DeepSeek融资500亿,估值或超3500亿!这些国产技术的支撑功不可没!
日前,一则关于国内AI“顶流”DeepSeek的消息震惊业内:据媒体报道,DeepSeek拟融资超500亿元,短短半个月估值从200亿美元直接翻倍,业内预计本轮融资完成后整体估值或将突破3500亿元人民币(约515亿美元)。
DeepSeek快速发展的背后,算法创新至关重要。DeepSeek独创的动态神经网络架构(DNA),说白了就是让计算资源和模型性能之间自己找最佳平衡点——该使劲的地方使劲,不该使劲的地方省着用,训练效率上去了,成本还降了。
但今天想聊的是另一个被忽略的狠角色——DeepSeek V4背后站着的算力能手:昇腾。毕竟没有强大算力支撑,再好的算法也是空中楼阁。
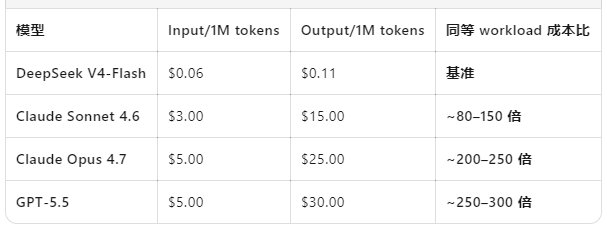
今年4月,DeepSeek V4-Pro和DeepSeek V4-Flash正式发布并开源,模型上下文处理长度从128K扩展到1M,容量提升近10倍。模型越来越聪明,对底层算力的要求也越来越高,核心就三点:优化通信占比、适配超长序列、实现推理超低时延。
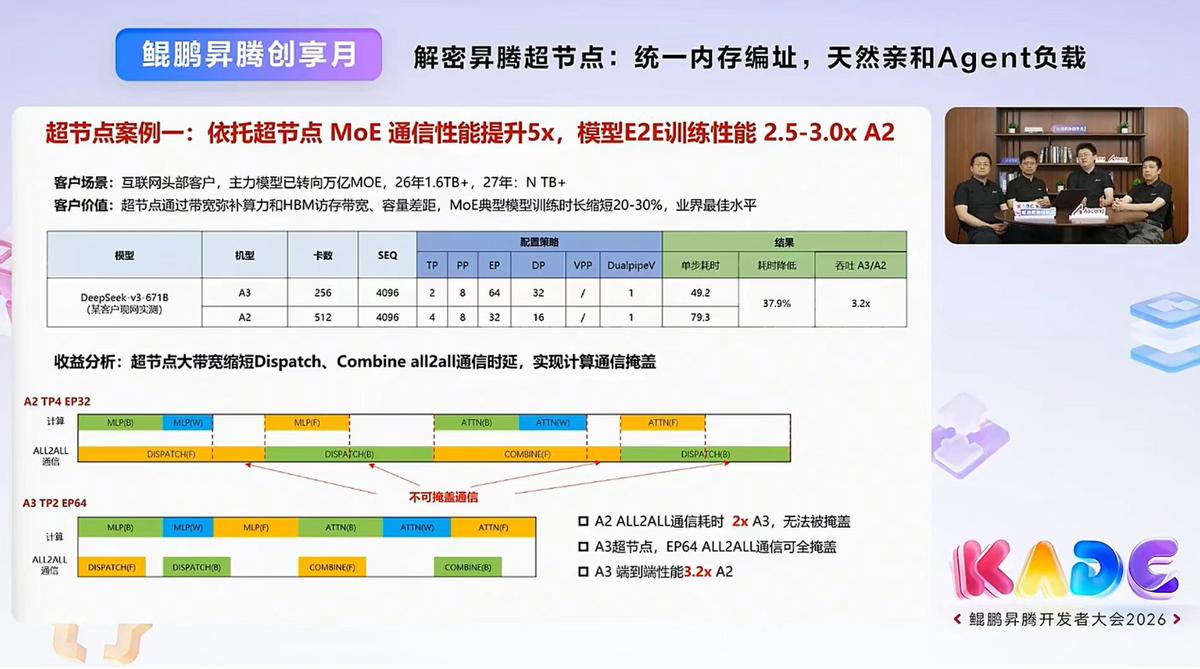
昇腾超节点恰好对上了这三个核心诉求。日前在“鲲鹏昇腾创享月”上,华为昇腾技术专家们解密了昇腾超节点解决方案,三大核心技术:超大带宽、超低时延、内存统一编址。
关键一招是内存统一编址——将数千张加速卡的内存整合成一个统一编址的超级内存池,直接管理。以前每张卡的内存各管各的,调数据要层层中转;现在所有卡的内存编到一本账上,谁需要直接取,不用传话、不用等。同时实现了1对多管理,中间流程全砍掉,数千张卡组成的超节点变成了一台“超级计算机”。
这带来的效果有多实在?国内某家大厂的实际跑测数据:依托昇腾超节点的MoE通信性能提升5倍,典型大模型训练时长缩短了20%到30%。
这意味着同样的模型、同样的卡,少跑近三分之一的时间就能训完。省的不只是时间,是真金白银的电费和算力成本。
所以DeepSeek这轮估值暴涨的背后,不只是算法的胜利。芯片和模型之间的深度协同,让昇腾这个算力底座真正扛住了顶级模型的考验,这层支撑,功不可没。