[CL]《RESTRAIN: From Spurious Votes to Signals -- Self-Driven RL with Self-Penalization》Z Yu, W Su, L Tao, H Wang... [Iowa State University & Meta & UW–Madison] (2025)
RESTRAIN:无需金标,自驱动强化学习迈向更强推理力
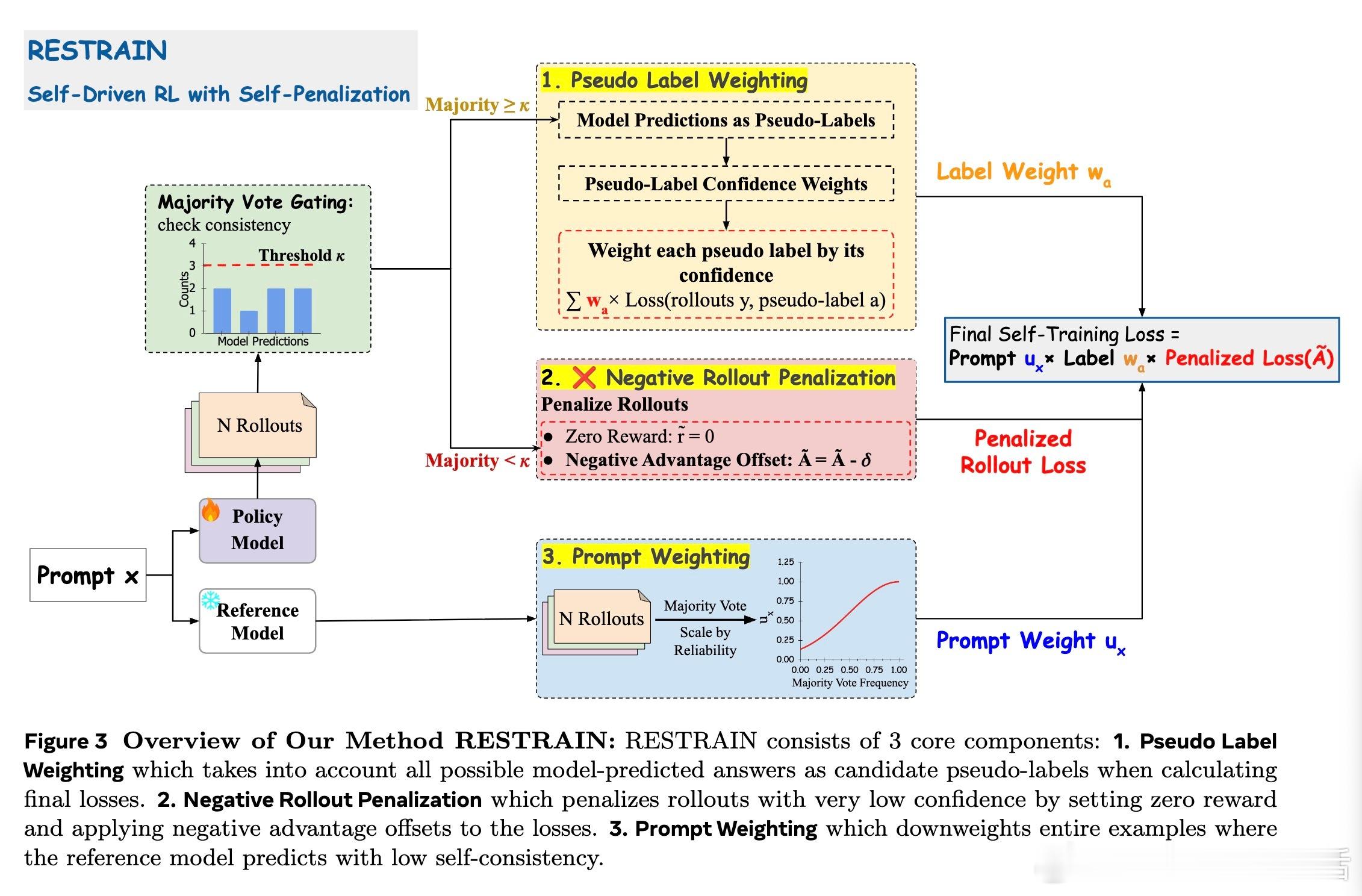
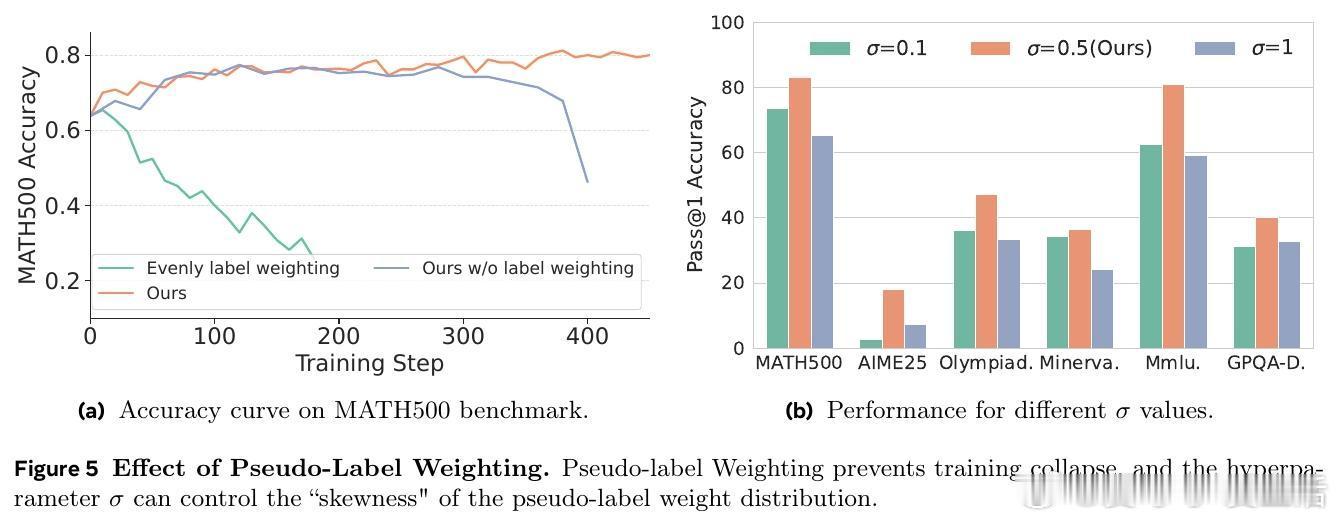
• 颠覆多数投票依赖,RESTRAIN通过伪标签加权,合理利用所有模型输出答案的分布,避免训练崩溃和过度自信。
• 引入负面轨迹惩罚,对低置信度推理路径施加负优势,促使模型探索多样且可靠的解答空间。
• 采用提示级权重,动态调整训练信号,弱化模型自我一致性低的样本贡献,提升训练稳定性和泛化能力。
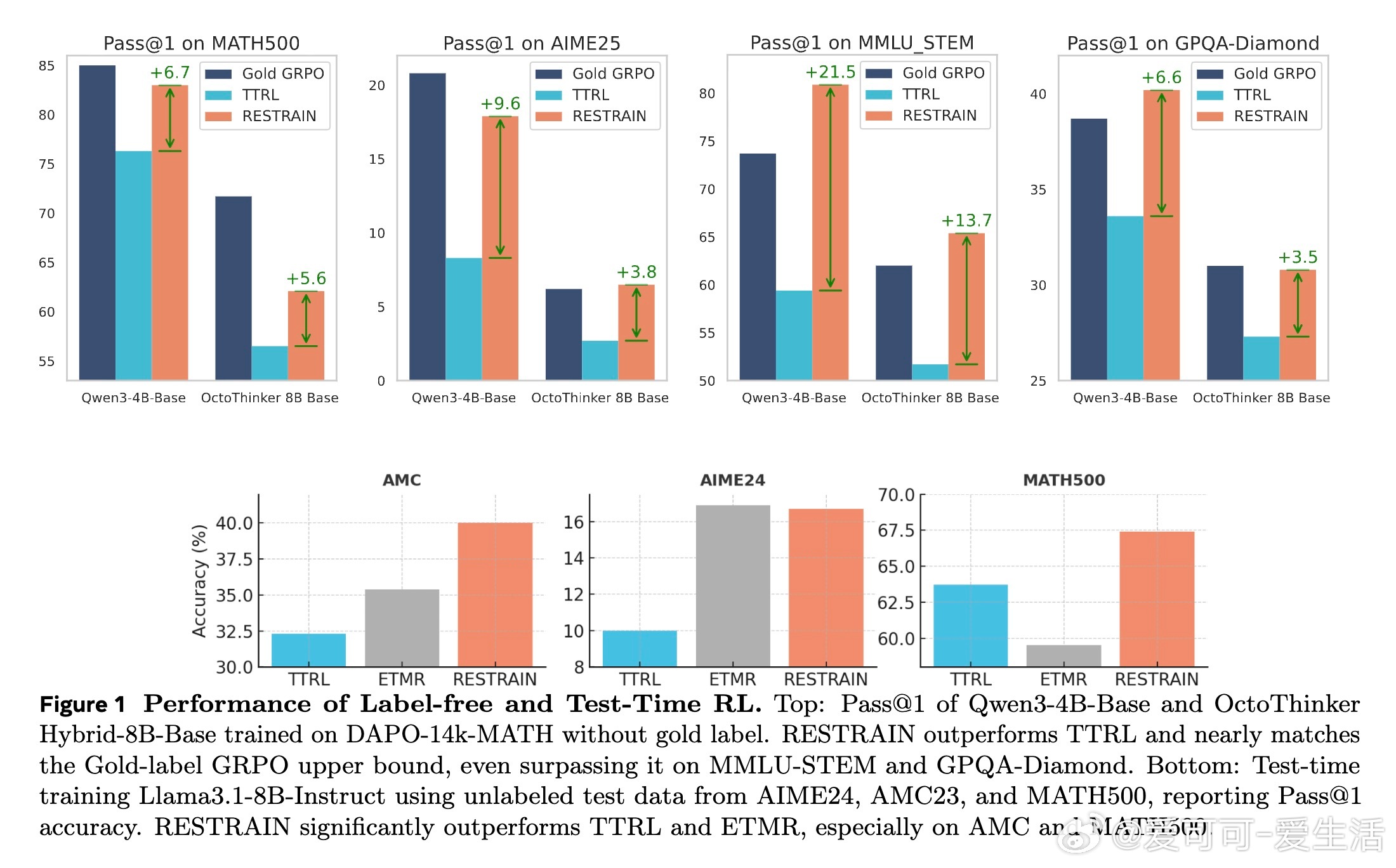
• 集成于GRPO策略优化,支持无监督连续自我提升,实验证明RESTRAIN在多个数学与科学推理基准上,使用无标签数据能实现+140.7%(AIME25)等显著提升,表现几乎匹配有金标监督的上限。
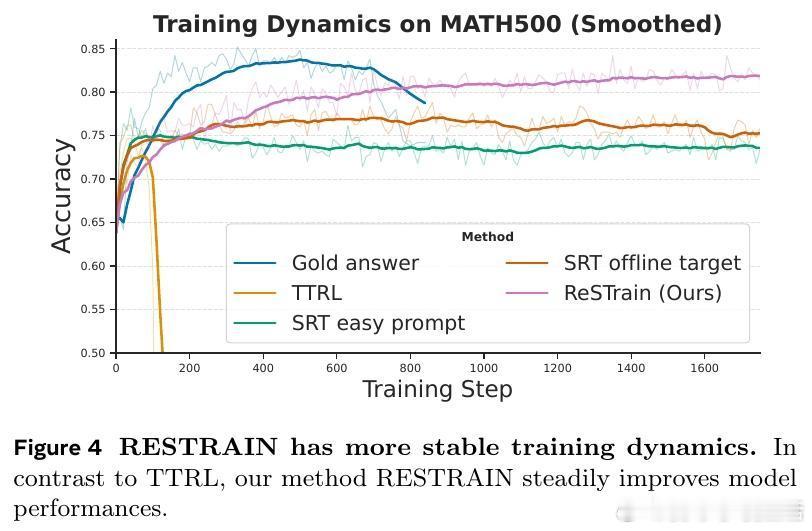
• 有效防止模型崩溃,训练过程更稳健,且跨领域表现优于传统基于多数投票的无监督强化学习方法。
• 消融实验证明,伪标签加权为核心关键,负面惩罚及提示权重进一步增强性能和稳定性。
• 设计合理的超参数(如伪标签权重偏置σ=0.5,负面惩罚δ=1,阈值κ=3)对效果至关重要,避免过度惩罚或信号稀释。
• 训练设置涵盖多个公开数据集和模型架构,结果具有广泛适用性和长期参考价值。
心得:
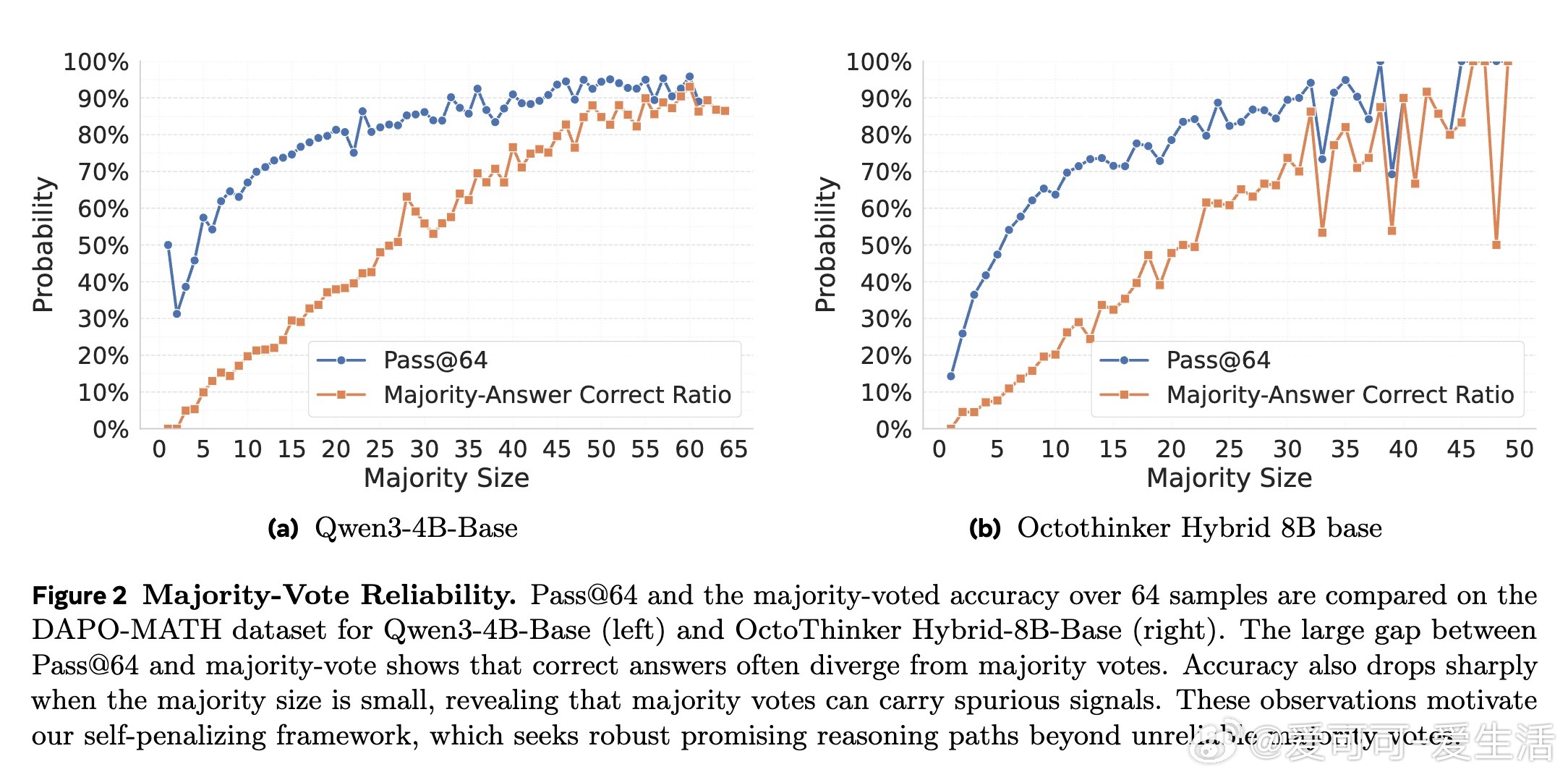
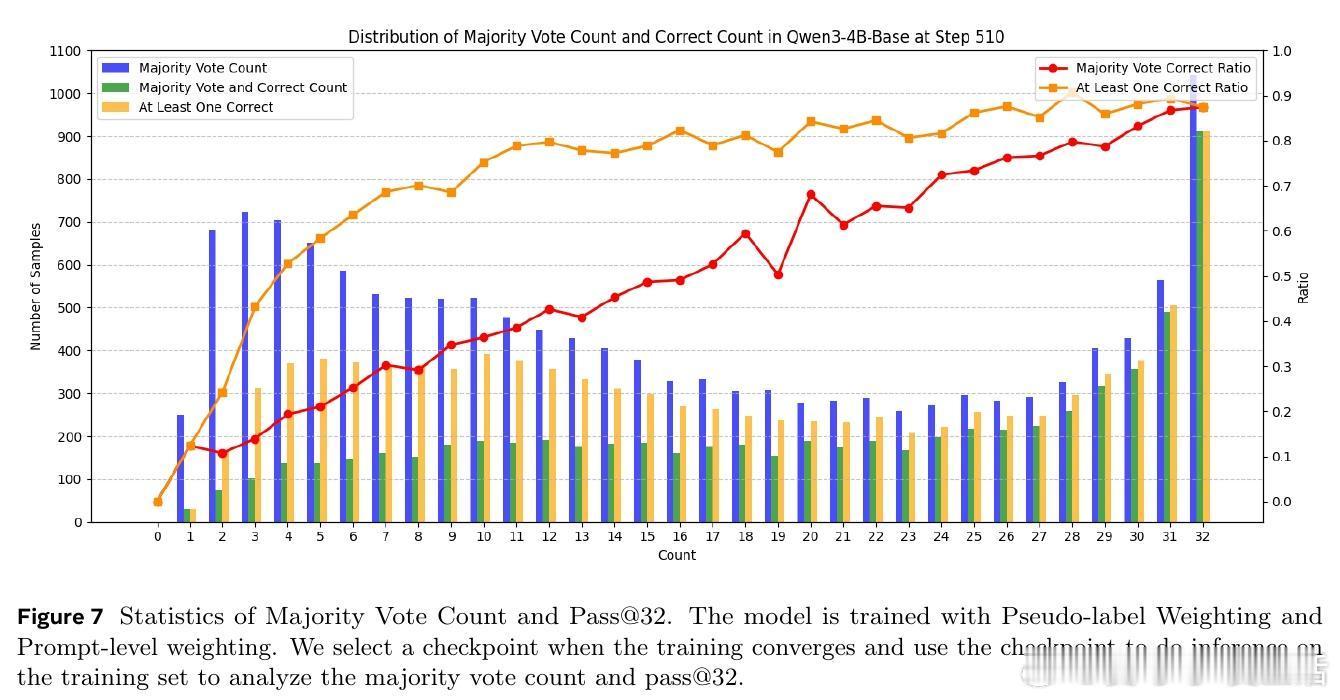
1. 多数投票并非真理,正确答案常位于少数,软加权策略能更好捕捉内在分布信息。
2. 负面惩罚不仅防止错误强化,更激发模型挖掘多样推理路径,提升探索深度。
3. 离线计算的提示级权重稳定训练节奏,防止训练中自信心虚假膨胀导致崩溃。
了解更多👉 arxiv.org/abs/2510.02172
强化学习无监督学习大模型推理自驱动训练机器学习方法