DeepSeek 刚刚发布的大杀器 DSpark 到底厉害在哪?
DeepSeek 又扔出了一颗深水炸弹 DSpark。简单说它是一个专门用来给大模型“踩油门”的加速器。
大模型平时是怎么给我们吐字的?
就像旧时候的打字机一样,必须一字一字地往外蹦。
这种方式在技术上叫“串行自回归”。
平时用用还好,一旦遇上高峰,同时生成好多内容,服务器的显卡就会因为频繁等待而“转圈圈”,不仅响应变慢,电费还蹭蹭往上涨。
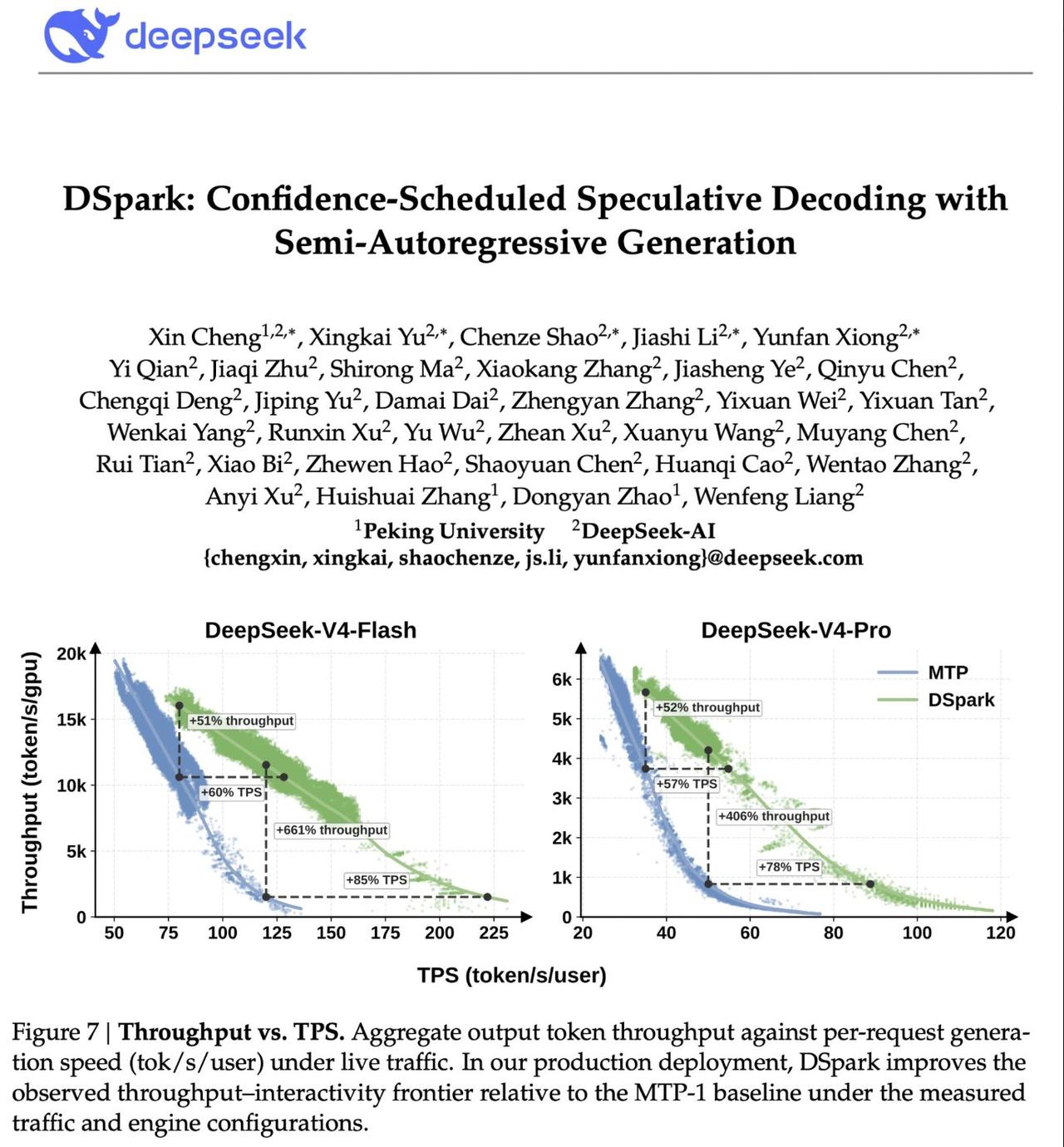
DSpark 的出现,就是为了打破这个高并发的瓶颈。用上它之后,单用户的文本生成速度直接提升了 60% 到 85%,高并发下的整体吞吐量最高暴涨了 4 倍!
那它是怎么做到让大模型“无损质量”跑出超跑速度的呢?
这得提提 DeepSeek 之前的当家绝活。
熟悉的朋友应该记得,DeepSeek 之前在 V3、V4 模型里,为了加速就用过一种叫 MTP(多 Token 预测)的技术。
这就好比以前是想一个字写一个字,MTP 则是走一步看两步,脑子里提前多想两个字。
而这次的 DSpark,就是把这种“提前预判”的工程思想发挥到了极致。
DSpark 里面有两个秘密武器:
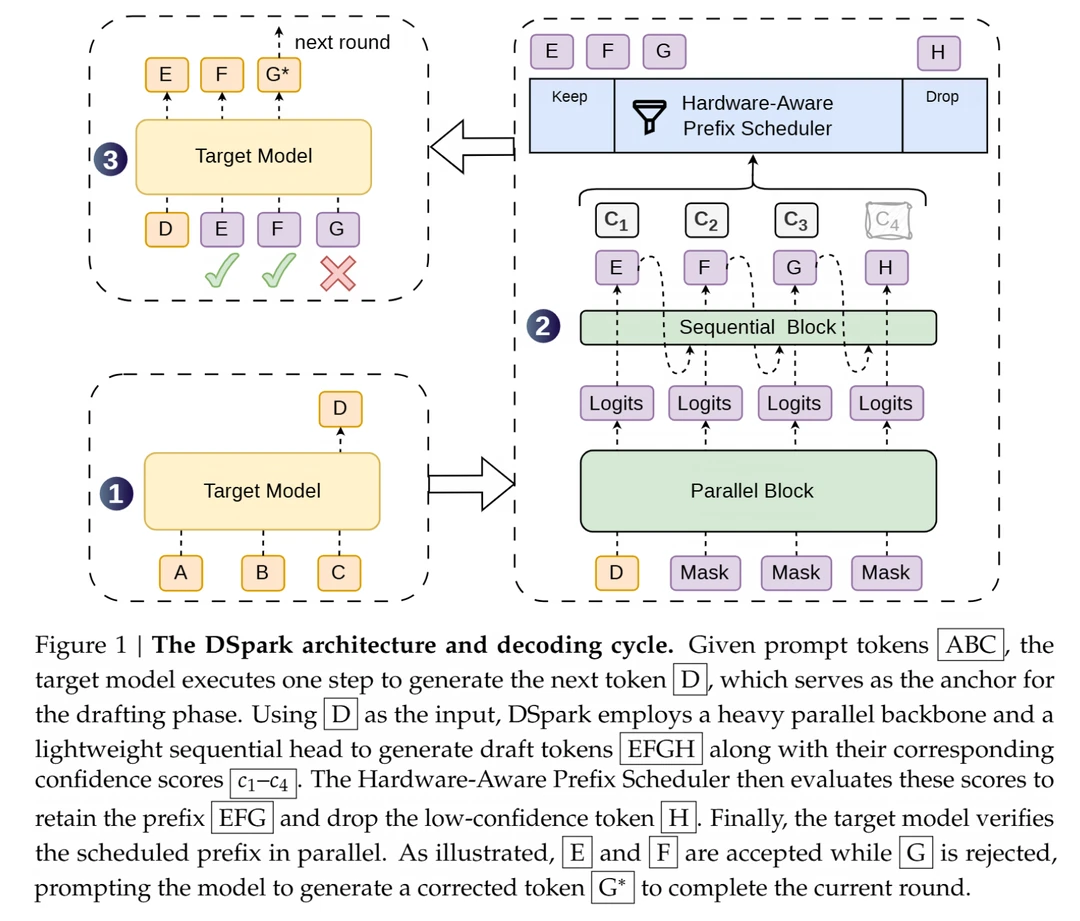
1、半自回归候选生成。
以前的加速方案是找个“小助理模型”在前面盲猜一堆词,大模型在后面审核。
但小助理经常猜错,导致大模型频繁推翻重来。
DSpark 换了个思路,让小助理批量生产候选词的同时,加入一个轻量级的依赖模块。这等于给小助理塞了本实时参考书,让他“猜得又快又准”。
2、置信度调度验证。
这可以说是最像人类的一点。
DSpark 内部有个“置信度头”,能实时评估每个词猜对的概率。
而且它会看人下菜碟,如果当前服务器很闲,它有把握,就一口气多验证几个字;如果服务器刚好遇到了早高峰,或者自己心里也没底,它就稳扎稳打,绝不浪费宝贵的显卡算力。
所以,这套组合拳打下来,不仅速度飞起,而且一块显卡能当几块用,成本直接打骨折。
以前大家都觉得,大模型要厉害,参数必须得大,分得考得高。
但 DeepSeek 再次用实际行动证明了:真正能落地、省钱、好用的技术,得是把每一滴算力都压榨到极致的硬核工程。
国产大模型在算力压榨这一块,是不是已经走到了世界前列?