[LG]《Automated Reward Design for Gran Turismo》M Ma, T Seno, K Subramanian, P R. Wurman... [University of Montreal & Turing Inc. & Sony AI] (2025)
在强化学习中,设计奖励函数是让智能体实现期望行为的关键,但对于复杂环境如《Gran Turismo 7》赛车游戏,手动构建奖励函数既费时又困难。面对这一难题,研究者Michel Ma等人提出了一个创新方案:利用大型基础模型(LLM)自动生成奖励函数代码,并结合视觉语言模型(VLM)进行偏好评估,辅以少量人工反馈,实现从文本指令到训练出超越人类专家水平赛车智能体的闭环自动化奖励设计系统。
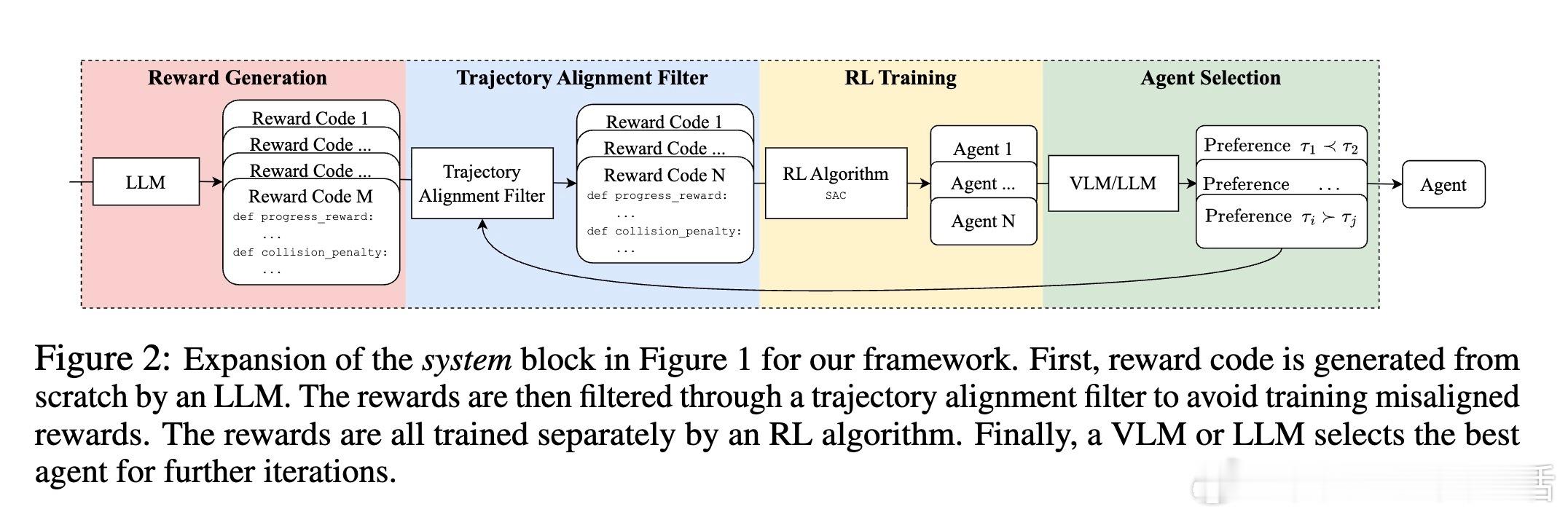
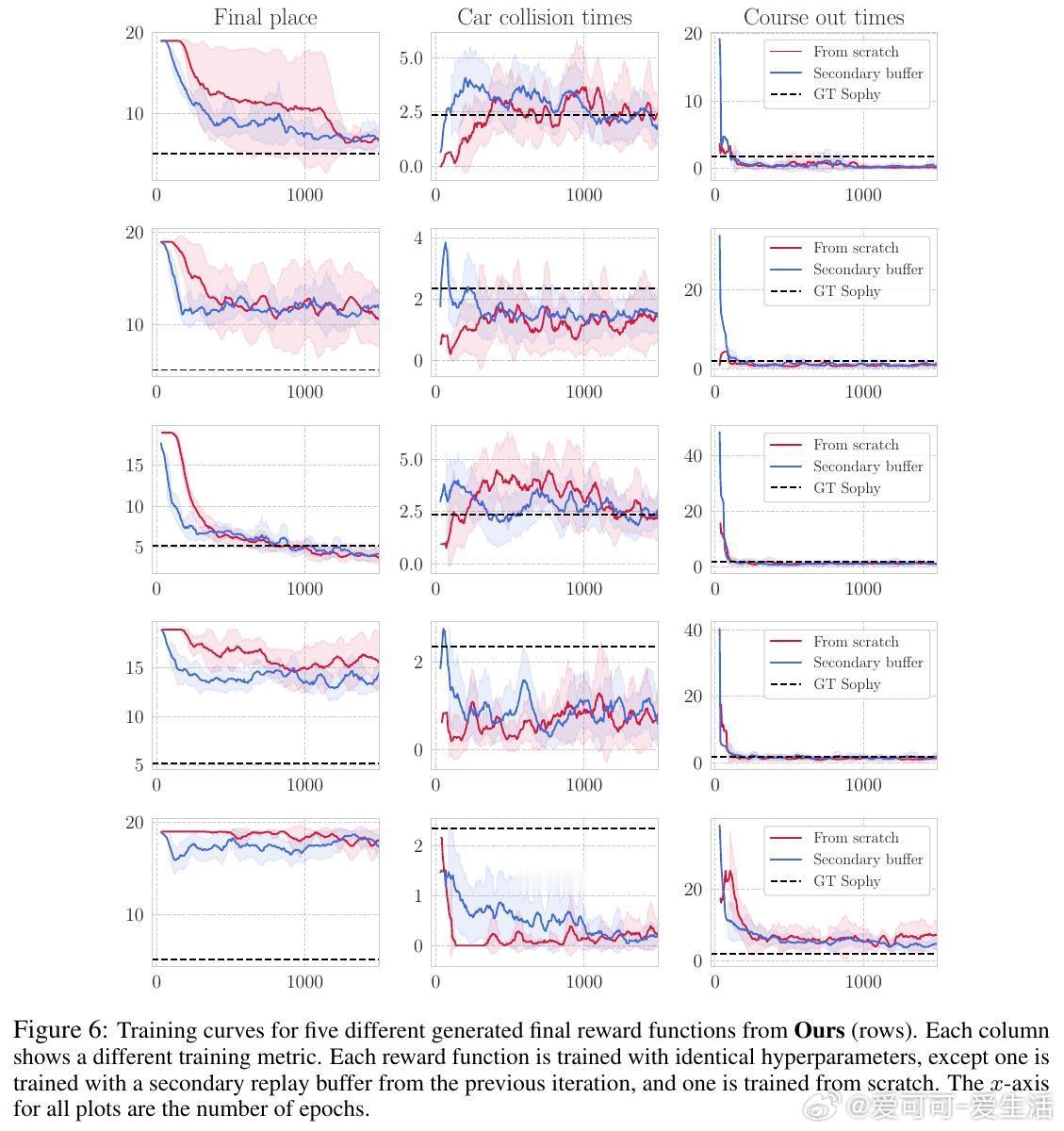
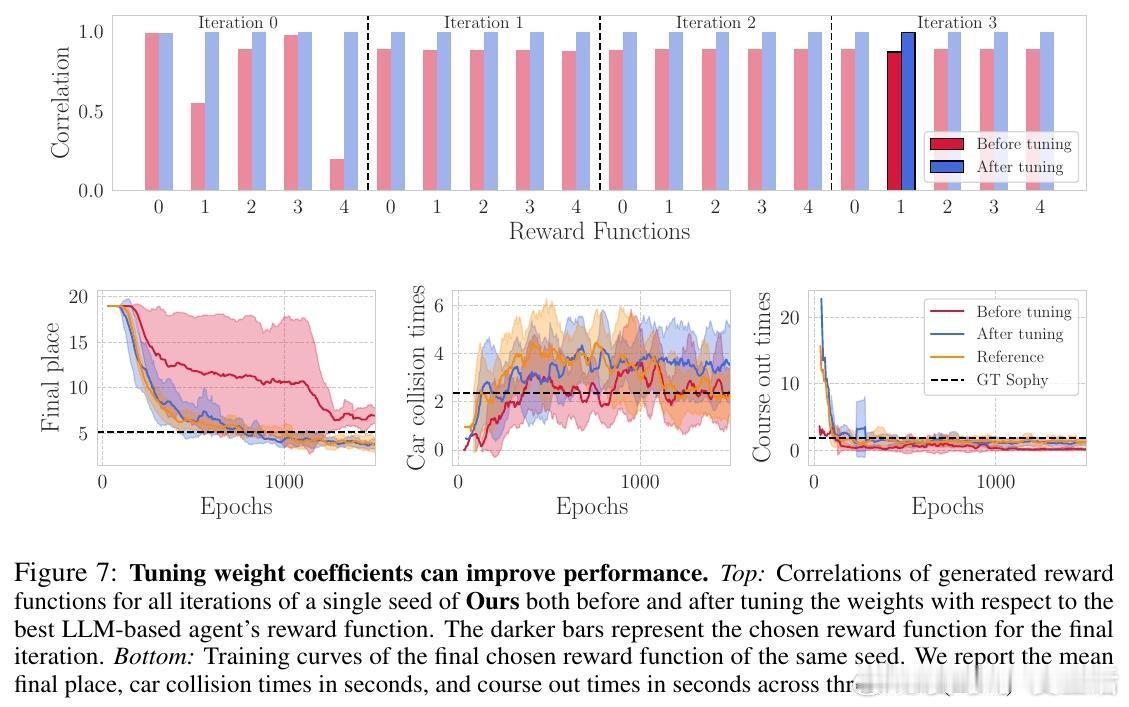
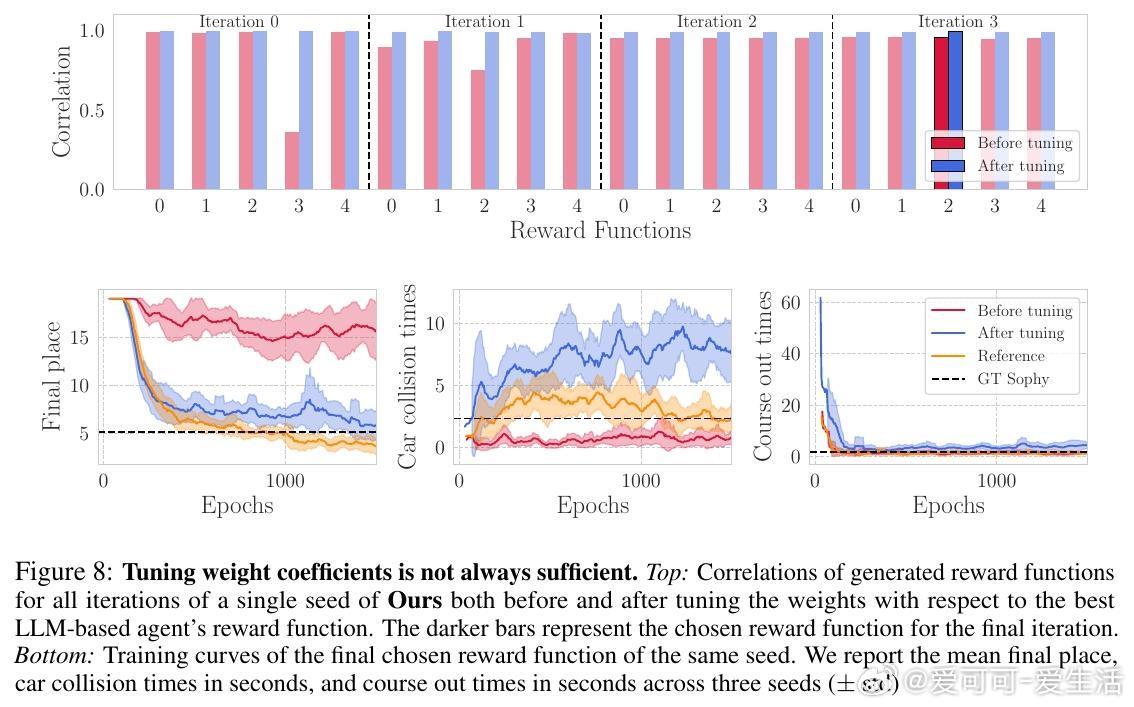
他们的系统核心在于一个迭代框架:首先输入环境状态描述与任务文本(如“赢得比赛且保持良好体育道德”),LLM生成多套奖励函数;接着通过轨迹对比和VLM偏好判断筛选出表现最佳的奖励函数;再通过强化学习训练对应策略;最后通过人工或模型反馈进一步优化奖励设计。该方法摒弃了传统依赖人工设计的适应度函数,显著节省了专家调试时间,并能产生多样且创新的奖励组合。
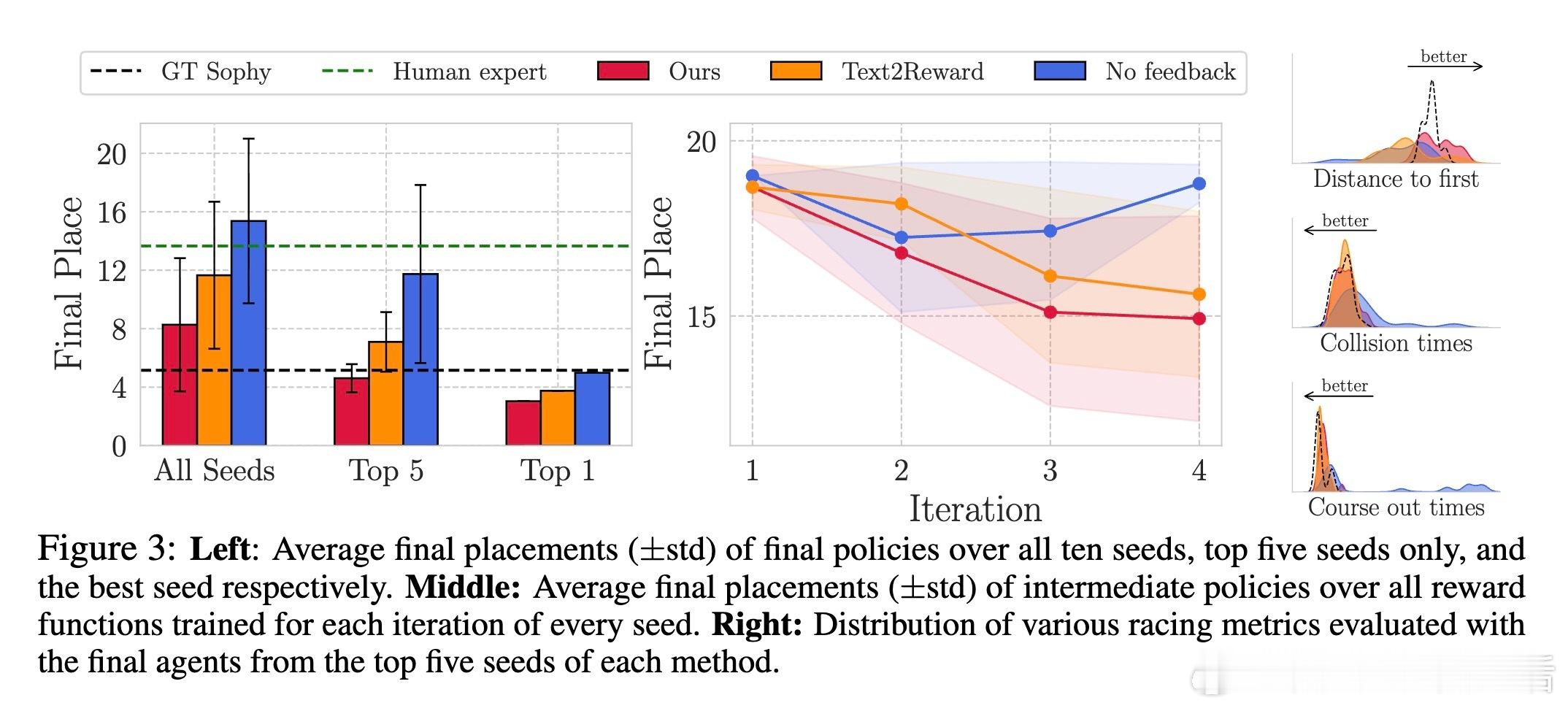
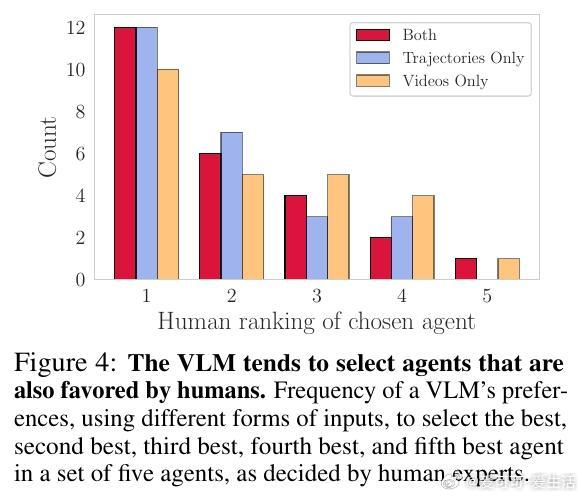
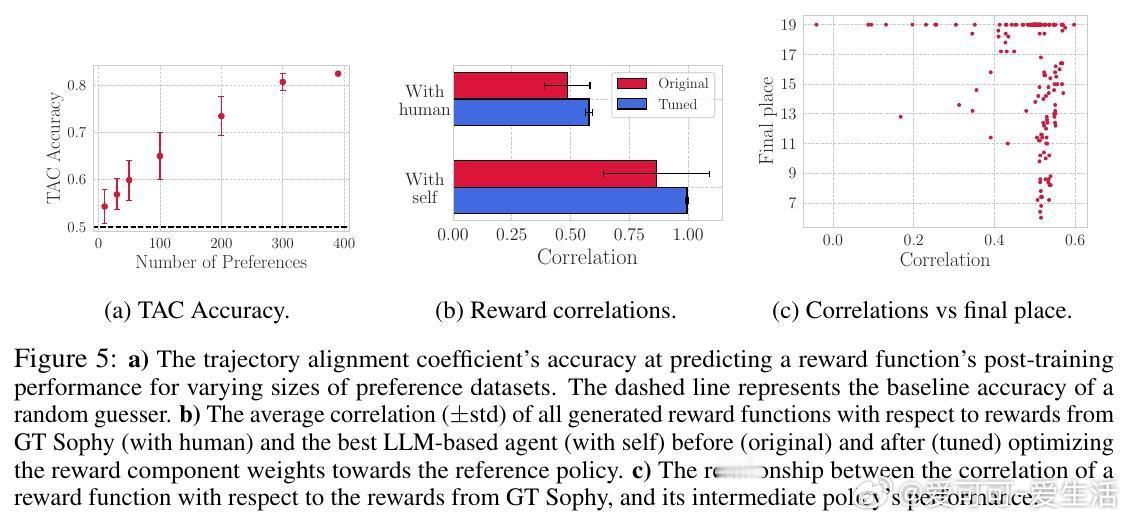
实验中,自动生成的奖励函数训练出的智能体不仅在比赛中表现出色,部分场次甚至超越了由人类专家和GT Sophy(现有顶级强化学习赛车智能体)设计的奖励函数训练的智能体。此外,视觉语言模型在偏好选择中的表现接近人类专家,证明了其作为自动化评估工具的可行性。系统还成功生成了诸如“始终倒车极速比赛”及“尽量漂移比赛”等前所未有的赛车行为,展示了文本到奖励设计的巨大潜力。
尽管自动奖励设计计算开销较大,且仍需少量人工介入以确保稳定性,但该研究为复杂环境下自动化强化学习奖励设计开辟了新路径。未来,进一步优化奖励权重调节和扩展至更广泛的任务环境,将推动强化学习从“算法竞赛”迈向更实用的工业和游戏应用。
详细论文见 arxiv.org/abs/2511.02094