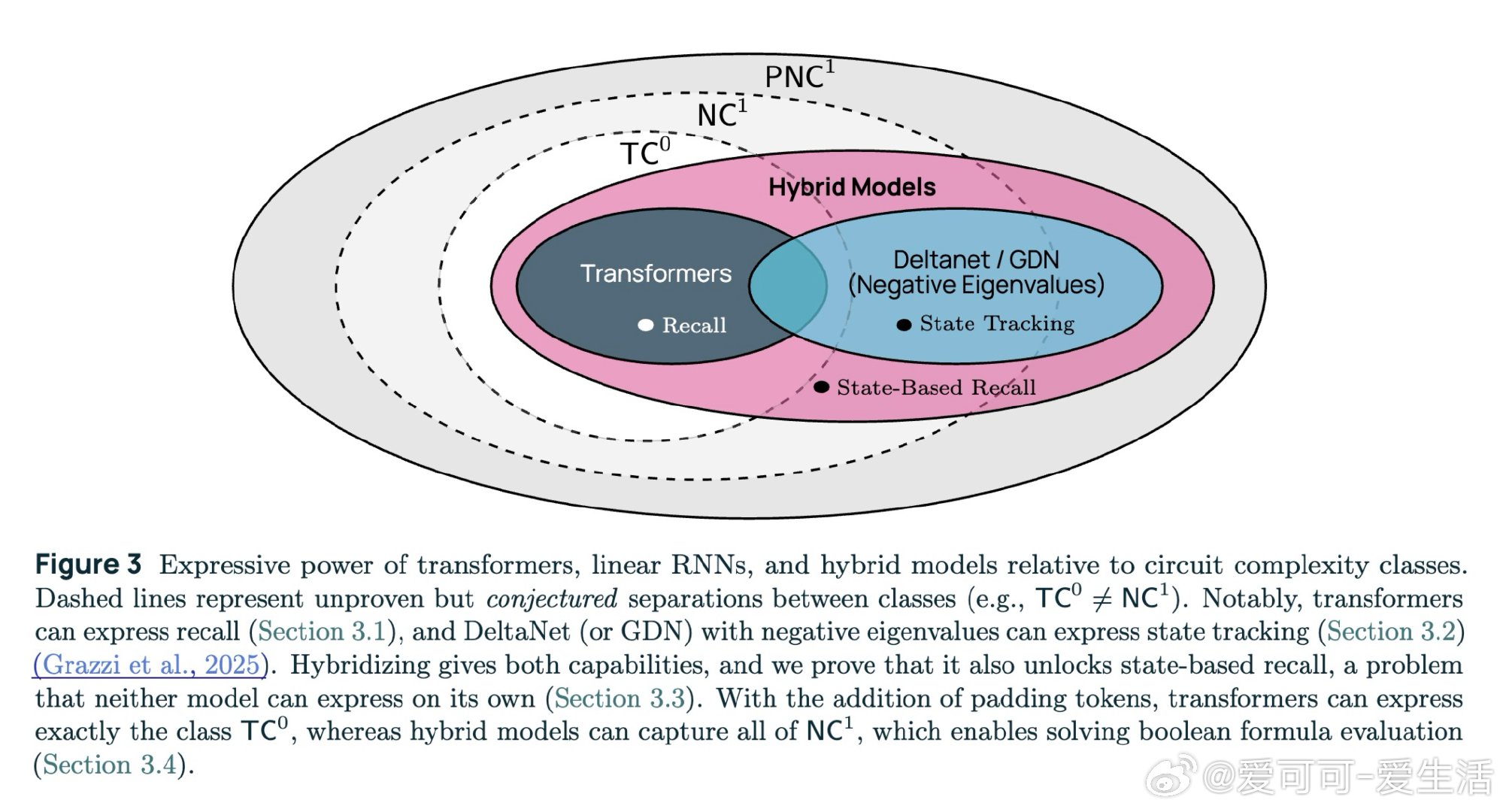
在语言模型架构领域,"用循环层替换注意力层是否值得"是一个悬而未决的实践难题。过去的纯Transformer受困于无法表达状态追踪(如变量交换序列),而纯线性RNN又因有界状态无法胜任长距离召回,本质原因是两者各自的计算机制存在互补的盲区。
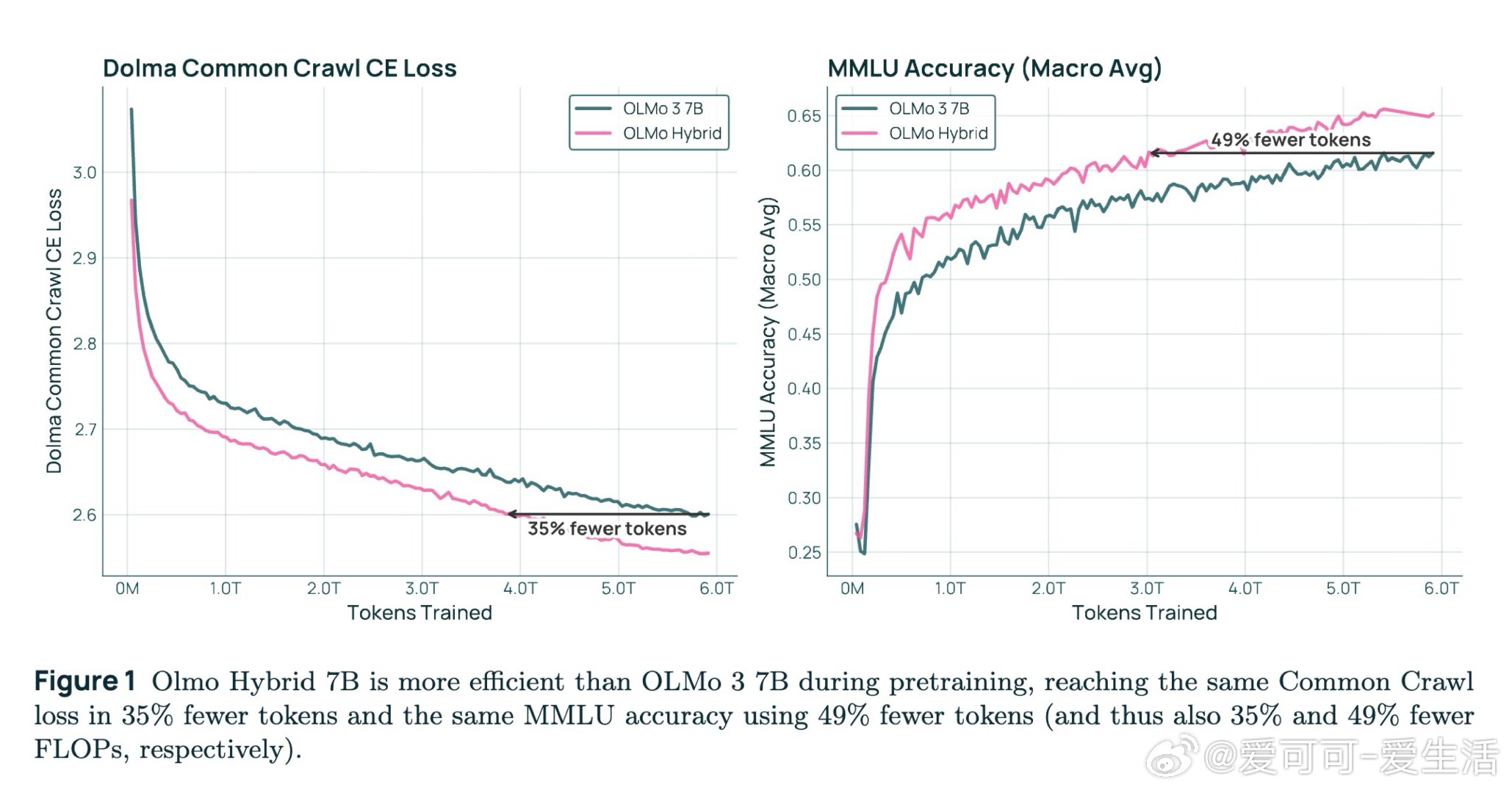
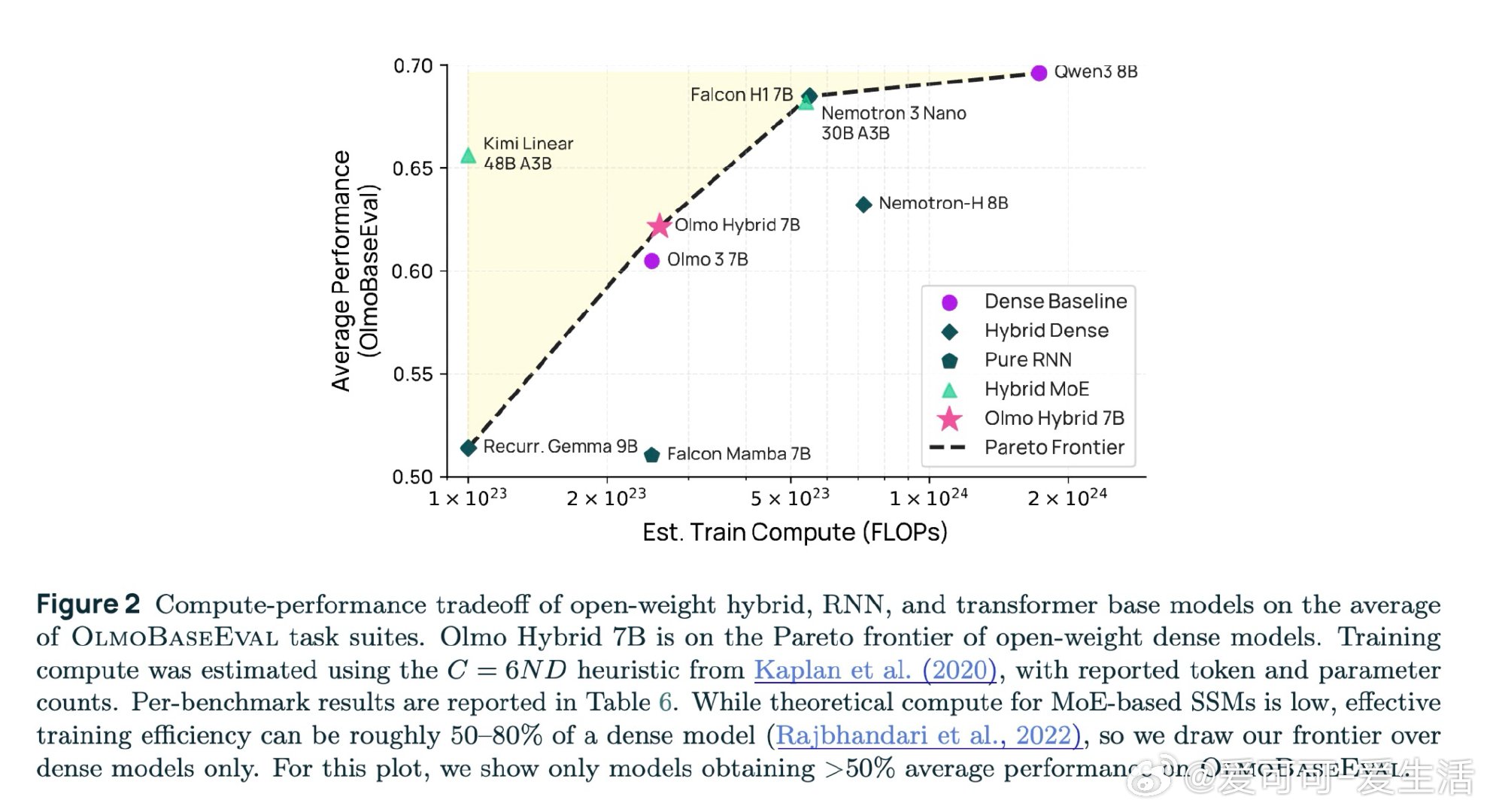
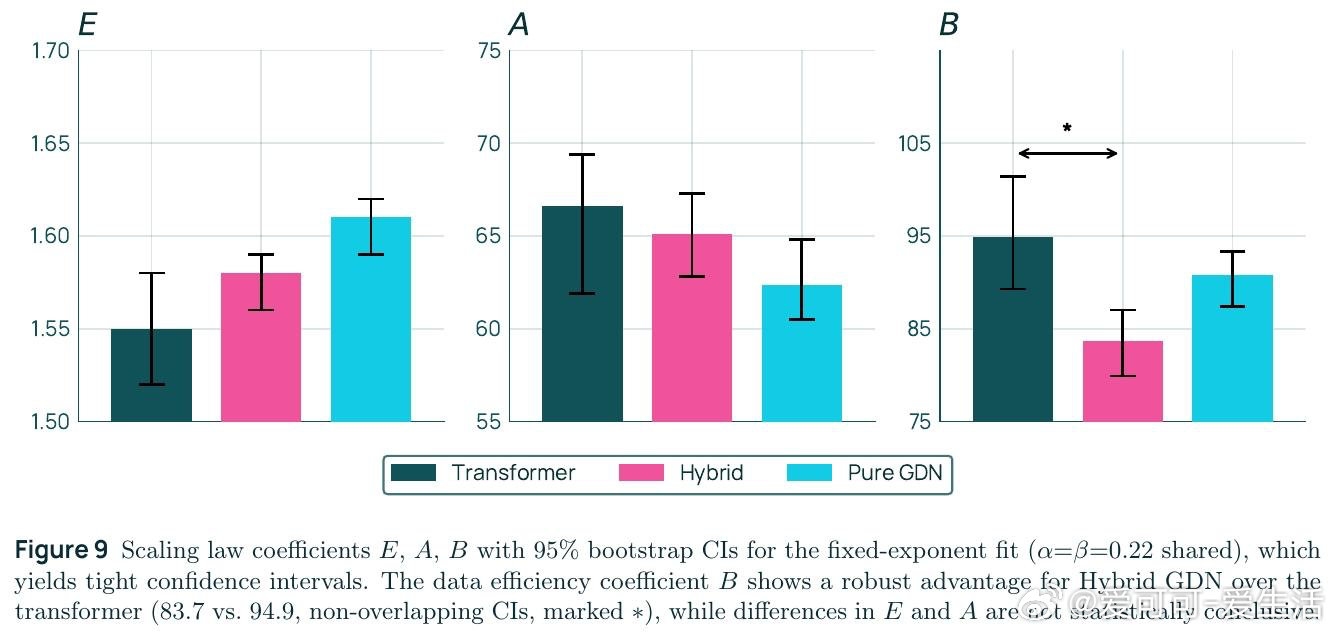
本文的核心洞见是:把混合架构重新看作一种超越两者之和的新计算范式。GDN层用负特征值实现状态追踪,注意力层实现精确召回,二者交替叠放后能解决"状态依赖召回"——即先追踪指针状态、再用该指针索引数组——这一任务既不可由纯Transformer表达,也不可由纯GDN表达。由此,将25%注意力层与75% GDN层交错排列这一关键操作,使7B模型用少49%的训练token便追上同规模纯Transformer,并在所有基准上全面领先。
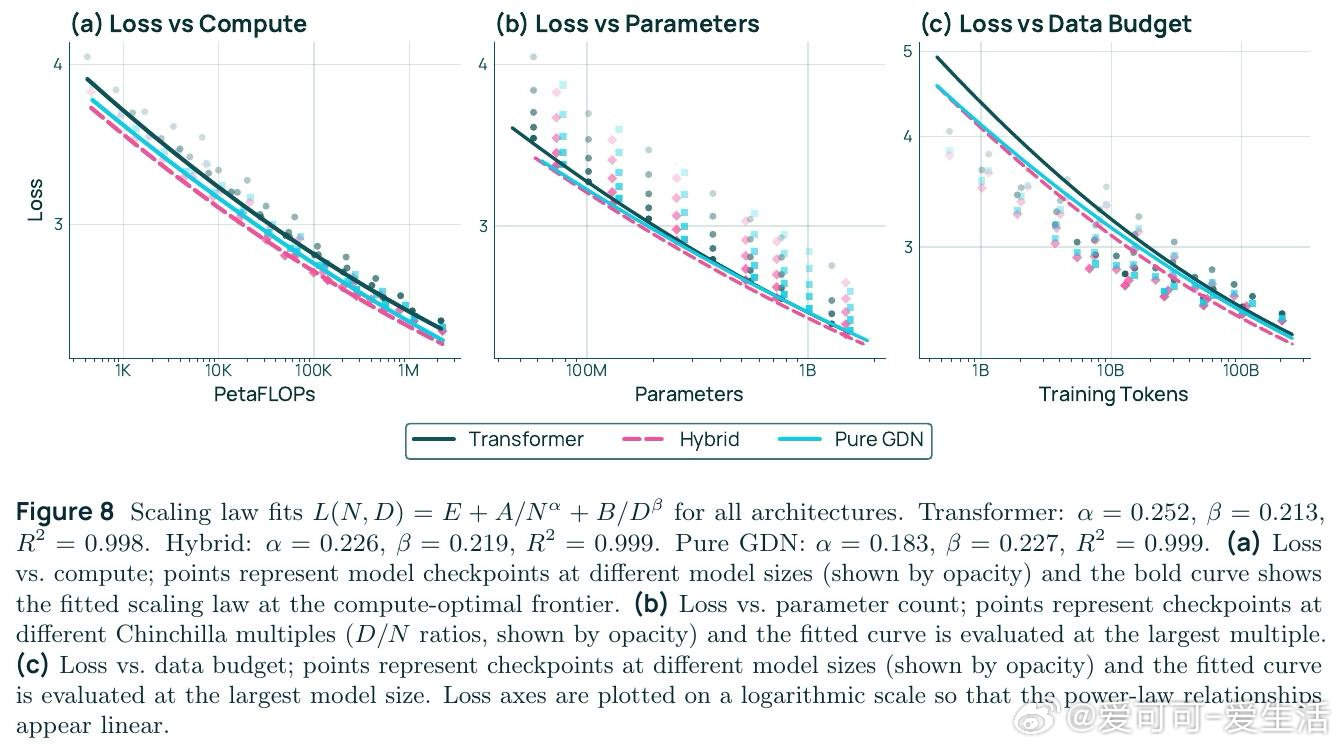
这项工作真正留下的遗产是:首次在受控大规模实验中,同时用理论(电路复杂度与量化缩放定律)和工程证据证明混合架构是基础性优势而非工程技巧。它为后来者打开的新门是:更高表达力可系统性地改善数据效率系数B,这一理论框架可指导未来架构搜索。但尚未跨过的门槛是:后训练阶段(尤其是强化学习)中RNN状态的数值精度问题仍制约推理稳定性,且理论预测与实验之间的定量对应尚需更严格的验证。
arxiv.org/abs/2604.03444
机器学习 人工智能 论文 AI创造营