[LG]《From Models to Operators: Rethinking Autoscaling Granularity for Large Generative Models》X Cui, C M Liang, J Xing, H Qiu [Rice University & Microsoft Research] (2025)
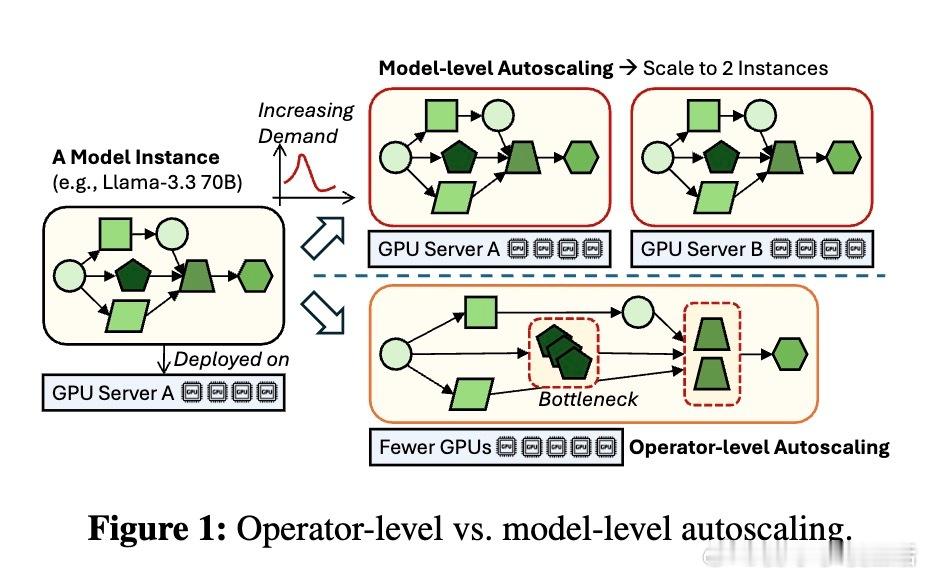
在大规模生成模型推理中,传统的模型级别自动扩缩存在资源浪费和响应迟缓的矛盾。本文提出了全新的“算子级自动扩缩”框架,突破了以往将整个模型作为单一扩缩单元的局限。
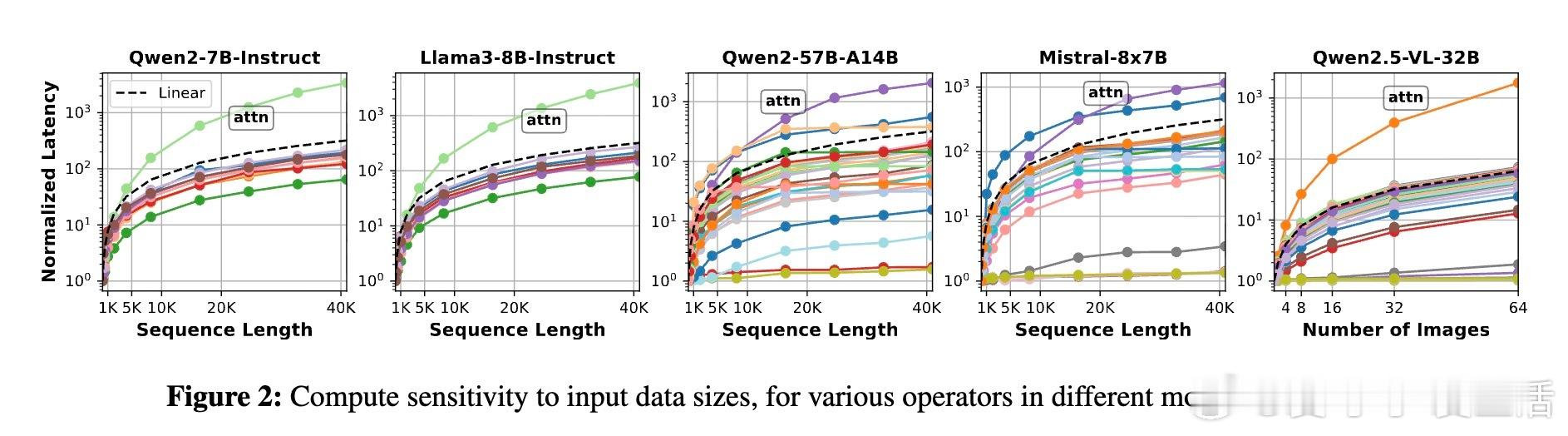
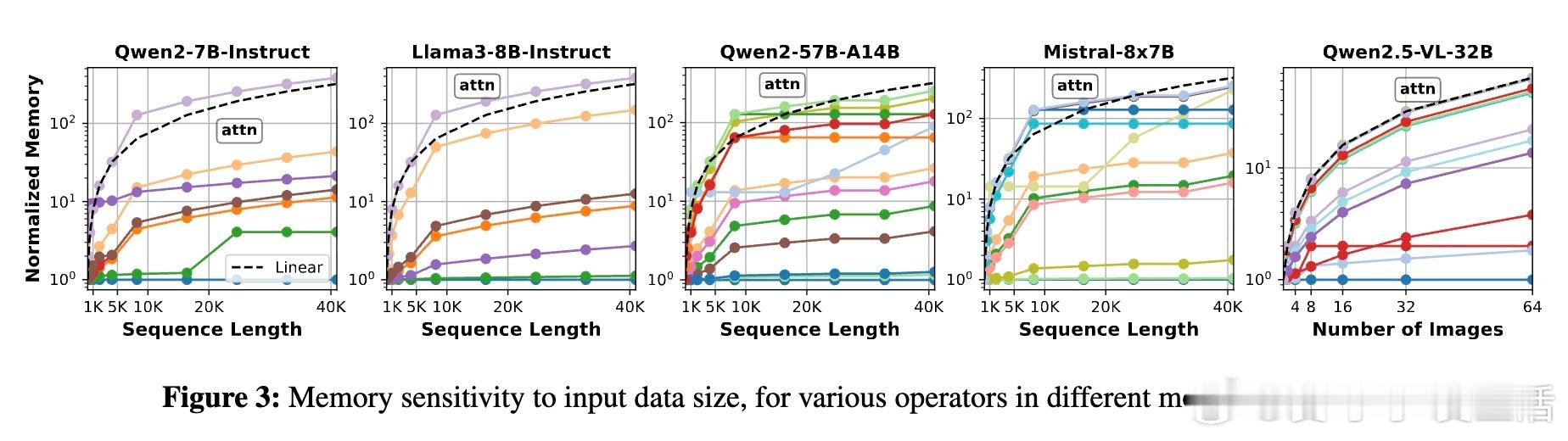
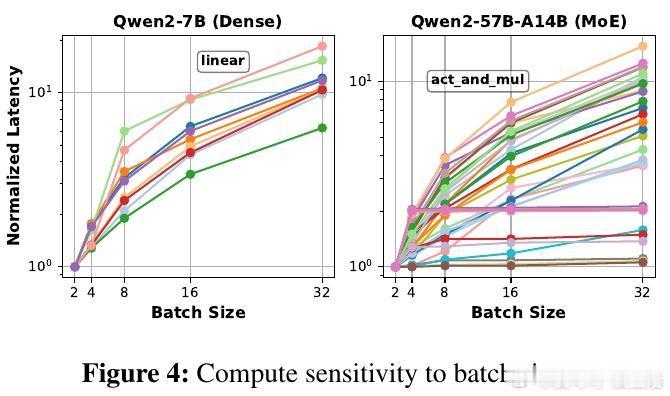
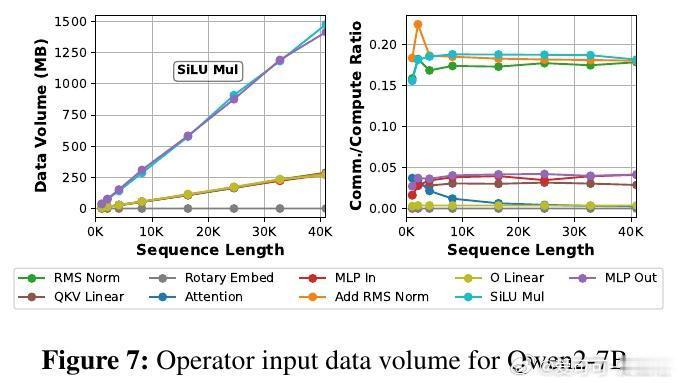
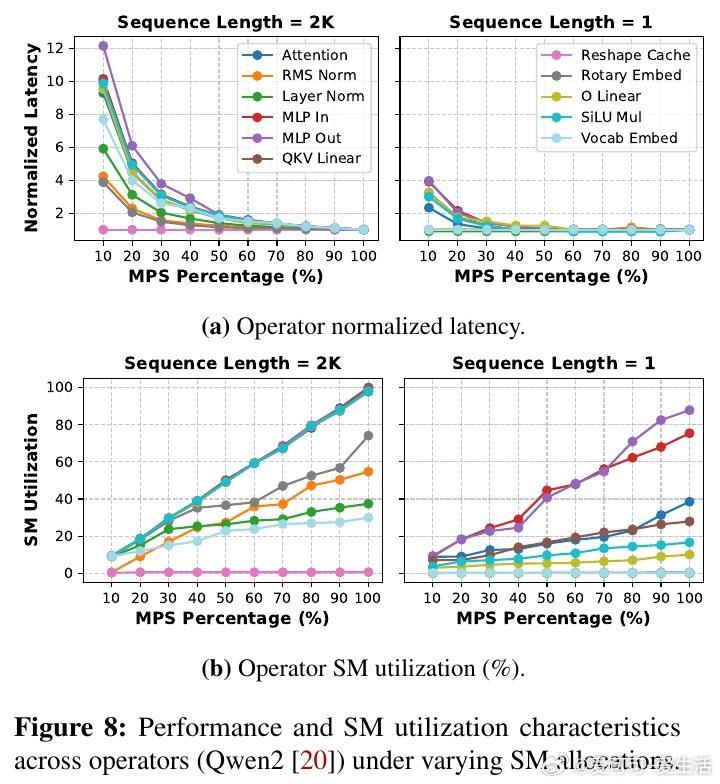
主人公是这些算子——注意力、线性变换、归一化等组成模型的基本单元。研究发现,算子在计算量、内存占用和对批大小、序列长度等因素的敏感度上存在巨大差异。传统模型级扩缩的“单块石头”策略,忽视了这种异质性,导致非瓶颈算子资源浪费和扩缩延迟长达数秒,难以应对在线推理中动态变化的请求流量。
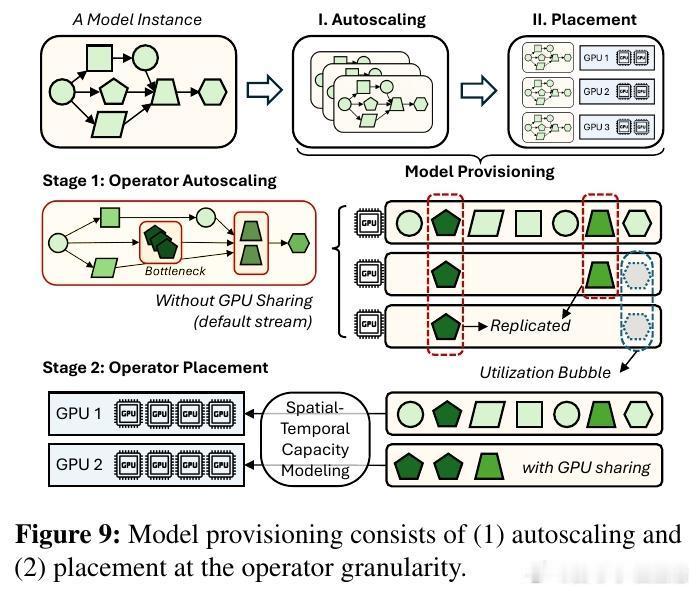
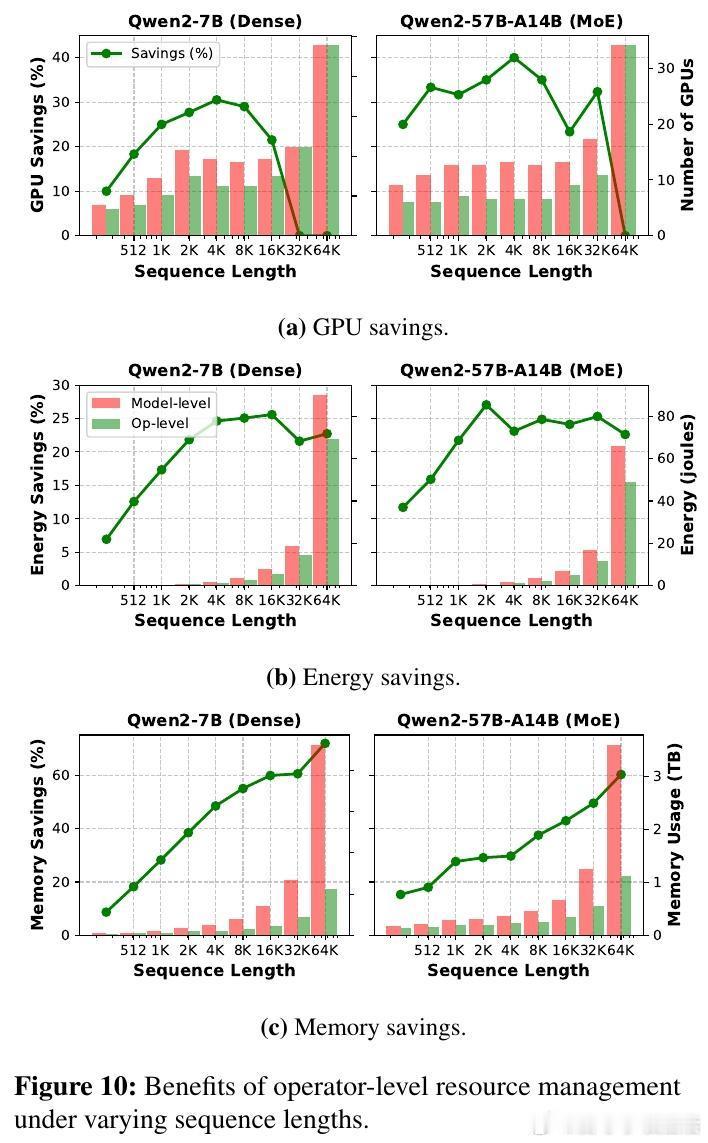
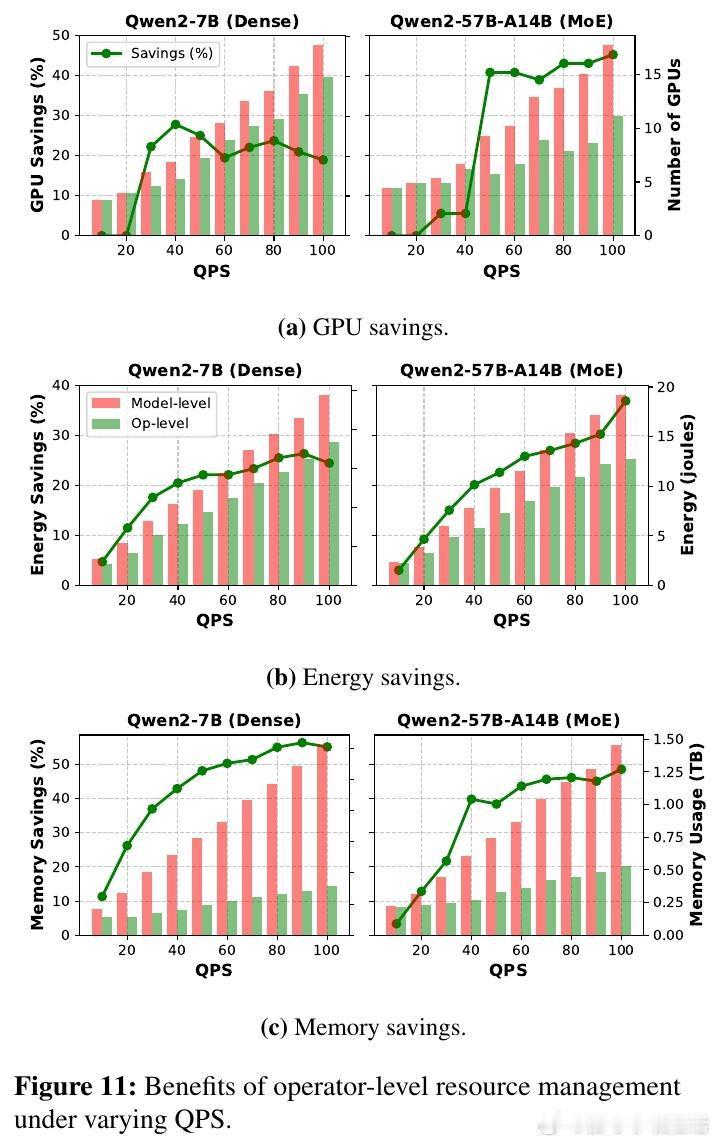
研究的高潮在于提出了基于算子细粒度的扩缩与调度策略:针对每个算子独立调整复制数和并行度,结合排队理论动态预测延迟瓶颈,采用争用感知的算子共置减少通信和资源争用。该方法大幅降低GPU数量和能耗,节省达40% GPU资源,35%能量消耗,且在固定资源下提升1.6倍吞吐量,保持SLO指标不变。
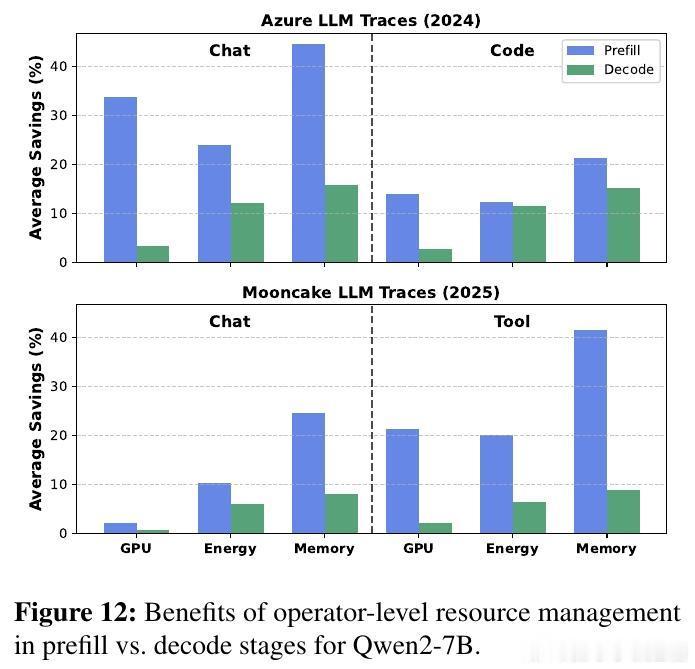
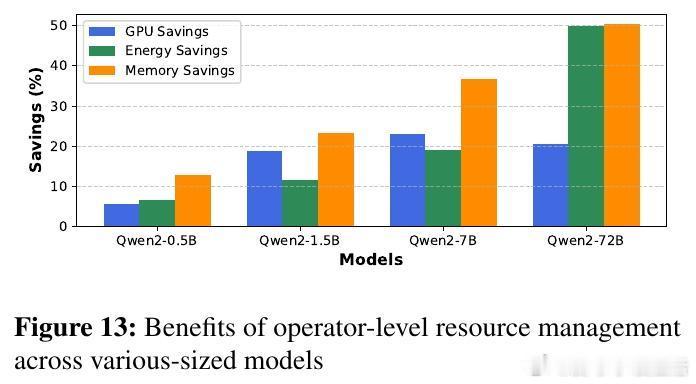
有趣的是,预填充阶段(长序列、计算密集)从算子级扩缩获益最大,节省资源高达2-3倍于解码阶段(短序列、内存密集)。此外,模型越大,算子级扩缩的优势越明显,最高可节省一半以上的能耗和内存。研究还指出,算子级扩缩极大缩短了弹性响应时间,从传统模式的秒级缩短到子秒级,极大提升了在线服务的灵活性。
这揭示了一个讽刺:把模型当“黑盒”整体扩缩,反而成了效率的敌人。算子级视角让我们重新认识大型生成模型推理系统的资源管理,开启了更加智能、细腻的弹性调度新篇章。未来,结合持续负载监测和调度优化,算子级自动扩缩将成为云端大模型推理的基石。
全文详见:arxiv.org/abs/2511.02248