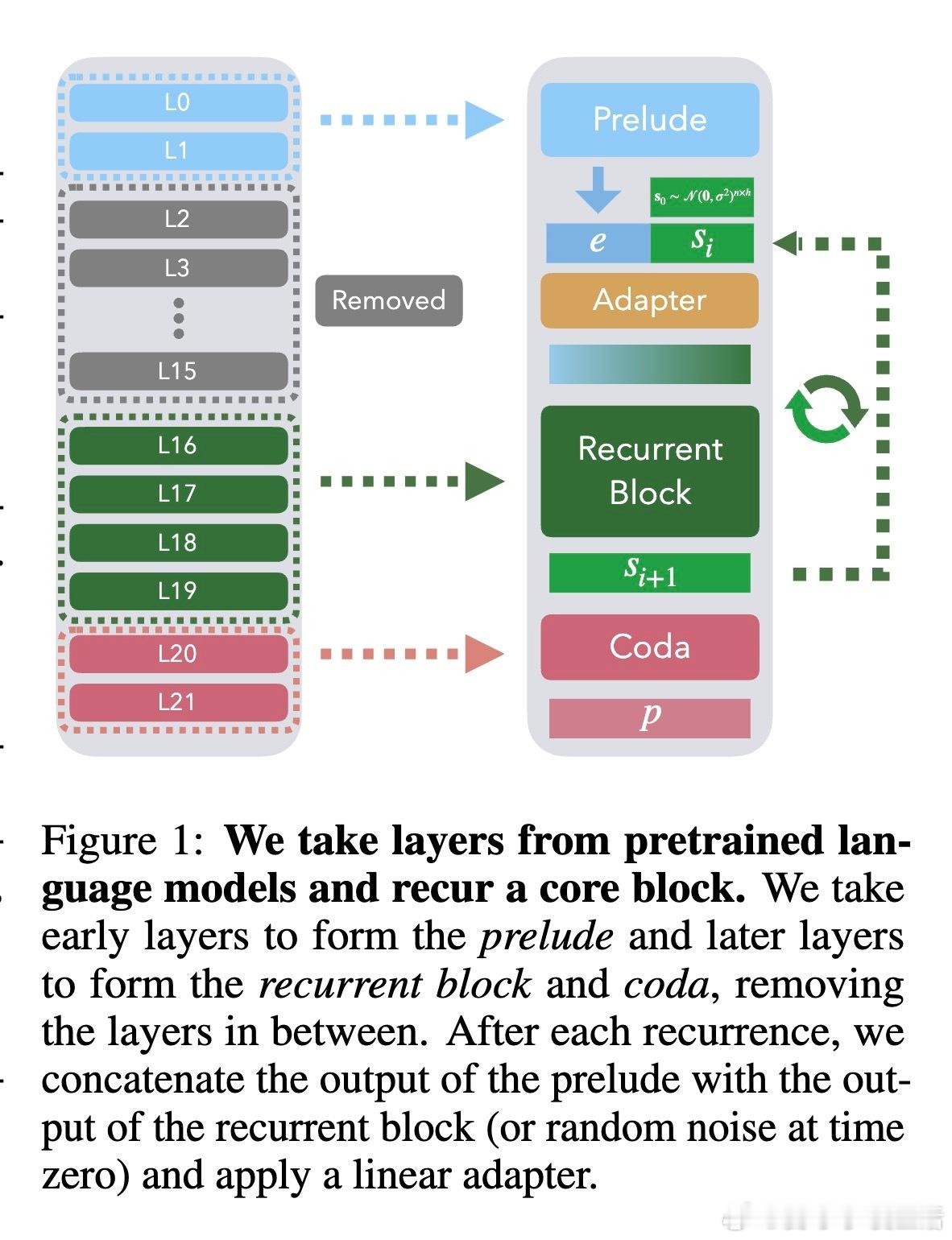
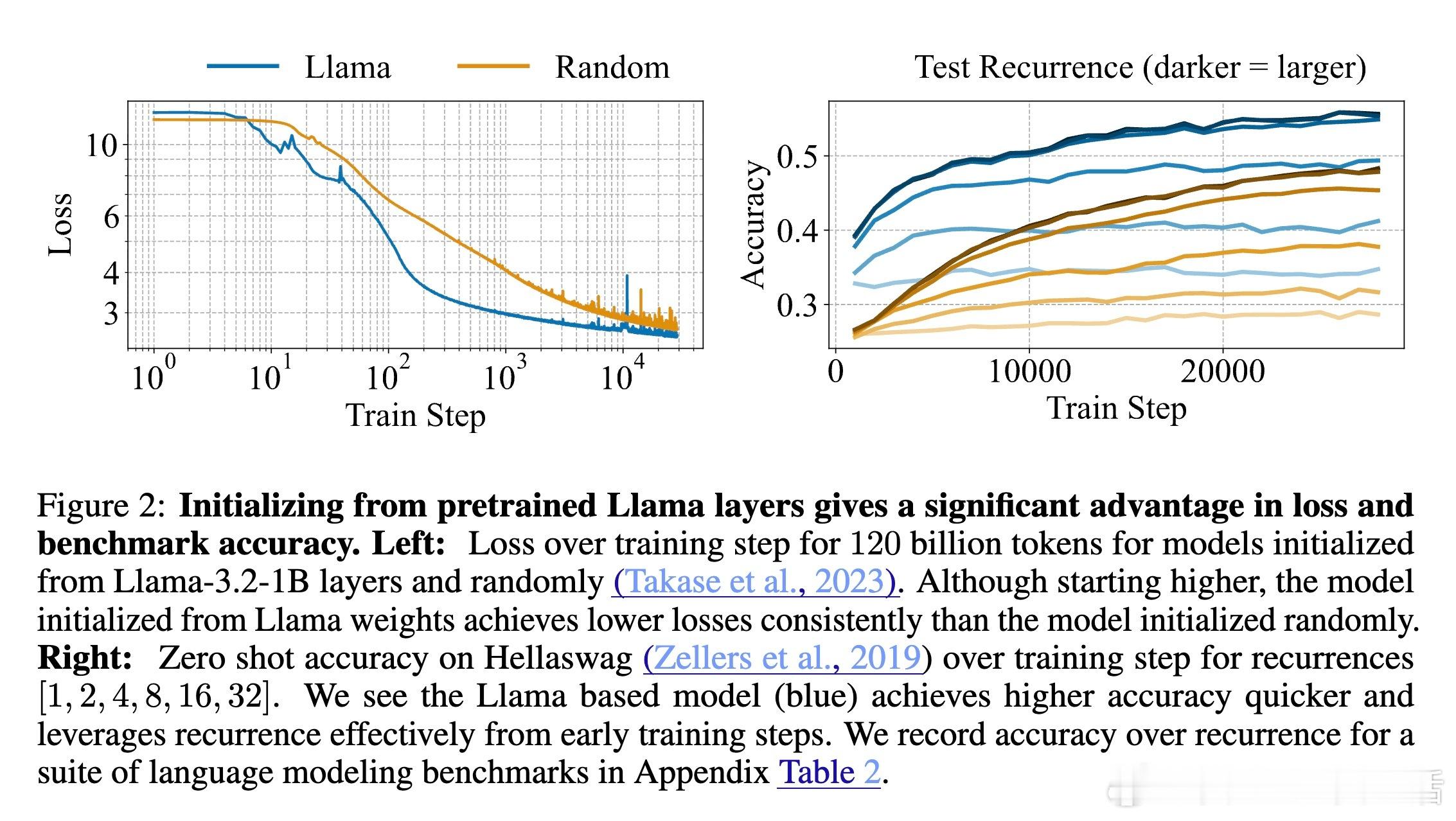
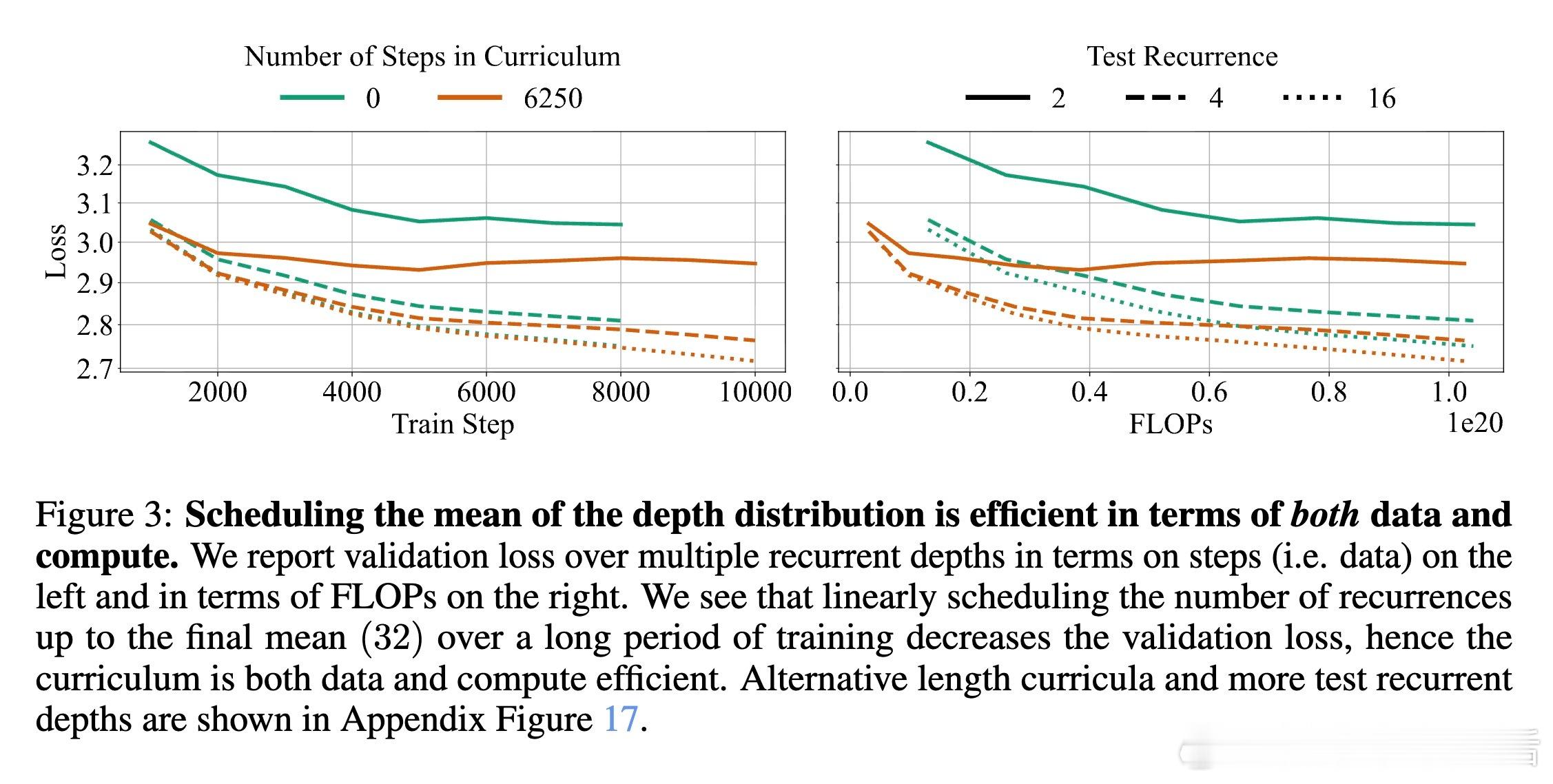
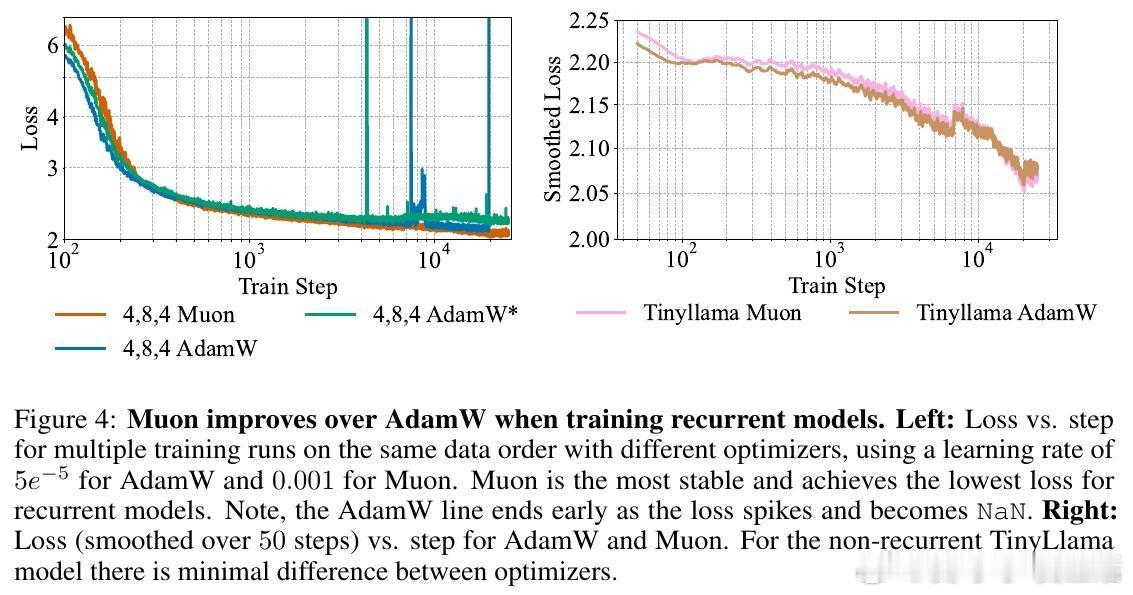
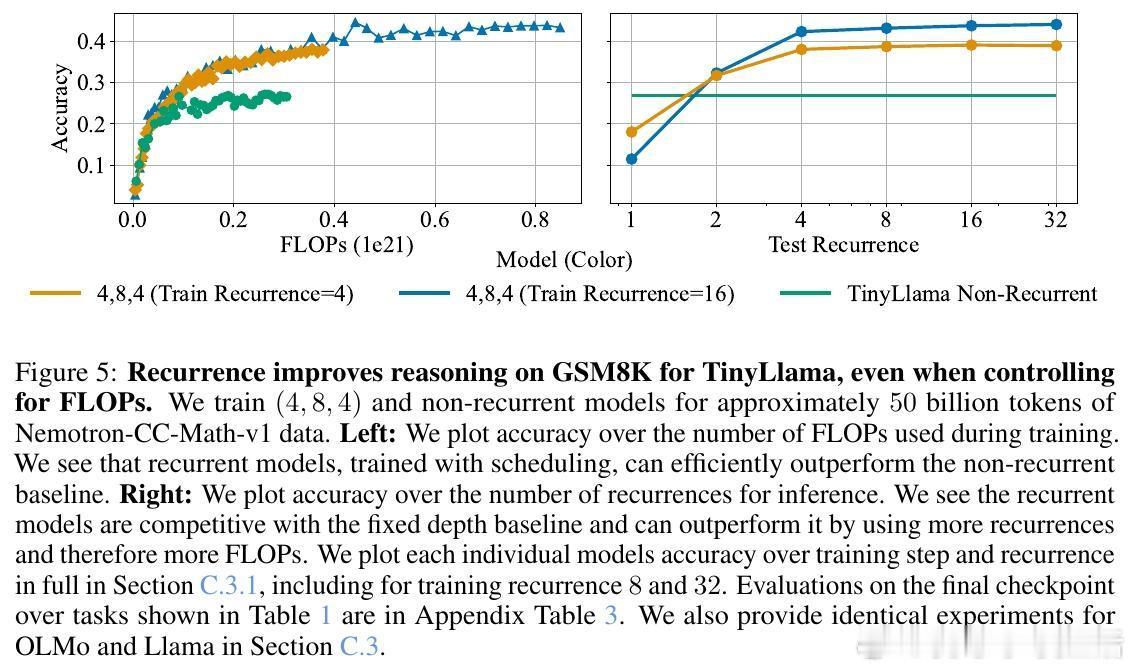
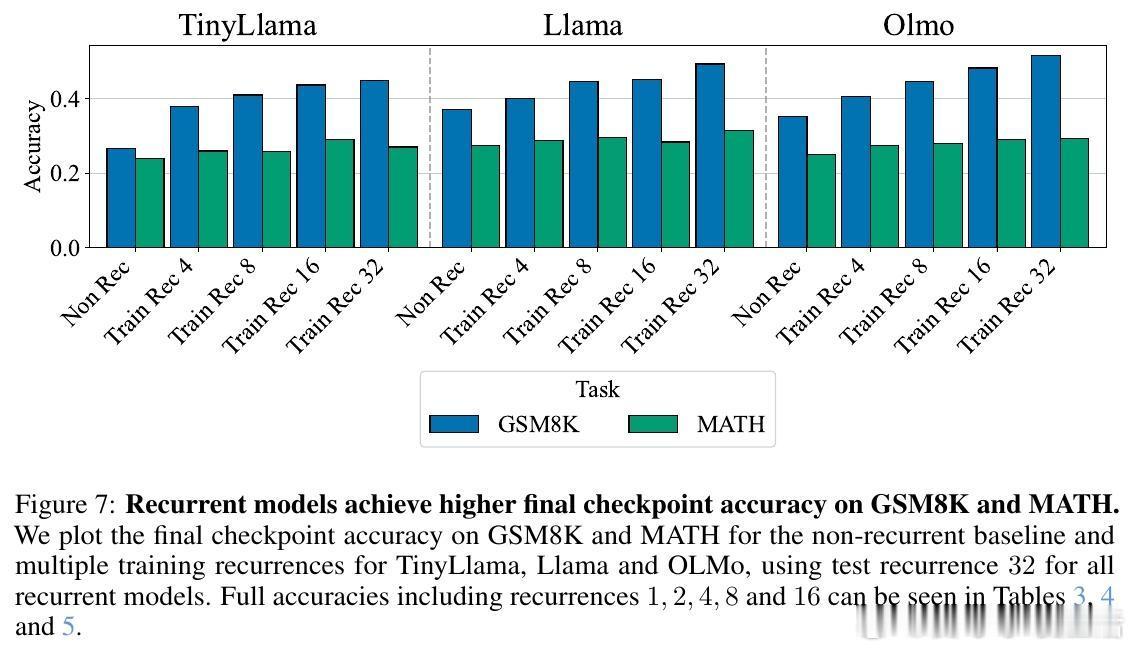
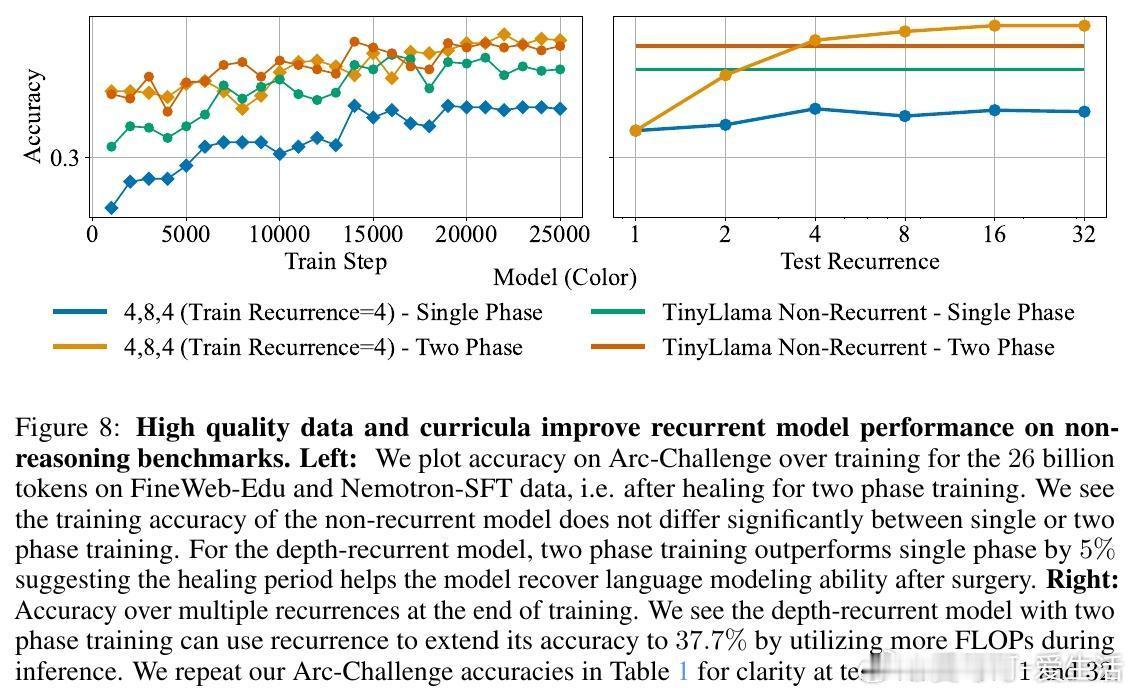
[CL]《Teaching Pretrained Language Models to Think Deeper with Retrofitted Recurrence》S McLeish, A Li, J Kirchenbauer, D S Kalra... [University of Maryland & New York University] (2025) 深度复发语言模型(Depth-Recurrent LMs)正成为解锁更高效推理能力的关键路线。本文为我们带来重要启示:1. 深度复发,解耦训练与推理计算 传统Transformer模型推理计算与参数量密切相关,增加推理深度必然增加内存与上下文消耗。深度复发结构通过“循环使用”部分层,使得推理时计算量可调而参数固定,既节省内存又提高信息处理带宽。2. 预训练模型的复发改造,提升效率与性能 作者提出了一种“模型手术”方法,将已有预训练非复发模型拆分为Prelude(序章)、Recurrent Block(复发块)和Coda(尾声),去除中间部分层,循环复用复发块。通过持续预训练,模型学会利用复发机制,显著提升在数学推理任务上的表现,同时降低整体计算成本。3. 递进式复发深度课程(Curriculum) 训练过程中,逐步增加复发次数的课程策略,保证模型训练效率与性能兼顾。该策略在训练初期减少计算负担,后期充分利用复发深度带来的推理能力提升。4. 优化器选择与参数减裁 Muon优化器在训练复发模型时表现优于AdamW,稳定且避免训练崩溃。裁剪部分层并复用剩余层的参数,不仅减少模型规模,也让模型在有限计算预算内获得更优推理效果。5. 数学推理表现的显著提升 在GSM8K和MATH等数学基准测试中,复发模型在相同训练FLOPs预算下,准确率明显优于非复发基线。且随着推理复发次数增加,性能持续提升,展现了深度复发模型的灵活性和扩展性。6.“疗愈”训练阶段的重要性 针对模型改造后出现的分布改变,设计两阶段训练:先用通用文本数据“疗愈”模型以恢复基础语言能力,再进入任务特定强化训练。此举有效避免模型性能下降,提升了综合推理表现。7. 广泛任务适应性 深度复发模型不仅在数学推理上表现卓越,也在包括Arc、Hellaswag、Winogrande、MMLU等多样语言理解任务上维持甚至提升性能,显示出其通用性与潜力。核心启发:- 复发机制让模型“多次思考”,在潜在空间中反复加工信息,远比简单加深层数或生成链式思维更高效。- 通过“模型手术”,可以低成本赋予现有预训练模型更强的动态推理能力。- 训练课程设计和数据管理是成功转化的关键,尤其“疗愈”阶段不可忽视。- 未来挑战包括如何让模型自适应分配思考深度,实现“难题深思,易题速解”的智能推理。这项工作为构建更灵活、高效的深度学习推理框架提供了实用路径和实验基石,预示着大型语言模型训练与推理的新范式。详细论文与代码地址:arxiv.org/abs/2511.07384 代码库:github.com/mcleish7/retrofitting-recurrence 模型集:huggingface.co/collections/tomg-group-umd/retrofitting-recurrence


![经典还是经典,永远都不过时[6]](http://image.uczzd.cn/840067733644116006.jpg?id=0)