【从DeepSeek的星号到百度的YY,这条线越来越清晰】
去年AI圈有一个细节,很多人注意到了但没深挖。DeepSeek-V4那篇58页技术报告末尾,近三百人的作者名单里,有10个名字旁边带着星号,标注已离职。半年不到走了五个人,这些人去了哪,圈内一直没有明确说法。
直到百度最近发布Unlimited OCR,一些线头开始对上。
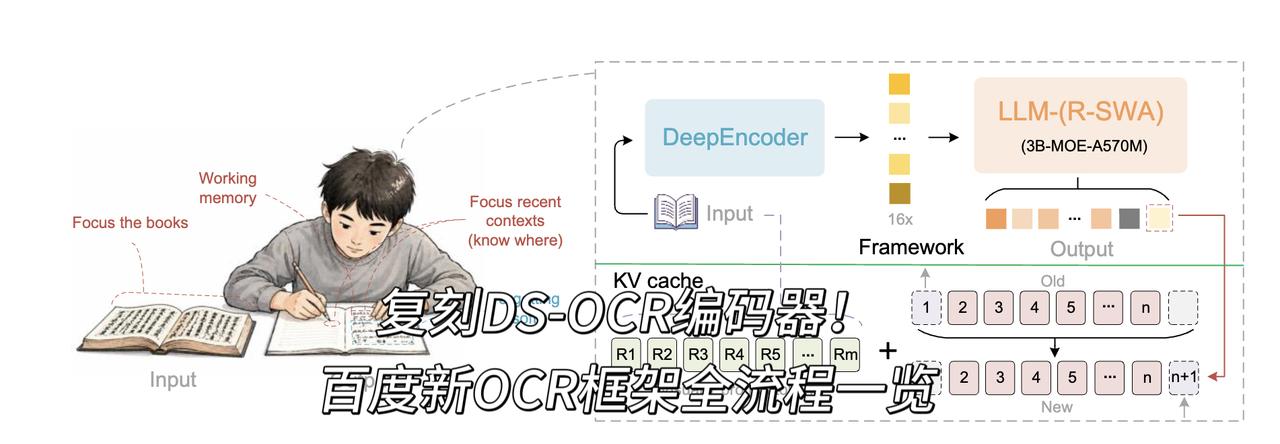
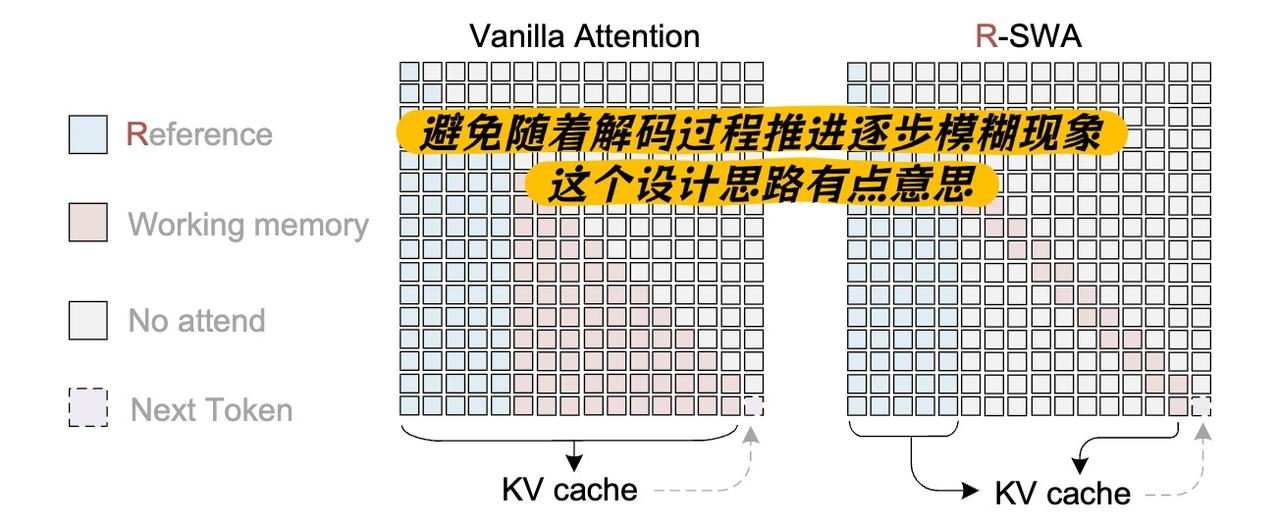
先说模型本身,技术确实有亮点。一次推理转录几十页文档,灵感来自人类抄书的“软遗忘”——不把前面全记住,只盯着最近写的一小部分确认没串行。百度把这套逻辑做成了参考滑动窗口注意力R-SWA机制,KV Cache恒定,32K上下文一次性搞定长文档。思路不卷参数,从认知规律出发,这个方向本身就很值得聊。
但让这篇论文变得更耐人寻味的是作者栏。三个核心贡献者,两人实名,技术总监留的是“YY”。大厂技术报告挂缩写,这个操作本身就非常规。更值得玩味的是致谢部分,GitHub上排在最前面的,赫然是DeepSeek-OCR和DeepSeek-OCR-2,致谢顺序在这个圈子里往往暗示着真实的技术渊源。
还有行文风格。这篇报告的叙事结构——先讲人类怎么抄书、怎么维持连续认知状态,再提出机制,最后落地模型,故事性强、不堆参数——跟DeepSeek的技术报告重合度相当高。文中提到DeepEncoder的部分,语气也不太像在引用别人的工作。
国内能做R-SWA这种级别创新,同时对DeepSeek那条OCR产品线的架构细节有深度把控能力的人,数来数去就那么多。去年带星号的那几位,具体去向一直没有公开。
百度这篇论文像是在作者栏里放了一个坐标。那个坐标指向谁,圈内应该很快就有答案了。
百度 文心 文心大模型 deepseekOCR AI大模型 Ai 科技