[CL]《EpiCache: Episodic KV Cache Management for Long Conversational Question Answering》M Kim, A Kundu, H Kim, R Dixit... [Apple] (2025)
EPICACHE:突破长对话问答中的KV缓存瓶颈,实现资源受限环境下的高效记忆管理
• 解决LLM对话上下文中KV缓存线性增长导致的内存瓶颈,特别适合数万至十万级tokens长对话。
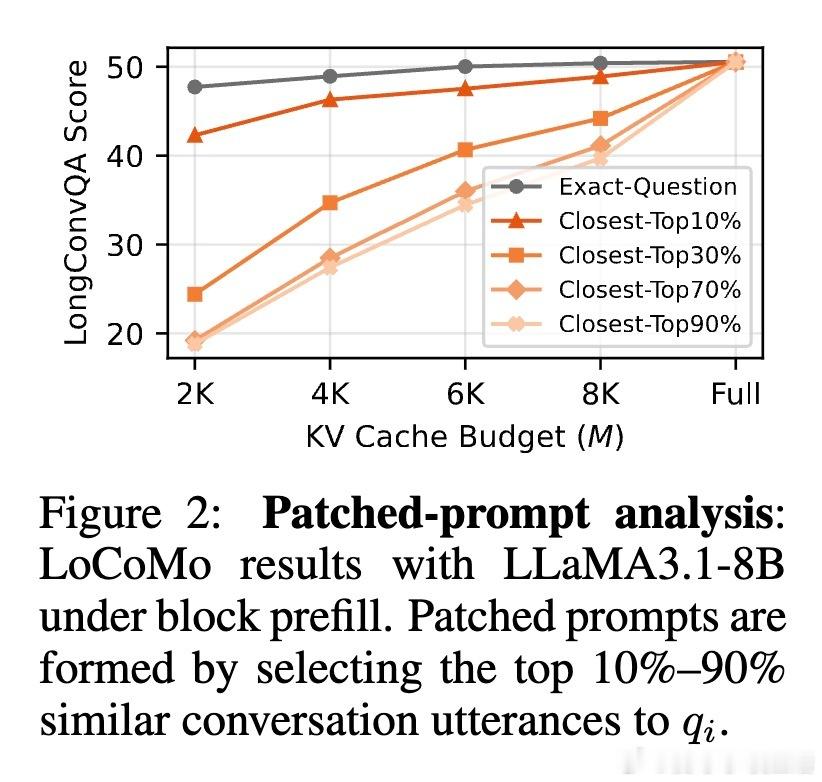
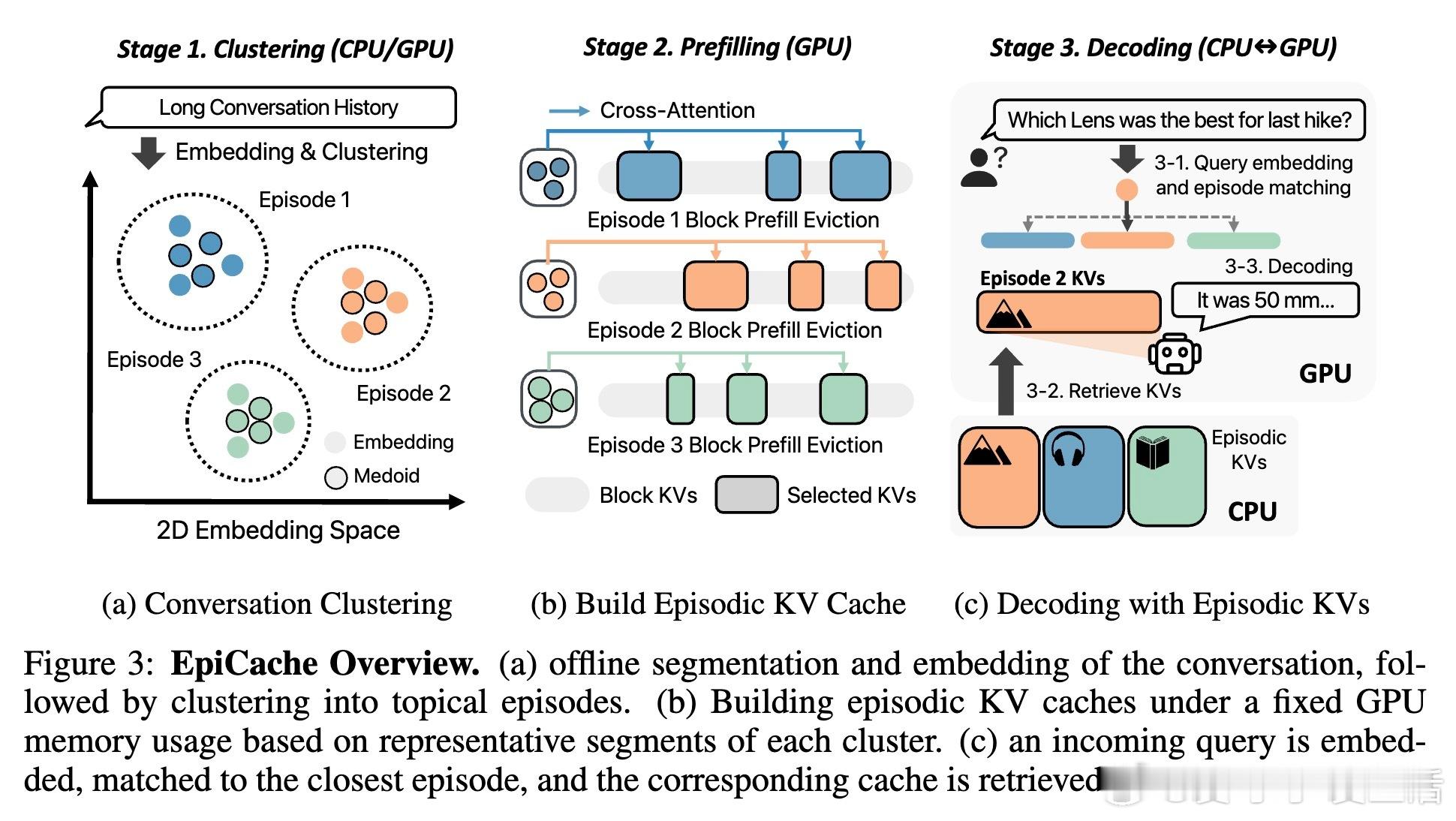
• 创新采用基于语义聚类的“情节(Episodic)KV缓存压缩”,将对话分割为主题连贯的多个情节,针对每个情节构建独立缓存,精准保留话题相关内容。
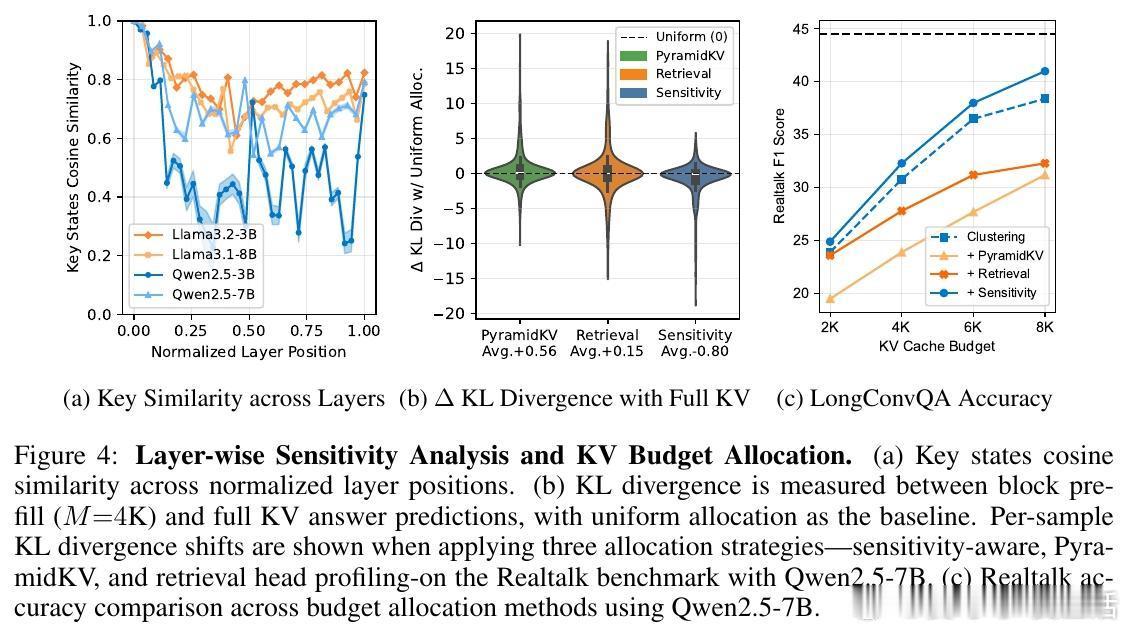
• 引入分层敏感度自适应内存分配,依据Transformer各层对缓存丢弃的敏感度差异,动态调整缓存预算分配,有效提升多轮问答准确率。
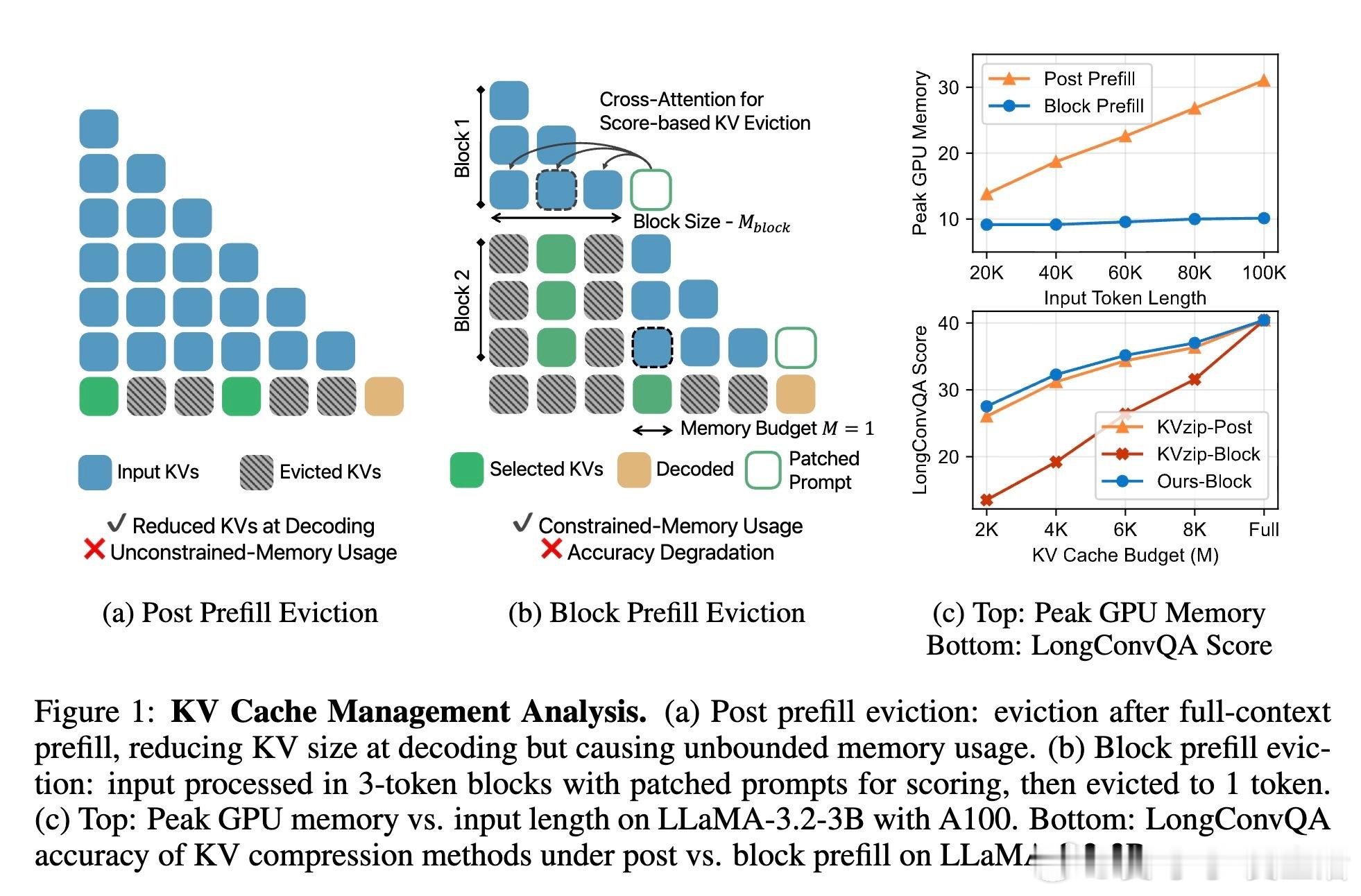
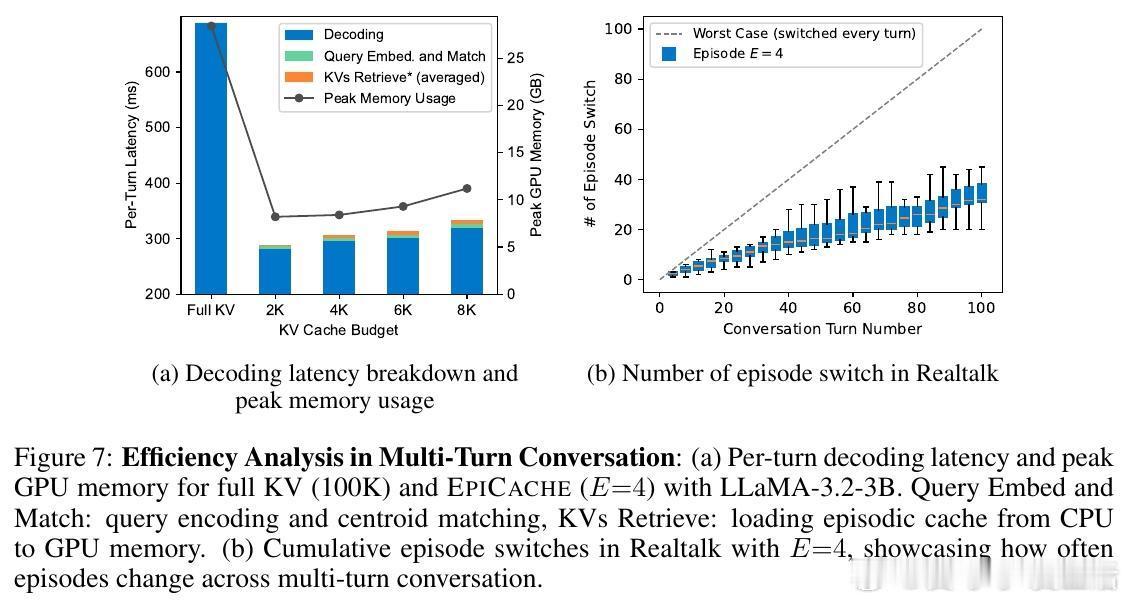
• 采用块式预填充(Block Prefill)策略,边加载边压缩,避免传统后填充(Post Prefill)导致的峰值内存无限制增长,内存使用和延迟均大幅下降(峰值内存减少3.5倍,解码延迟降低2.4倍)。
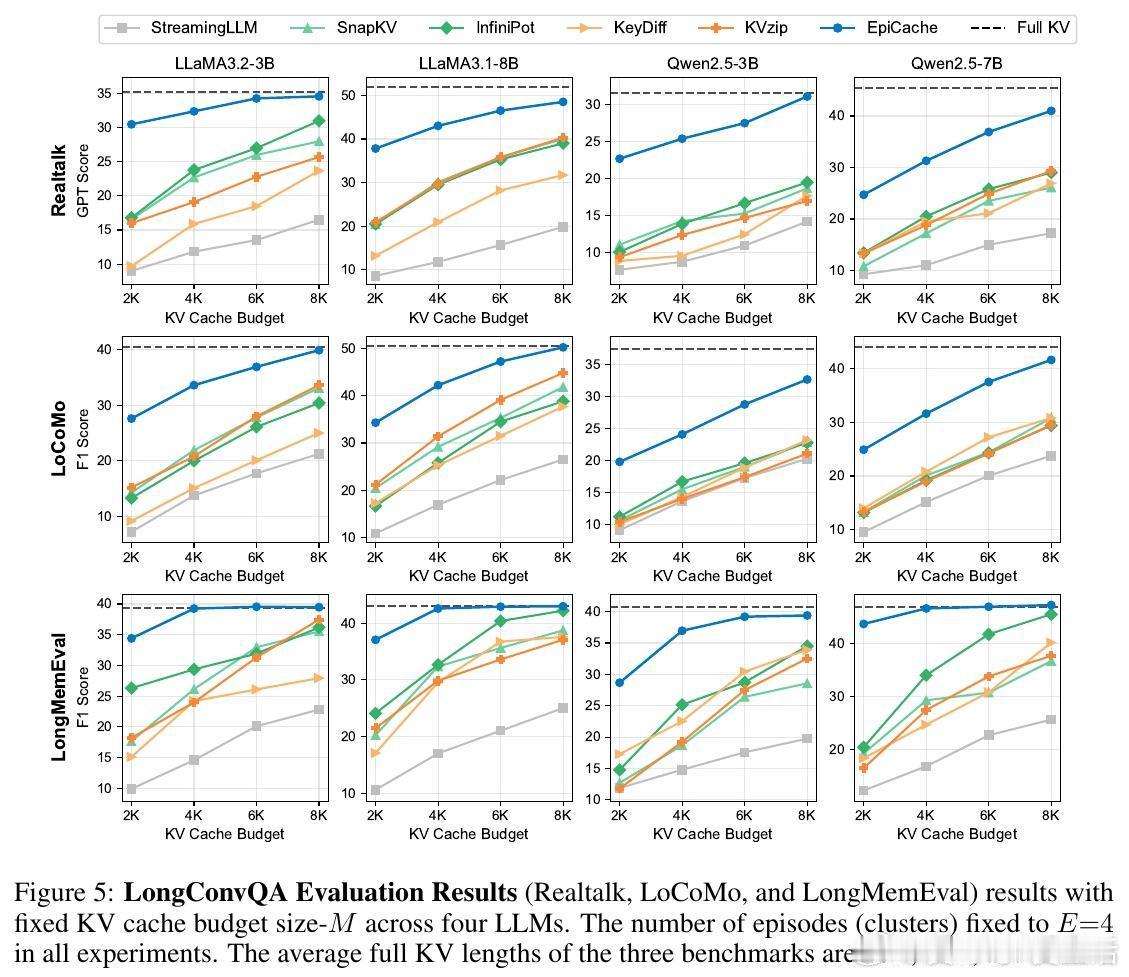
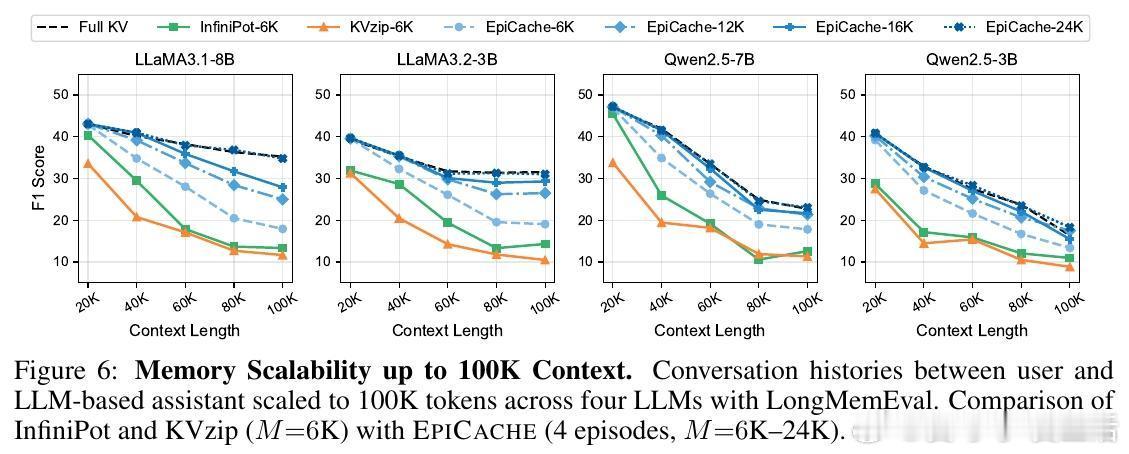
• 在三大长对话问答基准(Realtalk、LoCoMo、LongMemEval)及多款开源LLM(LLaMA3、Qwen2.5)上,压缩4-6倍KV缓存仍保持接近完整KV性能,准确率提升最高达40%。
• 设计轻量级离线聚类和在线检索机制,查询可快速匹配相关情节缓存,查询切换频率低,检索开销仅占整体延迟5%以内。
• 详尽消融实验验证块大小、聚类窗口、聚类数量、编码器选择对性能的影响,证明系统对参数选择表现鲁棒。
心得:
1. 对话历史的语义结构是压缩缓存的关键,简单基于时间或固定窗口的策略难以兼顾上下文完整性和内存限制。
2. Transformer不同层对丢弃信息的敏感度差异显著,合理分配缓存资源能显著提升多轮对话的上下文利用效率。
3. 块式预填充避免了传统方法预填充后才压缩带来的峰值内存爆炸问题,表明“边处理边压缩”是长上下文管理的必经之路。
EPICACHE为实现大规模长对话系统的内存高效管理提供了切实可行的路径,兼顾性能与资源限制,推动对话式AI向更长、更连贯的交互迈进。
详情阅读👉 arxiv.org/abs/2509.17396
人工智能大语言模型长对话管理KV缓存模型压缩自然语言处理