[LG]《Unlocking the Power of Multi-Agent LLM for Reasoning: From Lazy Agents to Deliberation》Z Zhang, X Li, Y Lin, H Liu... [The Pennsylvania State University & Harvard University & Michigan State University] (2025)
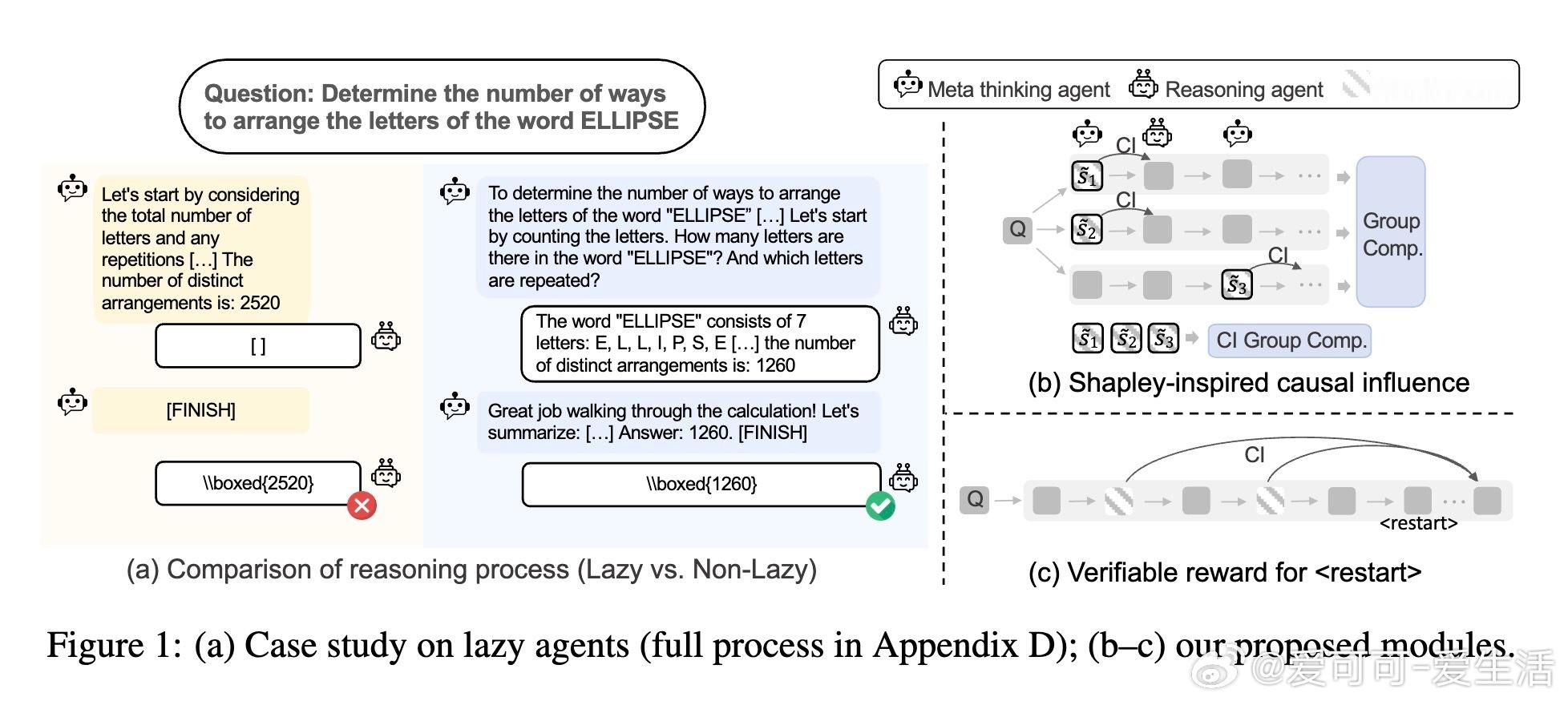
在多智能体大语言模型(LLM)推理框架中,懒惰代理现象严重制约协作效果——一个代理主导决策,另一个几乎无所作为,导致系统退化为单智能体。本文由宾州州立大学等团队提出了Dr. MAMR方法,精准分析了这一问题的根源,提出了创新解决方案。
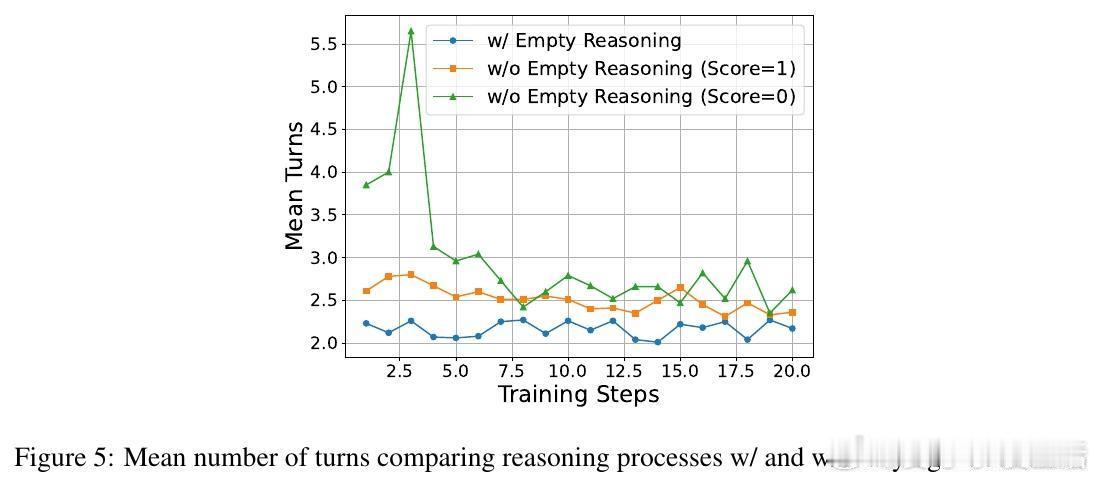
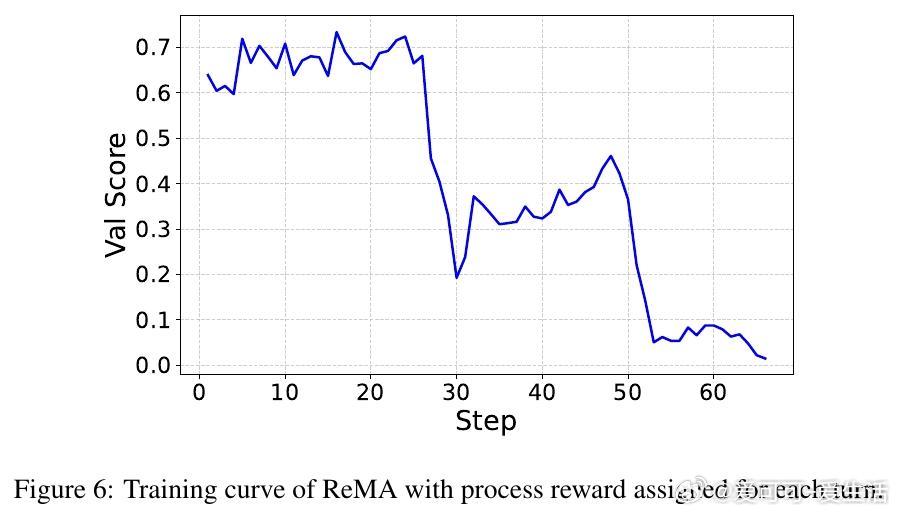
故事主角是“多智能体推理系统”,其对手是“多轮强化学习中隐含的归一化偏差”,这股势力导致模型偏好少交互步骤的“捷径”,促成懒惰行为。作者的理论突破在于揭示:多轮GRPO算法中的归一化项无意中鼓励最少交互回合,从而使代理倾向于省略深入思考和协作。
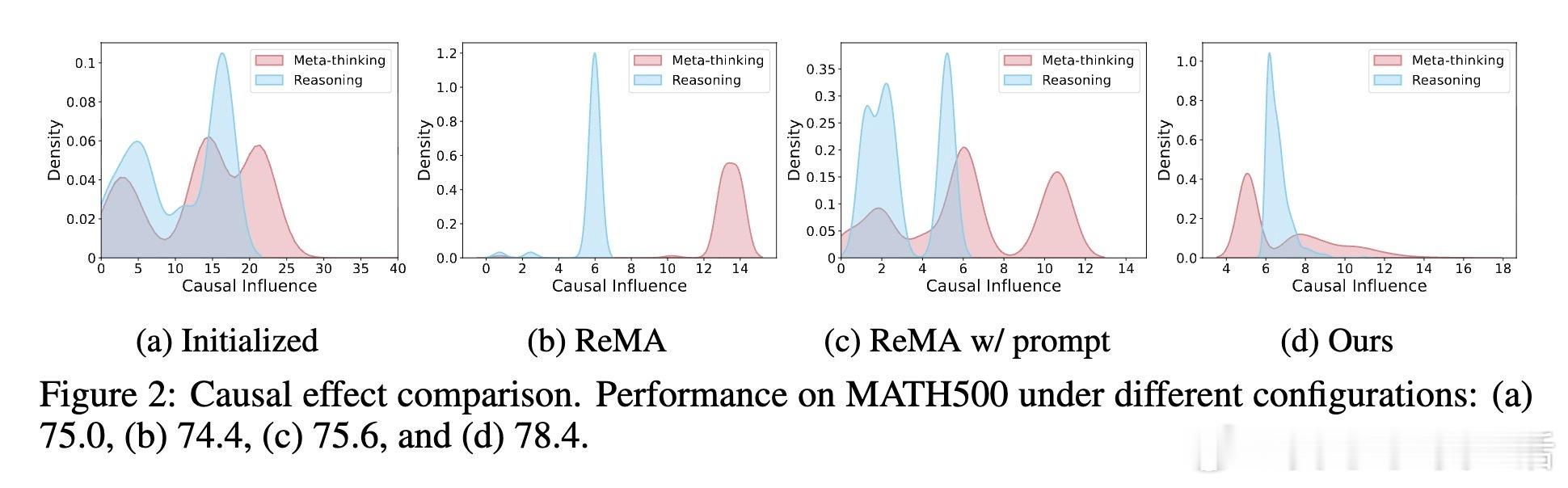
高潮在于他们引入了Shapley值启发的因果影响度量方法,通过聚合语义相似步骤对推理贡献的平均评估,克服了单一路径评估的偏差和表述变异;同时,设计了可验证的重启奖励机制,允许推理代理在中途丢弃噪声步骤、重新整合指令并重启推理,防止陷入错误循环。
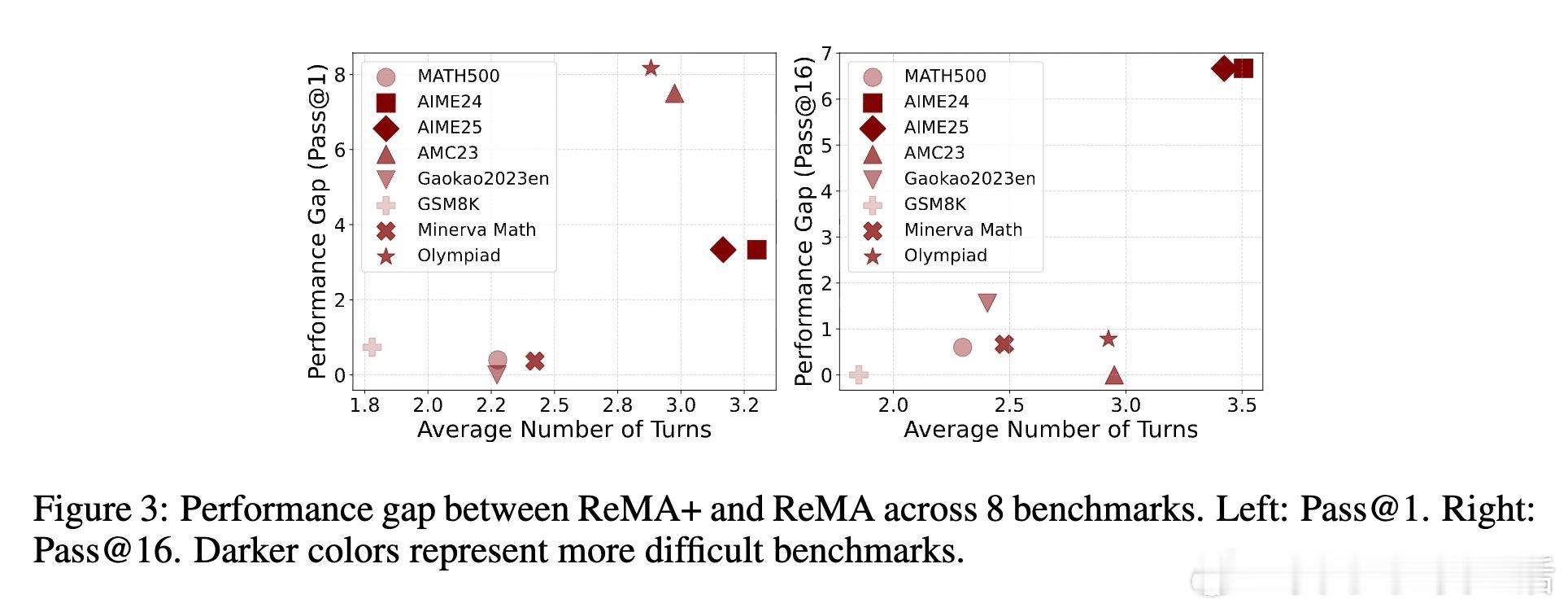
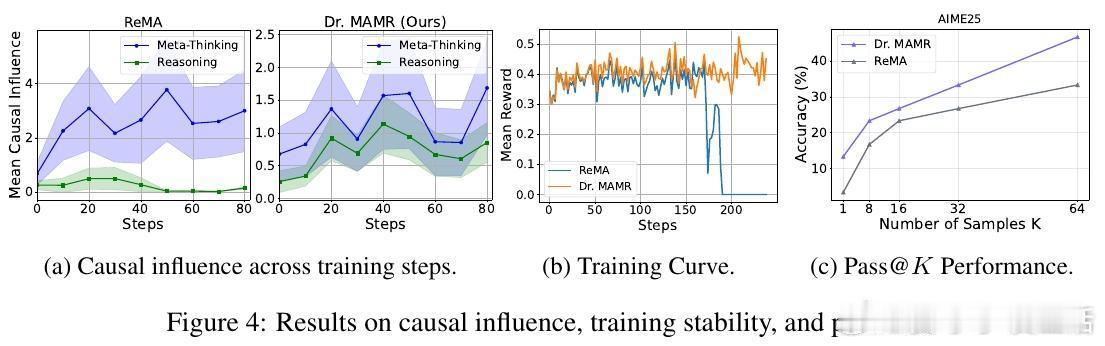
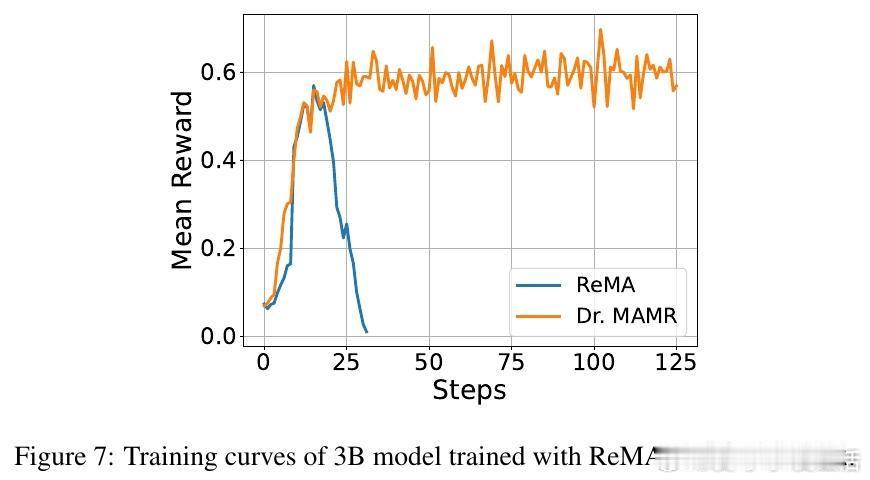
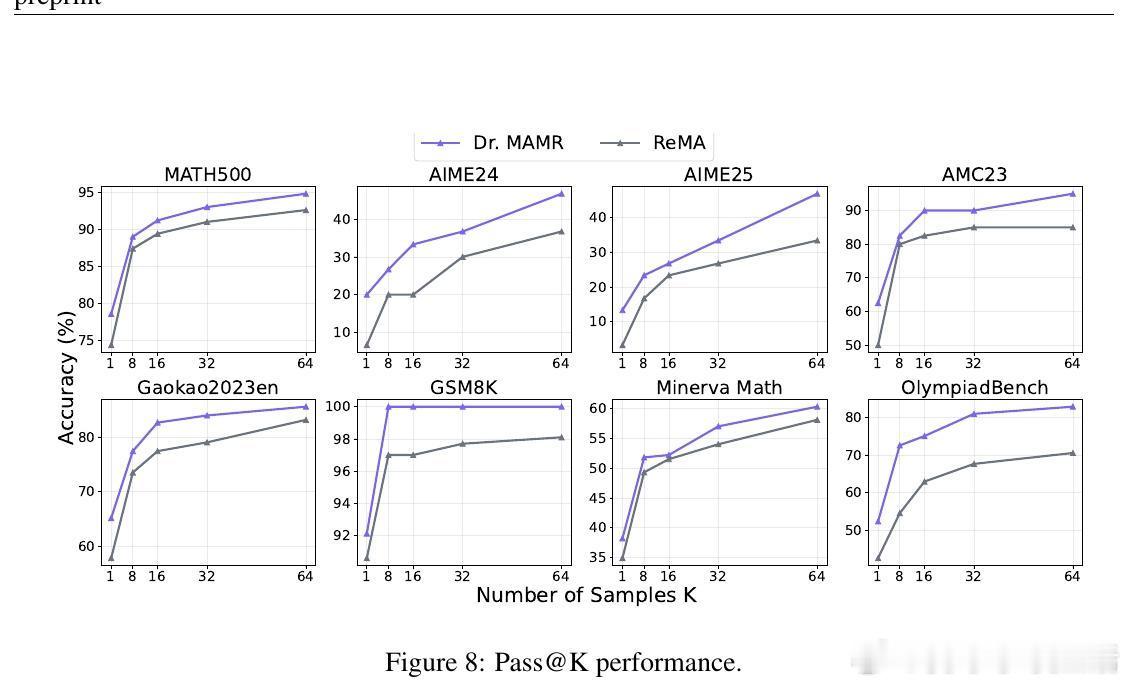
实验证明,Dr. MAMR有效缓解了懒惰代理问题,促进元思考和推理代理均衡贡献,提升多智能体系统在数学推理等复杂任务上的表现。与ReMA等现有框架相比,Dr. MAMR在七大基准测试中均取得显著领先,且在模型规模增大和多样化采样(pass
这一研究不仅揭示了多智能体推理训练中深层次的优化陷阱,也为设计更稳健的多轮多智能体强化学习目标提供了理论与实践指导。它告诉我们:协作系统要想发挥最大潜力,必须认清并纠正潜在的奖励结构偏差,激励每个代理积极参与、持续反思与调整。否则,“懒惰”将吞噬合作的力量。
详情请见:arxiv.org/abs/2511.02303