[LG]《Re-FORC: Adaptive Reward Prediction for Efficient Chain-of-Thought Reasoning》R Zabounidis, A Golatkar, M Kleinman, A Achille... [AWS Agentic AI] (2025)
你是否遇到过这样的问题:大型语言模型(LLM)在推理时,怎么才能动态地决定“思考”多久才够用?“多想几步”是提升准确率的捷径,但计算资源有限,盲目增加推理长度往往得不偿失。AWS Agentic AI团队的研究员们带来了Re-FORC,一种革新性的适应性奖励预测方法,帮助模型聪明地分配推理计算,提升效率和准确率。
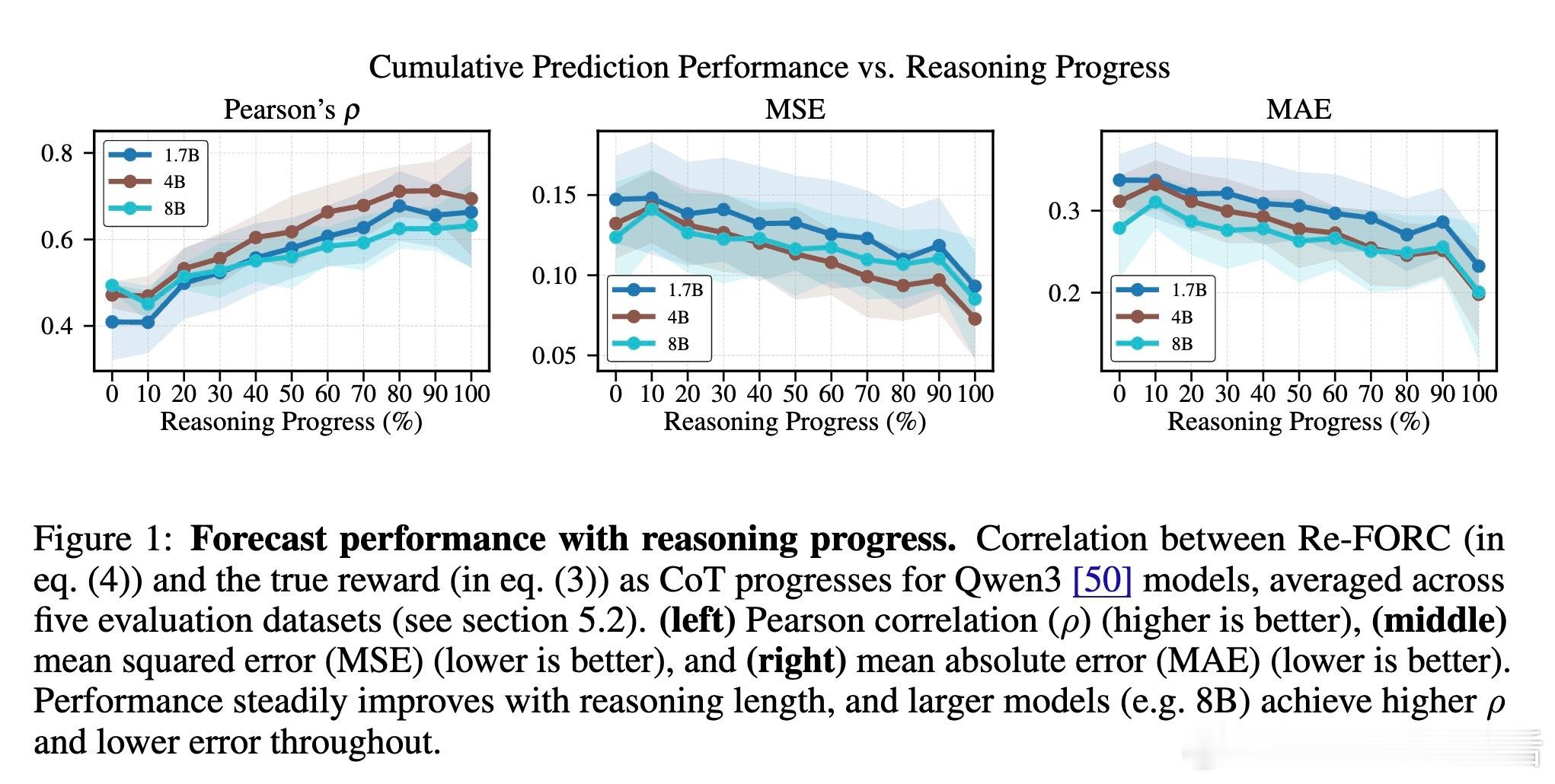
主角是Re-FORC:它不仅预测当前推理状态下,继续生成多少思考token能带来多大收益,还能据此决定是否早停、选择哪个模型更合适,以及如何动态调整推理长度。它通过训练一个轻量级的适配器,附加在已有的推理模型上,实时输出“未来奖励-计算成本”曲线,类似于为推理过程装上了智能的“预判仪”。
反派则是传统推理模式:它们缺乏对推理收益的前瞻性认识,导致计算资源浪费,或因无法灵活调整推理长度和模型大小,错失提升准确率的良机。更严重的是,不同用户场景对延迟和准确率的需求千差万别,难以用单一策略满足。
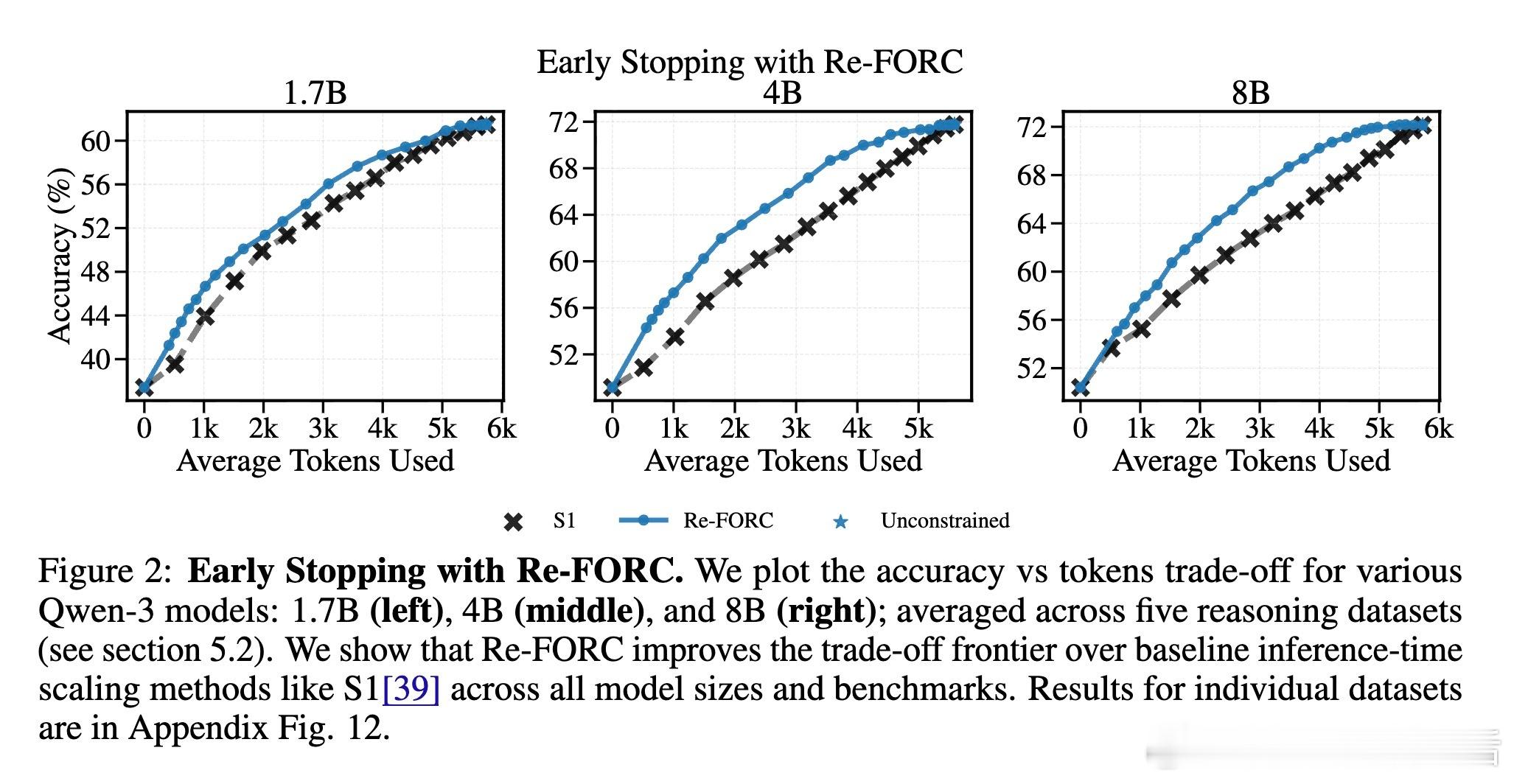
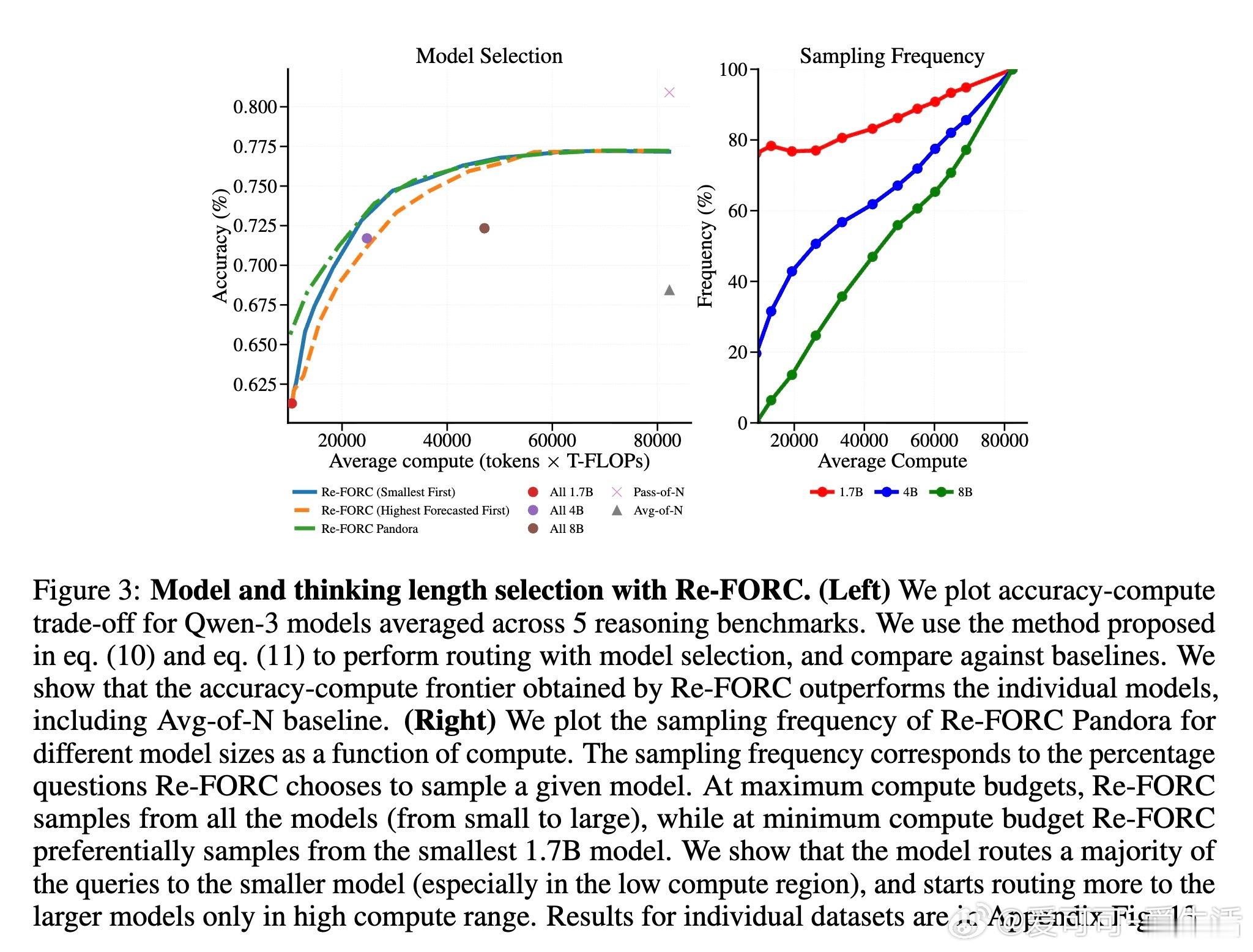
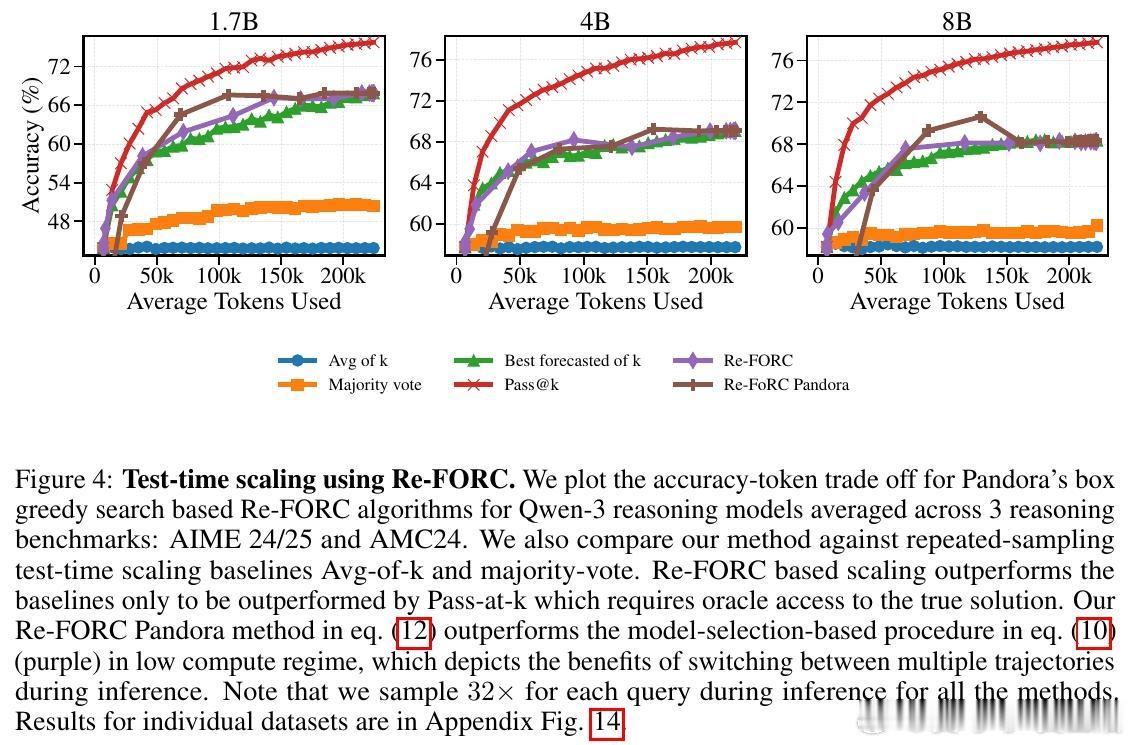
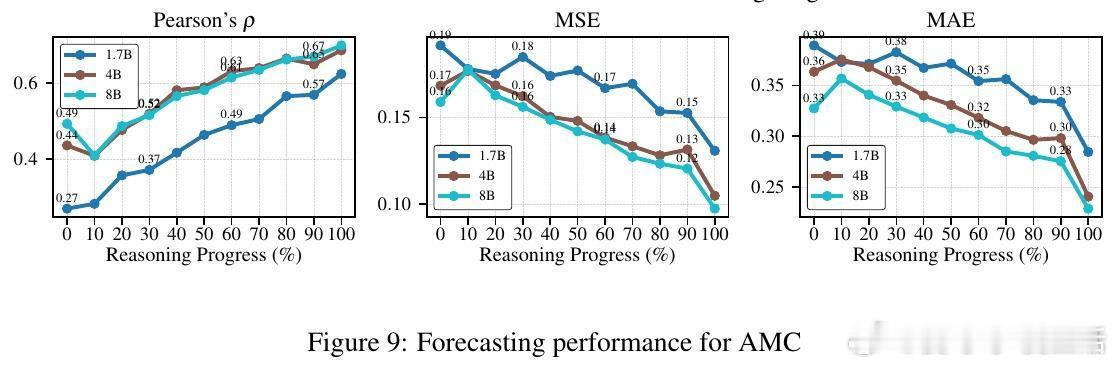
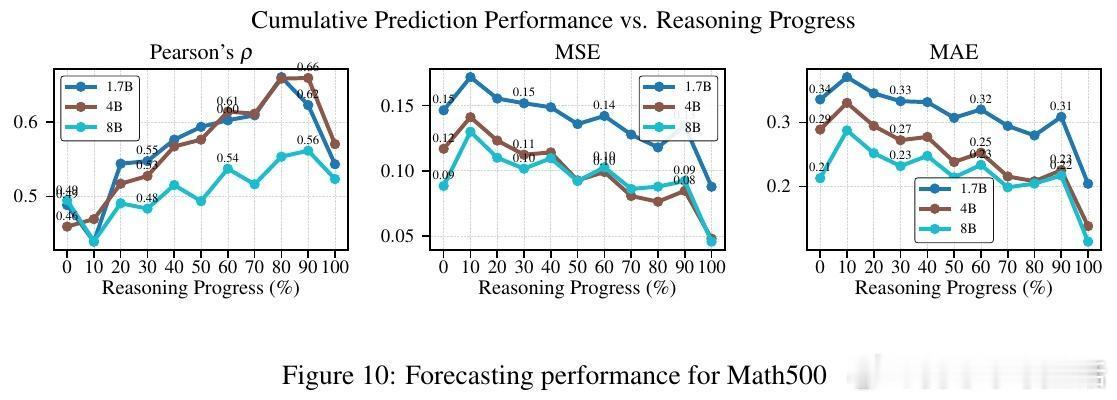
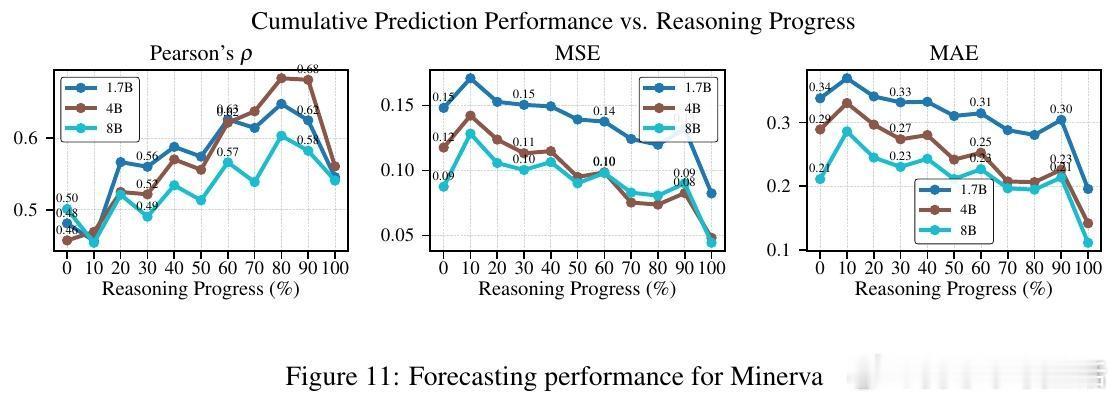
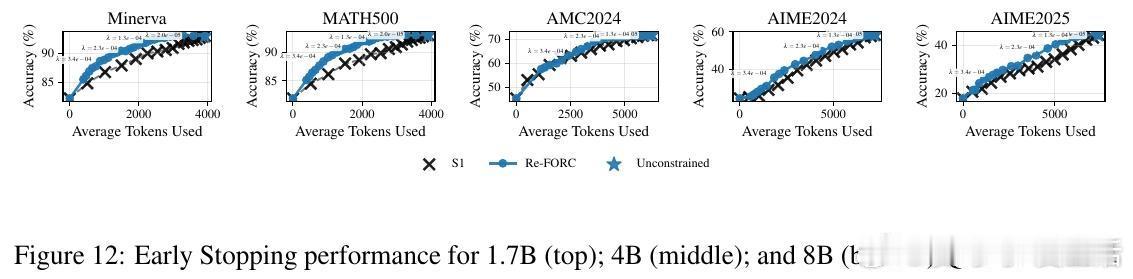
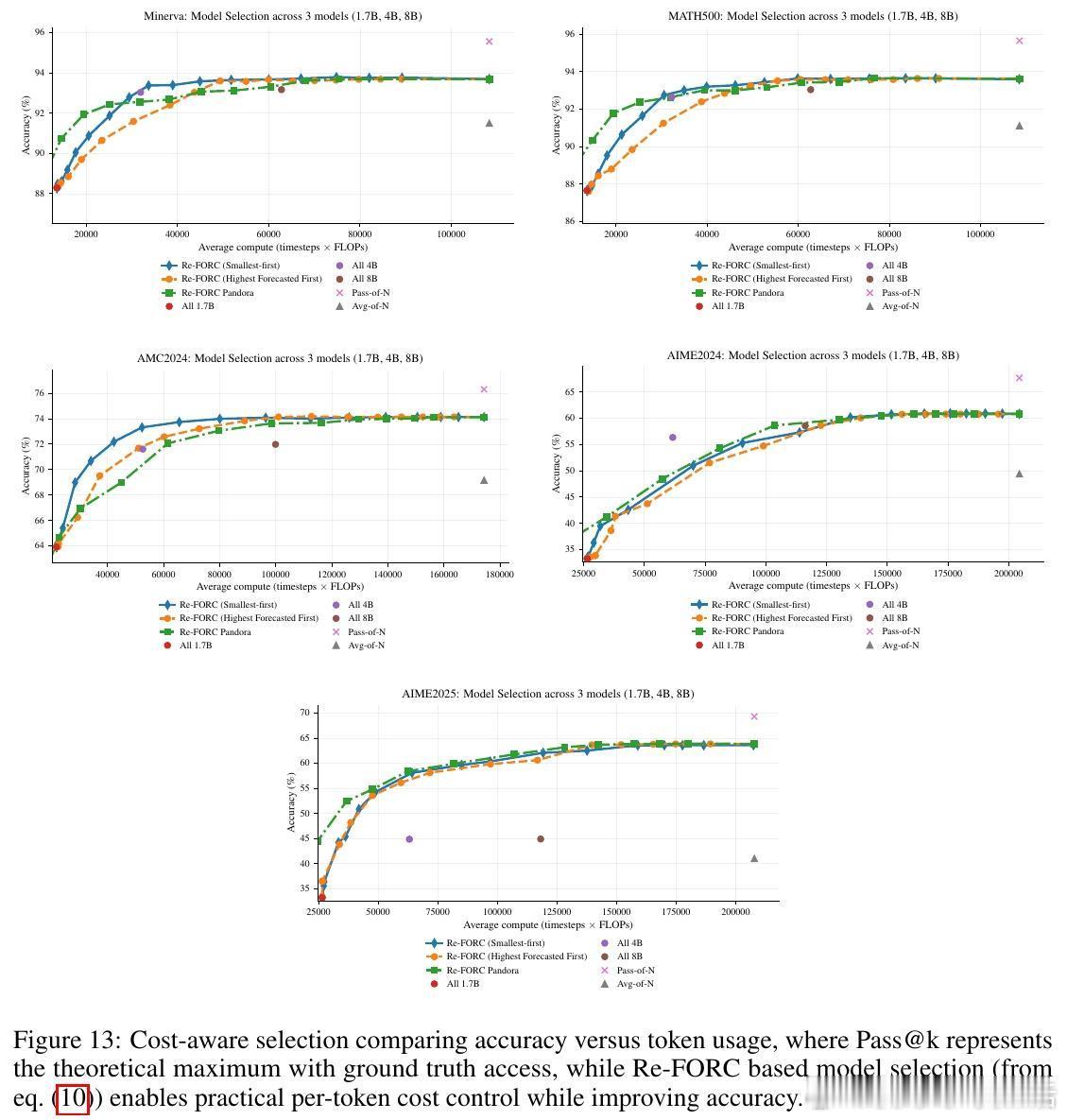
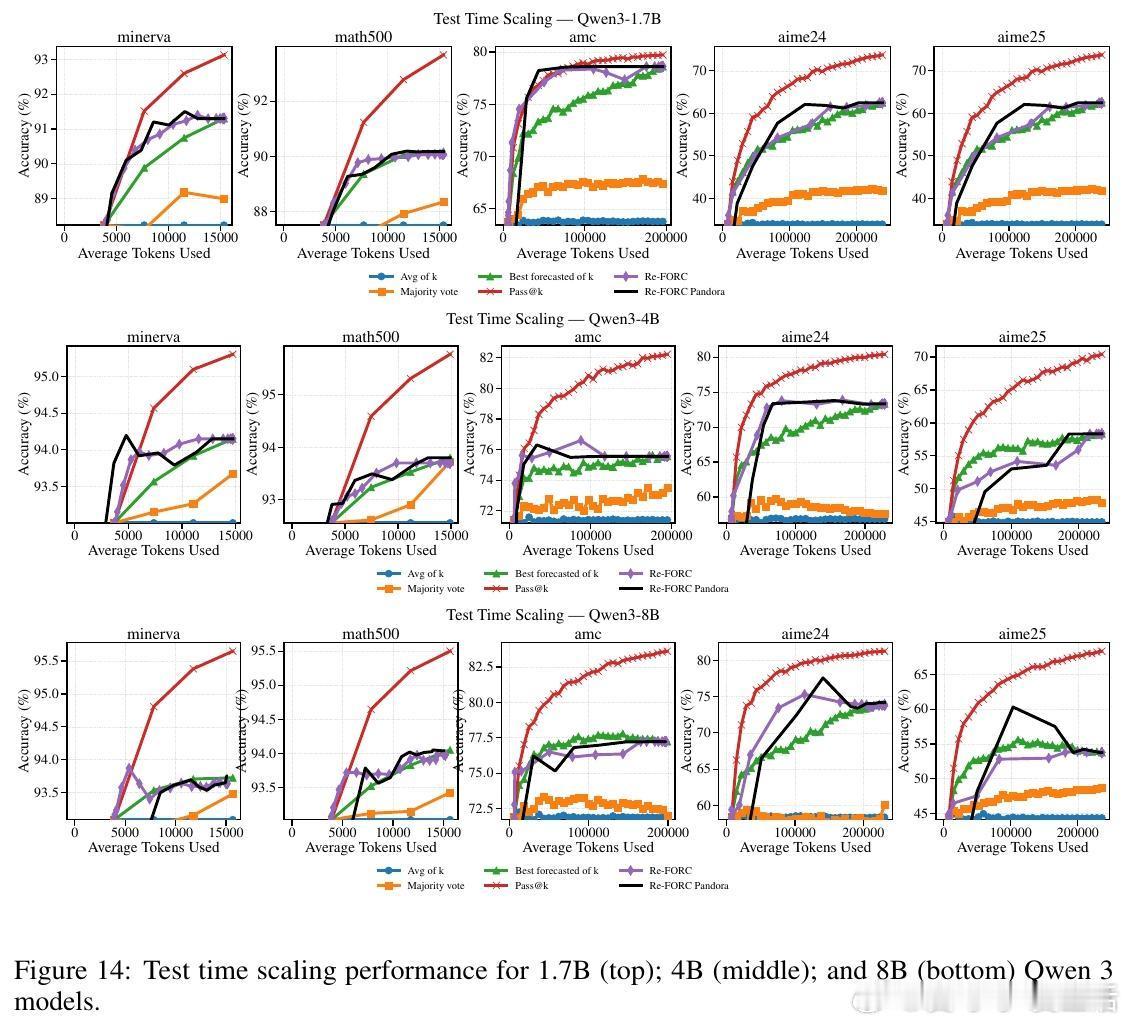
高潮爆发在Re-FORC利用“潘多拉盒子问题”的贪婪搜索算法(Pandora’s Box Greedy Search)上,这是一种基于Gittins指数的决策框架,帮助快速判断是否继续推理或切换模型。实验证明,Re-FORC能在保持准确率的同时,减少26%的计算量;在同等计算预算下,准确率提升4%;或者在保证准确率的前提下,节省55%的计算资源。
结局令人振奋:用户在推理时,只需设定自己对成本和准确率的偏好,Re-FORC自动动态调整推理策略,实现个性化、经济高效的智能推理。不仅如此,Re-FORC还能给出推理预估时间,极大改善了用户体验。
这项工作打破了“一刀切”的推理思路,开启了计算资源利用的新时代。未来,随着对奖励预测模型的进一步优化和校准,Re-FORC有望成为各种复杂任务推理的标准配备。它让“该停就停,该换就换”的智能推理成为可能,真正把大模型的潜能发挥到极致。
详细内容请见:arxiv.org/abs/2511.02130