DeepSeek 的视觉论文来了:Thinking with Visual Primitives
用 DeepSeek V4 Pro 分析了一下论文,如下:
多模态大模型(MLLM)在复杂推理中存在"指代鸿沟"(Reference Gap)—— 难以将抽象语言概念精确锚定到图像中的具体位置。
论文提出 "用视觉基元思考"(Thinking with Visual Primitives)框架:将空间标记(边界框和点)作为"思维的最小单元",直接嵌入模型的思维链推理过程中。
两类视觉基元:- 框(Grounding / ):用于计数、空间推理、通用视觉问答 —— 模型在推理时用边界框标记所引用的物体。- 点(Pointing / ):用于拓扑推理 —— 迷宫导航(逐步输出单元格坐标)和路径追踪(沿曲线的坐标序列)。
训练流程(四阶段):- 专项 SFT:通过程序化渲染生成冷启动数据(12.5万样本),分别训练两个专项模型 —— F_TwG(框基元)和 F_TwP(点基元)。- 专项 RL:使用 GRPO 算法,设计三种奖励模型 —— 格式 RM、质量 RM(LLM判别)、准确率 RM(任务定制:如计数的指数衰减奖励、迷宫的因果探索进度奖励等)。- 统一 RFT:用两个专项模型做拒绝采样生成数据,合并训练一个统一模型。- 在线策略蒸馏(OPD):用反向 KL 散度将两个专家模型的能力蒸馏到单一学生模型中。
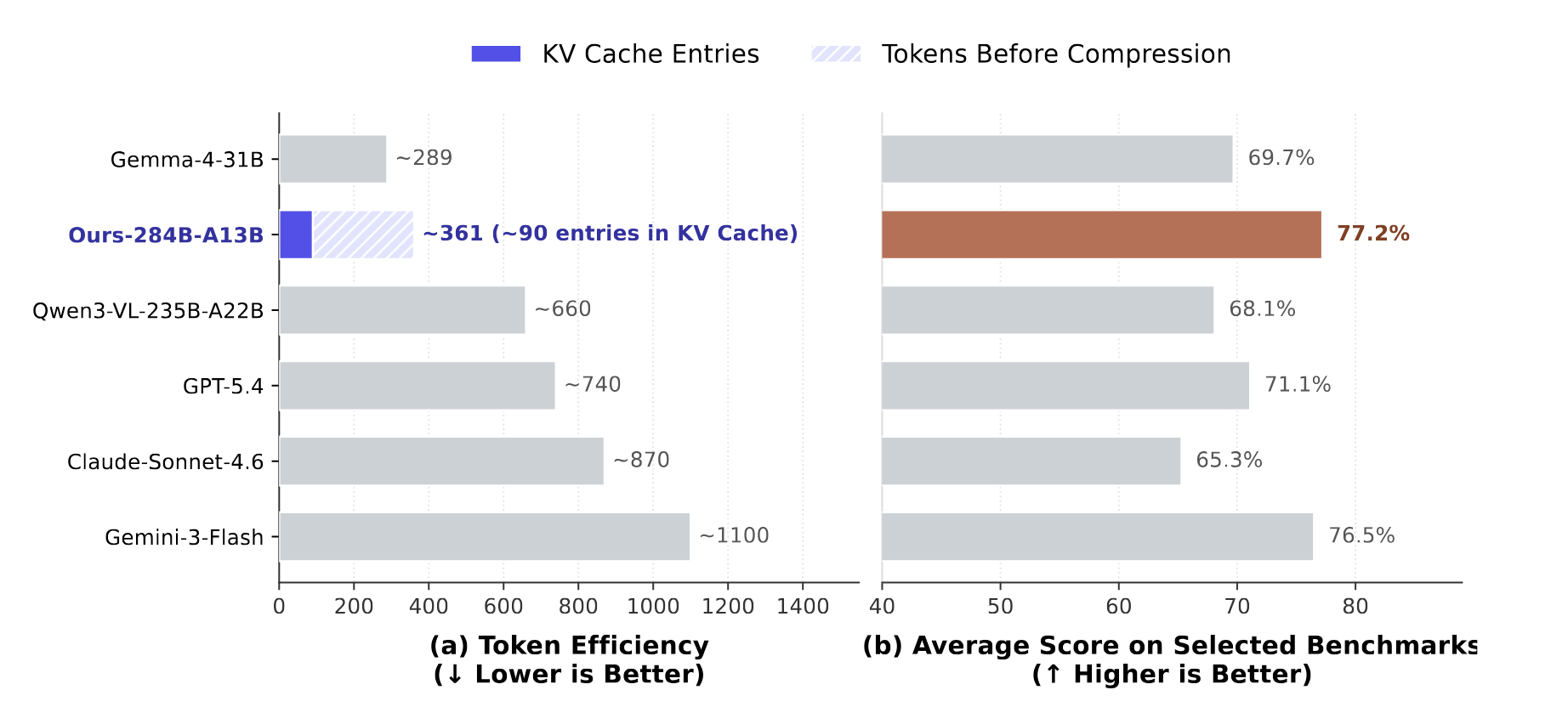
关键洞察:- Token 比像素更重要:通过视觉 token 压缩架构,以更少的图像 token 消耗达到甚至超越前沿模型性能。- 路径追踪中双向轨迹奖励(前向对齐 + 反向覆盖)至关重要。- "先训练专家,再合并"的策略有效避免了两种基元之间的模态冲突。- 局限:需要显式触发词激活;拓扑推理的跨场景泛化能力有限。
链接:github.com/deepseek-ai/Thinking-with-Visual-Primitives/blob/main/Thinking_with_Visual_Primitives.pdf